Exploiting Local and Global Structure for PointCloud Semantic Segmentation with Contextual Point Representations
期刊:Nips2019
时间:2019
code:https://github.com/fly519/ELGS
目录
1、创新
针对PointNet2的三个问题
- 初始特征表示只是局限于xyz rgb i 等低层次的特征,没有综合点的邻域信息
- sampling+grouping后对于local pointcloud,使用的是对每一个点孤立地提取特征,唯一的特征聚合是在最后使用一次max函数,这样没有考虑group内部点之间的影响。
- 没有利用采样点与点之间的全局关系
作者对应地提出三个模块
Point Enrichment:对每个点的初始feature进行增强Feature Representation:在grouping后的每一个小点云,使用一种attention机制,将每个点的特征更新为邻域内所有点特征的加权和Prediction:对decoder后的点云,分别使用spatial attention 和 channel attention更新特征,这样就认为每个点携带了全局信息(无论两个点距离多远)
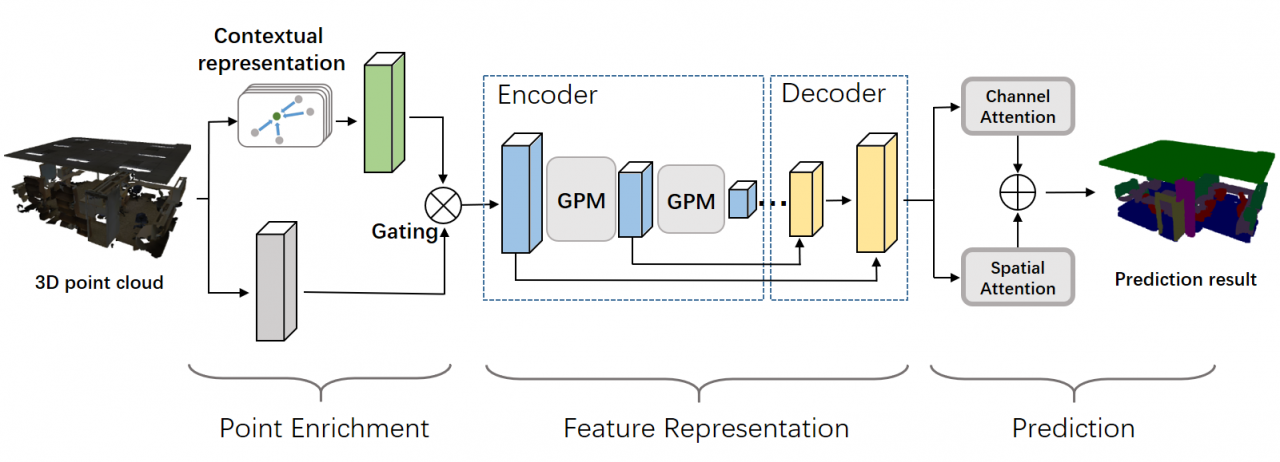
2、具体实现
2.1 Point Enrichment
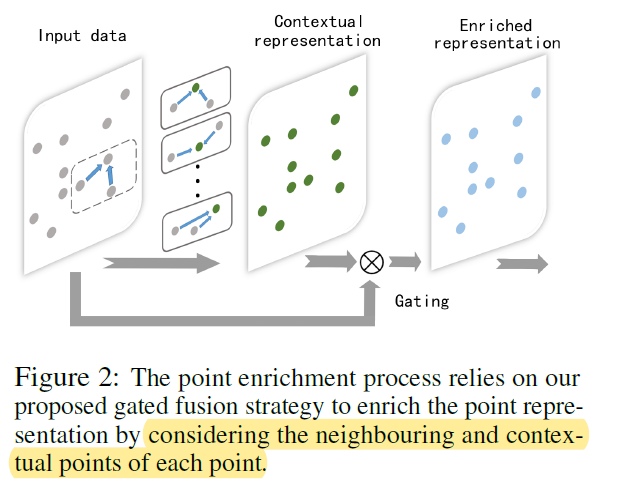
简单来讲就是对每一个点P,寻找其最近的K个点(论文中K=3),然后将这个K个点的初始feature拼接到一块,这样对这个点P其拼接后的特征就是K*D。
然后对这个P点进行特征升维(D—>KD),然后使用这个两个 KxD维度特征进行相互运算:
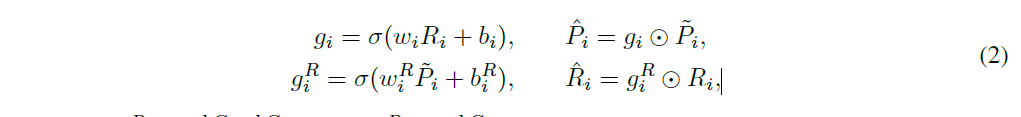
最后将两个特征拼接就得到了每个点的初始feature(KxD || KxD=2KxD)
2.2 Feature Representation
采用的是经典的encoder-decoder模型,基本和PointNet2一致
Encoder
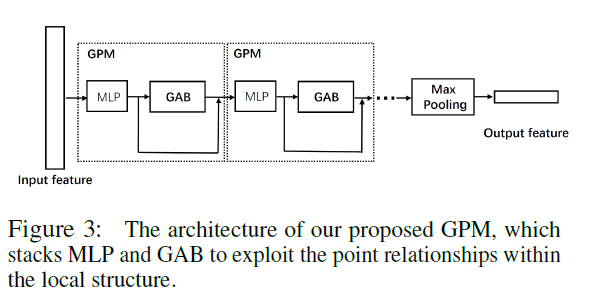
在grouping后,PointNet2的局部是使用的PointNet,仅仅是对每一个点进行特征提取,作者认为这种方式忽视了点之间的关系,作者添加了一个GAB(Graph Attention Block)模块用来计算局部点之间的相似度。
具体实现也很简单,就是计算相识度,然后求得权重,最后加权求和更新特征:

Decoder
和PointNet2一致
2.3 Prediction
为了利用点之间的Global信息,引入attention机制(Spatial-wise Attention和Channel-wise Attention),来融合每个点的特征。
Spatial-wise Attention
对每一个点分配一个权重,然后更新特征

Channel-wise Attention
对每一个通道分配一个权重,然后更新特征
最后合并两个更新后特性,得到全局特征。
一个疑问:这里为啥不直接基于对空间attention后的点在进行channel attention呢?
3、实验结果
S3DIS
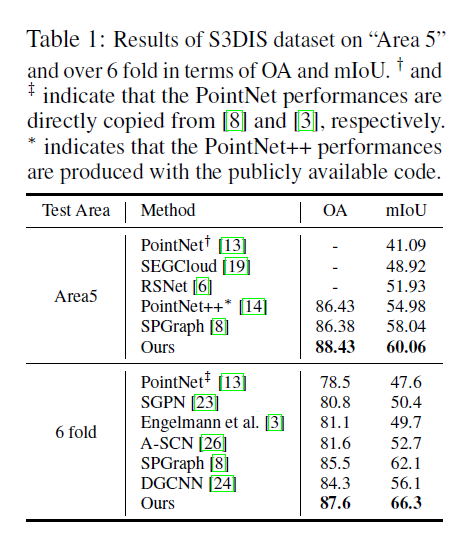

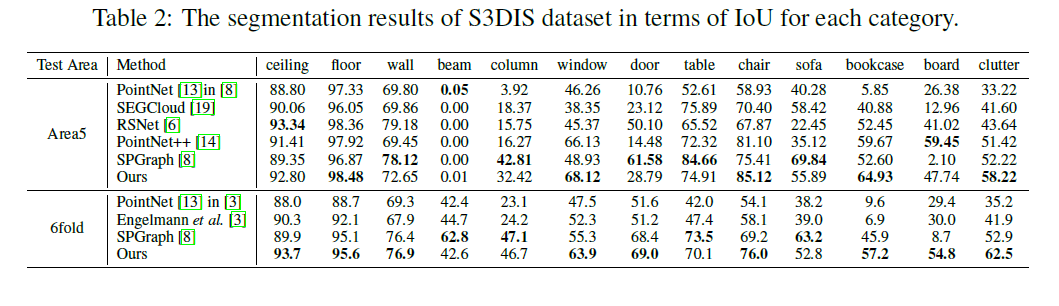
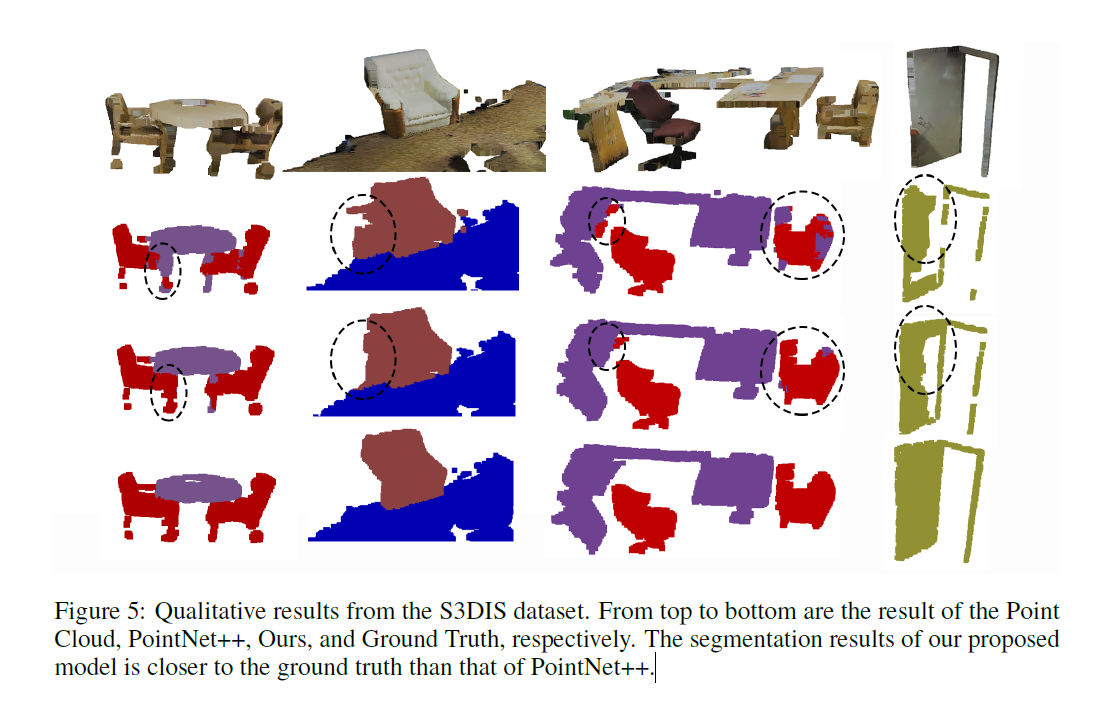
Scan Net
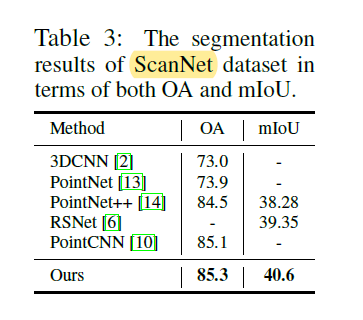
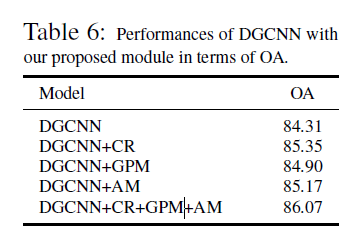
消融实验


验证模块的有效性
版权声明:本文为suyunzzz原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。