任务

Introduction to Multi-modal Learning

基础的:NLP Vision Auditory
进阶:触觉 嗅觉等等
进一步: 脑电信号 皮电 红外图 深度图 脑电图等等

Multi-Modal Learning Tasks
Language-Audio

- 文本 生成 语音 -> 后序还要生成语音和人图像口型对上
Vision-Audio

第一件是早期的,在深度学习之前;
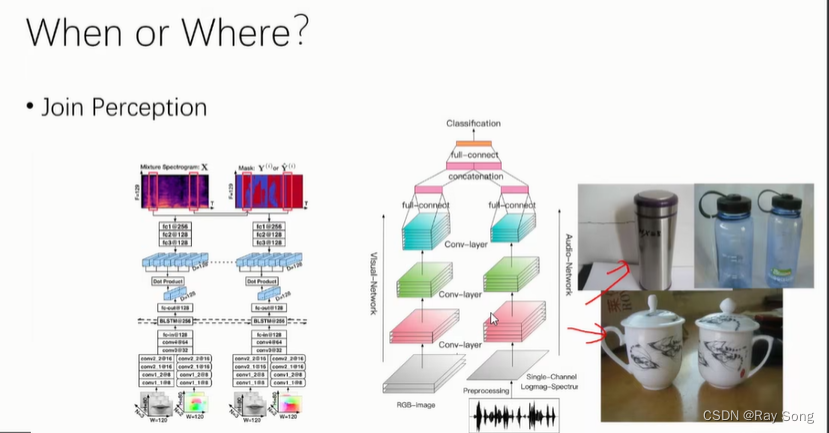
视频声音分离,加入视觉的信息,比如口型辅助声音分离,声源定位。
结合语音和口型,动画配音生成三维口型。
(局部点- - 构建声音和点的位置关系映射)

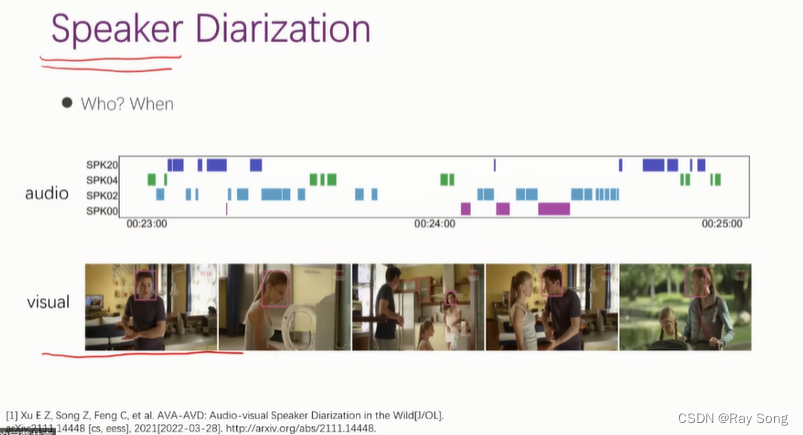
某个人在哪个时间段说话了,完成标记的任务。
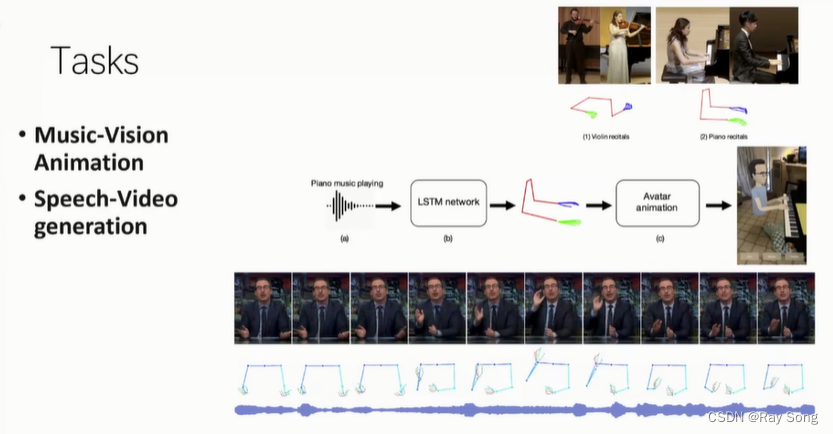
声音转换成动作,建立拉琴和声音 任务手势和声音的映射
Vision-Language

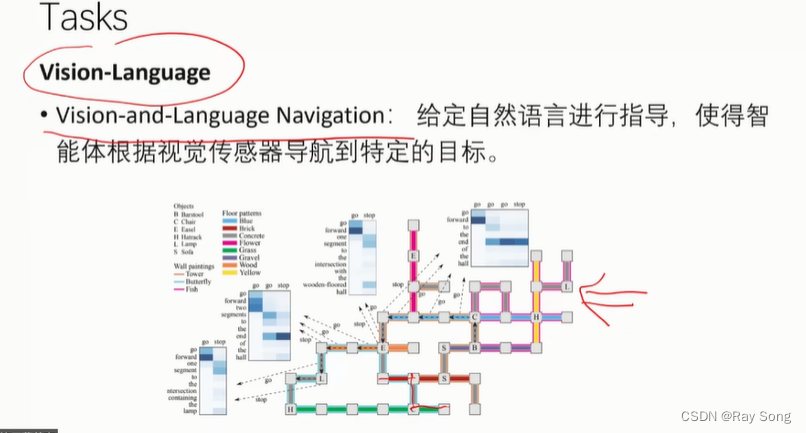
机器人根据人的语言进行导航,比如看到树往哪儿走,看到红绿灯干嘛?



通过图像辅助翻译
定位相关任务

只有文字,没有视觉,无法完全理解客观世界。



Core Challenges

1. Representation
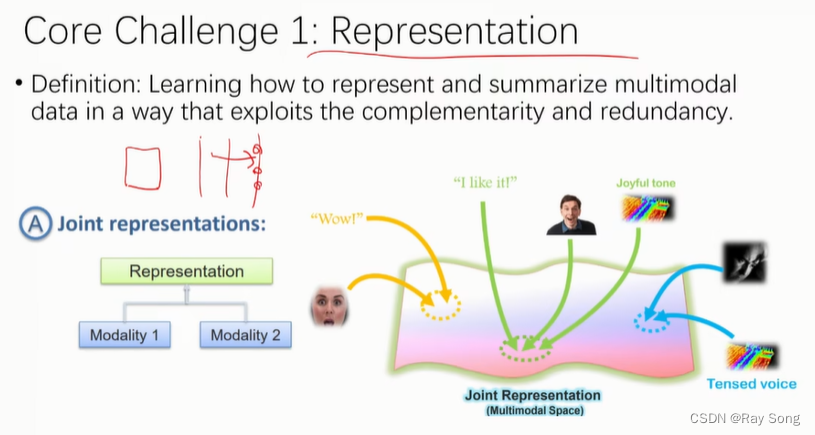
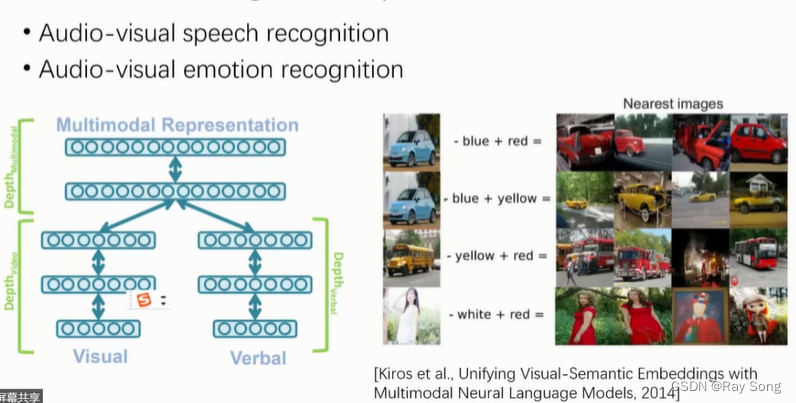
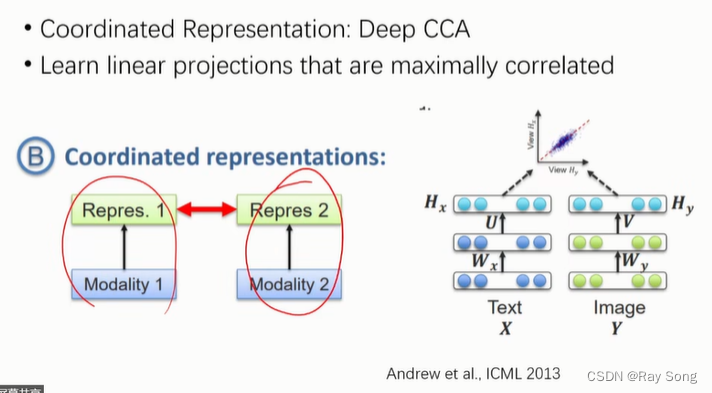
word2vec , 不同模态的信息都表示为向量
2. Alignment
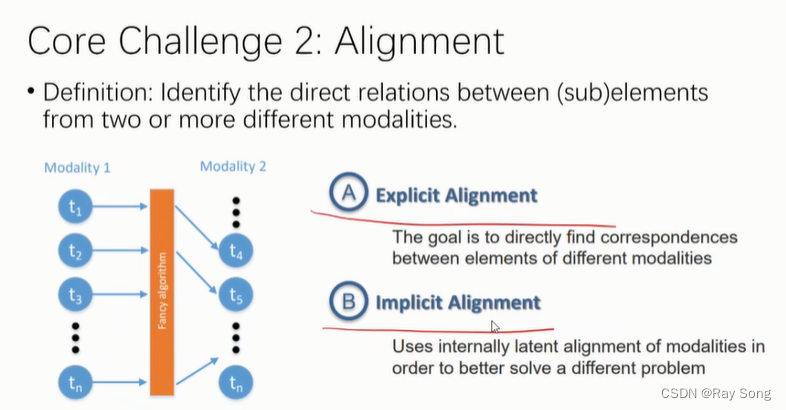
显示对齐 隐式对齐 例子如下: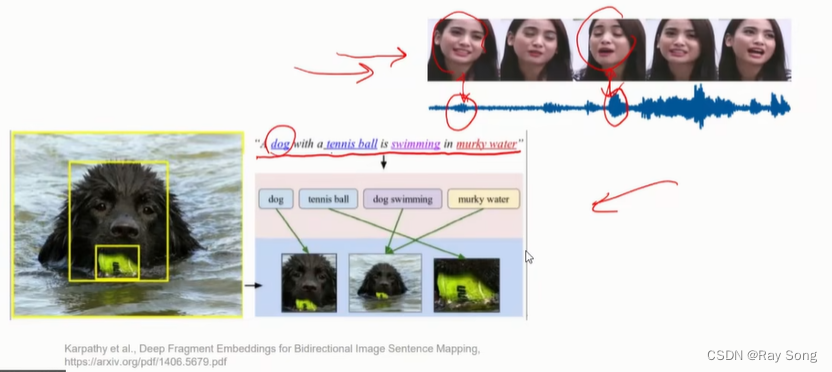

3. Fusion
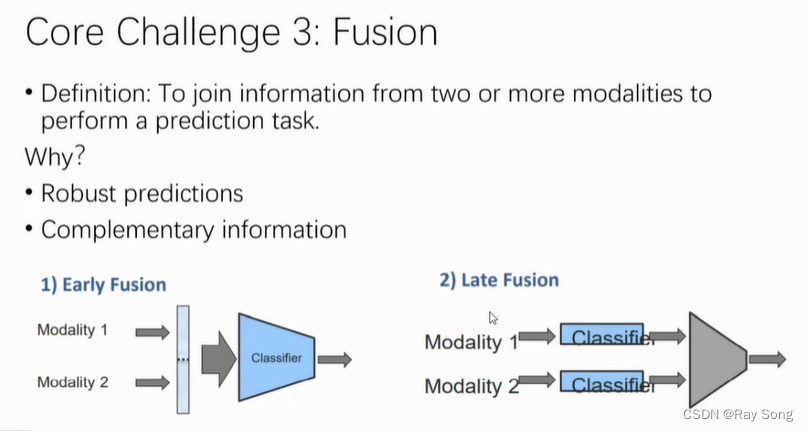
融合过程,融合越早越好,但是不是所有的数据能够很早融合。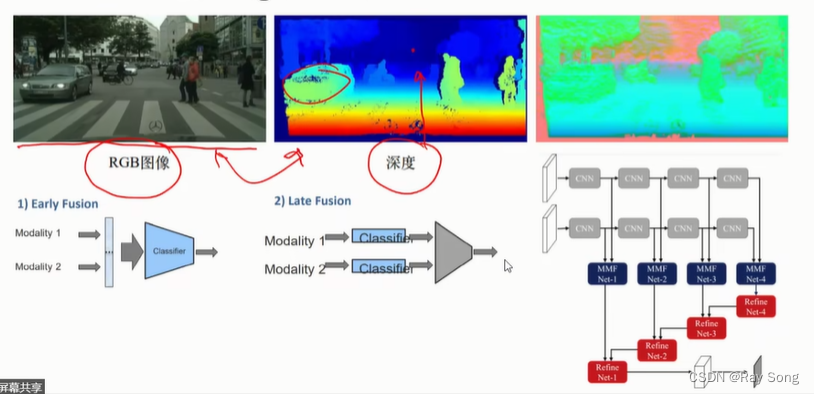

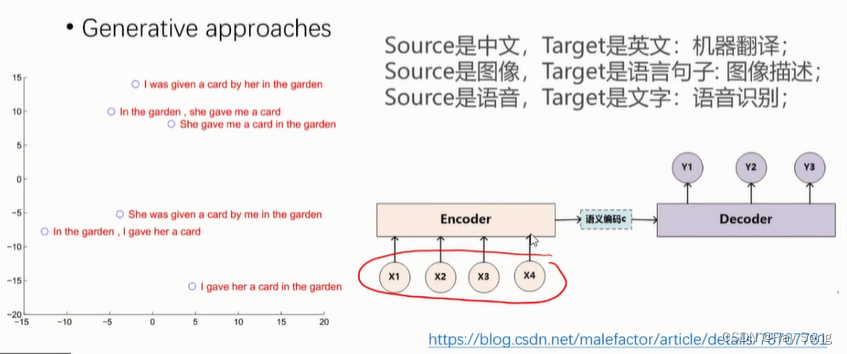
4. Translation

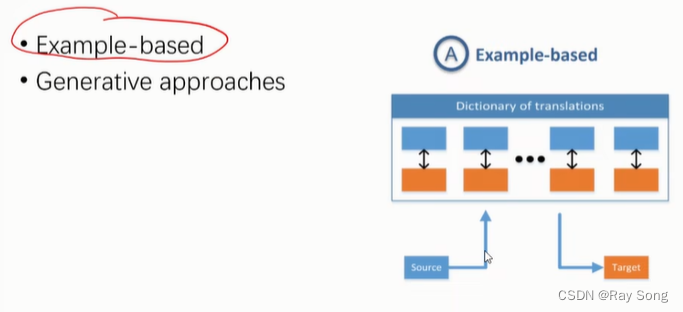


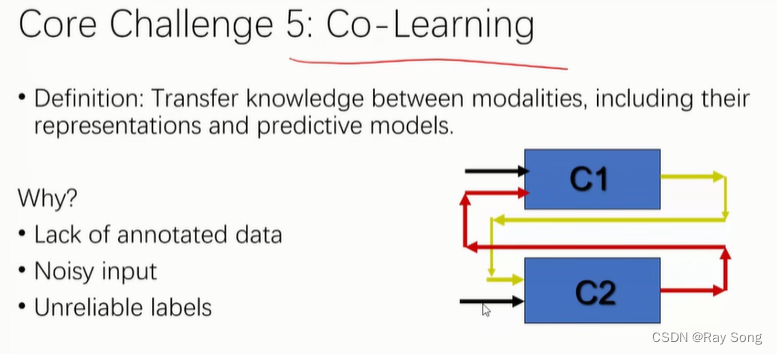
5. Co-Learning
CMU 98年的论文
Short History







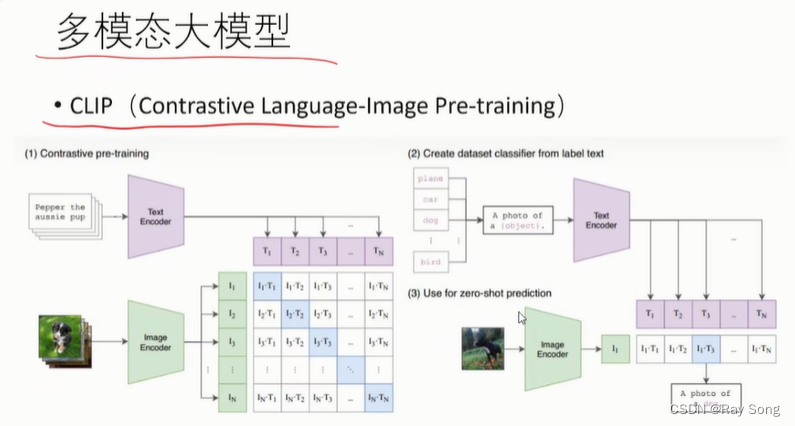
多模态大模型

问题
多模态学习:
表示 - 语言 + 语音
对齐 和 评价好坏
生成任务上,是否有一个比较好的评价指标
根据实际任务设置
版权声明:本文为rayso9898原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。