注:本文接上一个博客:https://blog.csdn.net/ITwangxiaoxu/article/details/106984922
@[TOC]
1.搭建hadoop伪分布式环境
1.安装虚拟机
VMware安装参考博客
https://blog.csdn.net/qq493820798/article/details/101025046?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%AE%89%E8%A3%85%E8%99%9A%E6%8B%9F%E6%9C%BA&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-101025046
安装Linux参考博客
https://blog.csdn.net/lnxcw/article/details/103660664
2.安装jdk
1.用传输工具将jdk包传到软件目录下,安装jdk
2.查看配置文件的位置: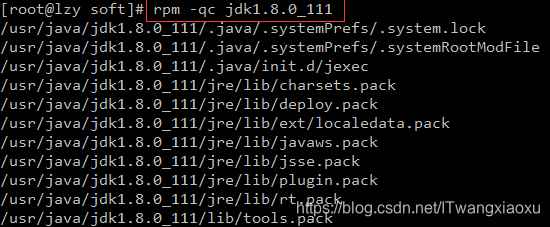
3.设置JDK的环境变量,修改/etc/profile文件,添加内容:
4.保存文件,发布命令:source /etc/profile,让配置文件生效。
3.安装hadoop
tar -zxvf hadoop-2.9.2.tar.gz
1.配置环境变量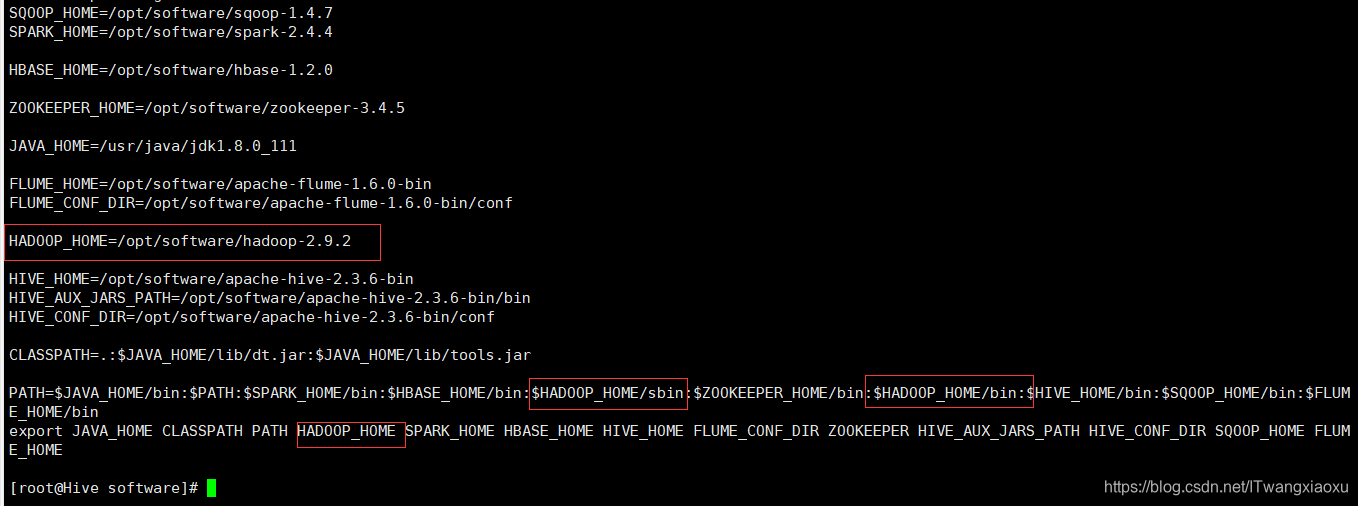
2.配置hadoop文件:/opt/software/hadoop-2.9.2/etc/hadoop
vi hadoop-env.sh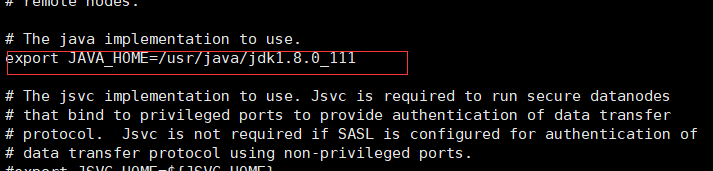
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Hive:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop-2.9.2/tmp</value>
</property>
</configuration>

vi hadf-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/software/hadoop-2.9.2/tmp/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/software/hadoop-2.9.2/tmp/datanode</value>
</property>
</configuration>

vi yarn-sit.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hive</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml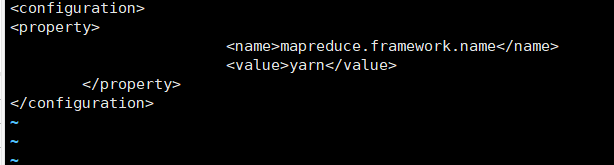
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.最后创建tmp目录下创建datanode ,namenode
4.格式化namenode节点
5.开启所有线程:start-all.sh
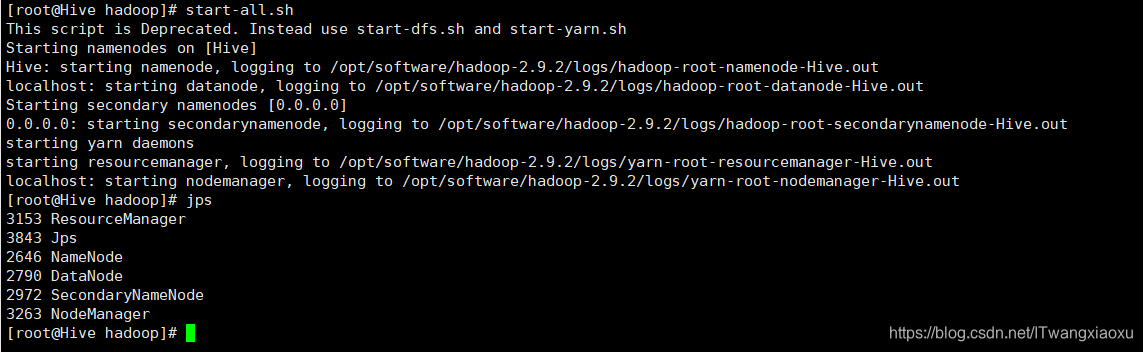
4.安装mysql
1、mysql解压
[root@master software]# tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
2、删除依赖包
[root@master mysql]# yum remove mysql-libs
3、下载包
[root@master mysql]# yum -y install perl
[root@master mysql]# yum -y install net-tools
4、进入MySQL解压包,依次安装
rpm -vih mysql-community-common-5.7.28-1.el7.x86_64.rpm
rpm -vih mysql-community-libs-5.7.28-1.el7.x86_64.rpm
rpm -vih mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
rpm -vih mysql-community-client-5.7.28-1.el7.x86_64.rpm
rpm -vih mysql-community-server-5.7.28-1.el7.x86_64.rpm
#先看包
rpm -qa | grep mysql
yum remove mysql-community#用这个删除
看mysql文件
[root@big-01 mysqls]#find / -name mysql
使用rm删除
启动:service mysqld start
5、改密码
进入/etc/my.cnf,写入skip-grant-table
vi /etc/my.cnf
skip-grant-tables
6、开启mysql并将服务添加到开机启动
service mysqld start
systemctl enable mysqld
7、进入mysql
mysql
8、设置密码,并退出
mysql> use mysql;
mysql> update user set authentication_string=passworD("123456abc")where user='root';
mysql> quit;
9、进入/etc/my.cnf,删除刚刚写的
vi /etc/my.cnf
10、重启mysql,并进入mysql
service mysqld restart
mysql -u root -p
123456abc
11、设置新密码:字母小写+数字+怎么大写+@
mysql> ALTER USER 'root'@'localhost' identified by '123456';
12、授权远程访问权限
mysql> grant all privileges on *.* to root@'%' identified by '123456';
13、立即生效,并创建hive数据库
mysql> flush privileges;
mysql> create database hive;
备注:
密码复杂度修改
mysql>set global validate_password_policy=LOW;
mysql>set global validate_password_length=6;
mysql> ALTER USER 'root'@'localhost' identified by '123456';
标题5,配置hive
1、解压
tar -zxvf apache-hive-1.2.2-bin.tar.gz
2、进入/opt/software/apache-hive-2.3.6-bin/conf创建hive-site.xml文件,不要复制模板
cd /opt/software/apache-hive-2.3.6-bin/conf
touch hive-site.xml
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--这个可以设,可以不设-->
<property>
<name>java.io.tmpdir</name>
<value>/opt/software/apache-hive-2.3.6-bin/iotmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/software/apache-hive-2.3.6-bin/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://ns/user/hive/back-up</value>
</property>
</configuration>
4、创建iotmp和tmp
5、修改环境变量,并生效:
HADOOP_HOME=/usr/local/src/hadoop-2.6.0
HIVE_HOME=/opt/software/apache-hive-2.3.6-bin/
PATH=$PATH:$HOME/bin:$ZK_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
export PATH JAVA_HOME HIVE_HOME HADOOP_HOME
6、上传驱动到 /opt/software/apache-hive-2.3.6-bin/lib
mysql-connector-java-5.1.48-bin.jar
下载地址https://dev.mysql.com/downloads/connector/j/
将hadoop下share/hadoop/yarn/lib的jline-0.9.94.jar包删掉加上hive/lib的高版本的包
7、格式化hive
[root@master conf]# schematool -dbType mysql -initSchema
6.安装flume
1、解压
[root@master app]# tar -zxvf apache-flume-1.6.0-bin.tar.gz
2、环境变量

3、进入flume/conf目录
4、修改 flume-env.sh, 配置jdk目录
[root@master conf]# cp flume-env.sh.template flume-env.sh
[root@master conf]# vi flume-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_111
7.安装sqoop
1、解压sqoop
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
2、环境变量
3、进入sqoop/conf/复制模板
cp sqoop-env.template.sh sqoop-env.sh
vi sqoop-env.sh
4、sqoop-env.sh的添加内容
export HADOOP_COMMON_HOME=/opt/software/hadoop-2.9.2
export HADOOP_MAPRED_HOME=/opt/software/hadoop-2.9.2
export HIVE_HOME=/opt/software/apache-hive-2.3.6-bin
export JAVA_HOME=/usr/java/jdk1.8.0_111
export HADOOP_HOME=/home/sofware/hadoop-2.9.2
使其生效
source sqoop-env.sh
5、拷贝jar包到lib目录
mysql-connector-java-5.1.48-bin.jar
2.flume监听hive日志文件并写入hdfs
Flume介绍
Flume是Apache基金会组织的一个提供的高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前Flume有两个版本,Flume 0.9x版本之前的统称为Flume-og,Flume1.X版本被统称为Flume-ng。
参考文档:http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.5.0-cdh5.3.6/FlumeUserGuide.html
Flume-og和Flume-ng的区别
主要区别如下:
- Flume-og中采用master结构,为了保证数据的一致性,引入zookeeper进行管理。Flume-ng中取消了集中master机制和zookeeper管理机制,变成了一个纯粹的传输工具。
- Flume-ng中采用不同的线程进行数据的读写操作;在Flume-og中,读数据和写数据是由同一个线程操作的,如果写出比较慢的话,可能会阻塞flume的接收数据的能力。
Flume结构
Flume中以Agent为基本单位,一个agent可以包括source、channel、sink,三种组件都可以有多个。其中source组件主要功能是接收外部数据,并将数据传递到channel中;sink组件主要功能是发送flume接收到的数据到目的地;channel的主要作用就是数据传输和保存的一个作用。Flume主要分为三类结构:单agent结构、多agent链式结构和多路复用agent结构。
进入flume的conf配置文件夹
编写nginx配置信息
在hive根目录下创建logs文件夹,
编写flume的agent配置信息
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
#监听文件夹roothive
a2.sources.r2.command = tail -F /tmp/root/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://Hive:9000/logs/%Y%m%d/%H0
#
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
移动hdfs依赖包到flume的lib文件夹中(jar包在以下目录)。
/hadoop-2.9.2/share/hadoop/common/lib/commons-configuration-1.6.jar ./
/hadoop-2.9.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar ./
/hadoop-2.9.2/share/hadoop/common/hadoop-common-2.7.2.jar ./
/hadoop-2.9.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar ./
进入flume根目录,启动
bin/flume-ng agent --conf ./conf/ --name a2 --conf-file ./conf/flume-hdfs.conf
到50070端口查看

注意:hive默认日志在/tmp/root/hive.log
3.将数据导入hive
1.将mongodb里的数据利用mongoexport.exe导出成CSV文件格式
mongoexport.exe --csv -f _id,jobname,company,area,salary,edulevel,workingExp,yaoqiu,jineng -d qiancheng -c Table -o test.csv
2.将数据导入hdfs中
hdfs dfs -put /xxxx /x

3导入hive中
创建hive表:
create table work(id string,jobname string,company string,area string,salary string,edulevel string,workingExp string,yaoqiu string,jineng string) row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' with SERDEPROPERTIES ("separatorChar"=",","quotechar"="\"") STORED AS TEXTFILE;

load data inpath "/home/test.csv" into table work;

查看数据: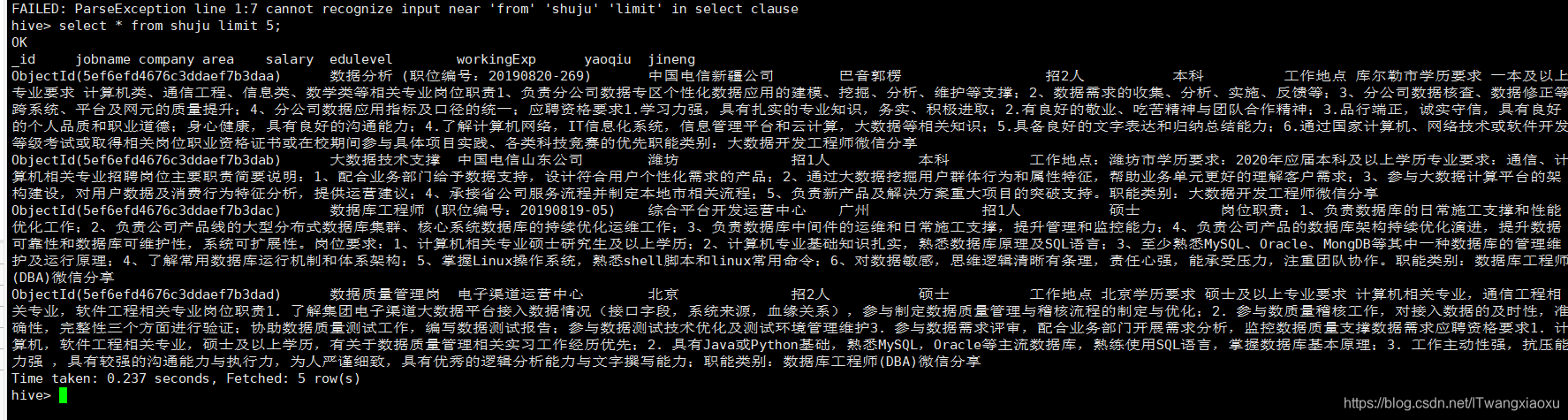
4.分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来; 将要求得数据提取出来放到临时表:
hive分析数据
create table work2(jobname string,salary double)row format delimited fields terminated by ',';
insert into work2 select jobname,case
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) as double),2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) as double) / 12,2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) as double) / 10,2)
else 0
end as salary
from work limit 100;
创建表,将工资清洗后放入新表
去除空值
提取三个岗位的工资
create table sjkf as select * from work2 where jobname like '%数据开发%' ;
create table sjcj as select * from work2 where jobname like '%数据采集%' ;
create table sjfx as select * from work2 where jobname like '%数据分析%' ;
将三个岗位提取出来的工资进行计算,求出最大值,最小值,和平均值
create table sjfx1 as select "数据分析" as jobname, min(salary) as min, max(isalary) as max, regexp_extract(avg(salary),'([0-9]+.[0-9]?[0-9]?)',1) as avg from sjfx;


create table sjcj1 as select "数据采集" as jobname, min(salary) as min, max(salary) as max, regexp_extract(avg(salary),'([0-9]+.[0-9]?[0-9]?)',1) as avg from sjcj;

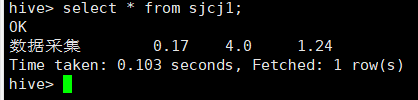
create table sjkf1 as select "数据开发" as jobname, min(salary) as min, max(salary) as max, regexp_extract(avg(salary),'([0-9]+.[0-9]?[0-9]?)',1) as avg from sjkf;

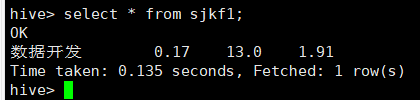
create table tab(jobname string, min double, max double, avg double)row format delimited fields terminated by ',';
insert into table tab select * from sjfx1;
insert into table tab select * from sjkf1;
insert into table tab select * from sjcj1;
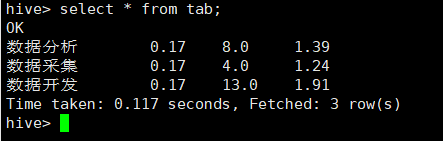
mysql创建表
create database salary;
use salary;
create table tab(jobname varchar(50), min double, max double, avg double)charset utf8 collate utf8_general_ci;

将hive数据用sqoop导入mysql
sqoop export --connect "jdbc:mysql://Hive:3306/salary?characterEncoding=UTF-8" --username root --password 123456 --table tab --export-dir /user/hive/warehouse/test.db/tab --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "," --input-lines-terminated-by "\\n" -m 1


各岗位薪资分析
import pymysql
from pyecharts.charts import Bar
from pyecharts import options as opts
# 最低薪资
min_all = []
# 最高薪资
max_all = []
# 平均薪资
avg_all = []
# 连接数据库
myClient = pymysql.connect(
host="192.168.191.100",
database='salary',
user='root',
password='123456'
)
# 创建游标
db = myClient.cursor()
# 数据分析
# 执行语句
db.execute('select min from tab;')
# 获取所有结果
result = db.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
min_all.append(i[0])
# 大数据开发工程师
# 执行语句
db.execute('select max from tab;')
# 获取所有结果
result = db.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
max_all.append(i[0])
# 数据采集
# 执行语句
db.execute('select avg from tab;')
# 获取所有结果
result =db.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
avg_all.append(i[0])
# 关闭游标
db.close()
# 绘制图表
bar = Bar(init_opts=opts.InitOpts(width="900px", height="400px"))#图表大小
bar.set_global_opts(
title_opts=opts.TitleOpts(title="工资", subtitle="万/月"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 25}),
)
bar.add_xaxis(['数据分析','大数据开发工程师','数据采集'])
bar.add_yaxis("最高薪资", max_all)
bar.add_yaxis("最低薪资", min_all)
bar.add_yaxis("平均薪资", avg_all)
bar.render("大数据各岗位工资水平图.html")
可视化结果:

5. 分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
hive分析数据
创建地区表
创建成都表:create table chengdu(name string, num int);
创建北京表:create table beijing(name string, num int);
创建广州表:create table guangzhou(name string, num int);
创建上海表:create table shanghai(name string, num int);
创建深圳表:create table shenzhen(name string, num int);
将三个职业在成都的数量求出来(都一样,这里只写一种)
insert into table chengdu select '数据分析', count(*) from work where jobname like '%数据分析%' and area like '%成都%';
insert into table chengdu select '数据采集', count(*) from work where jobname like '%数据采集%' and area like '%成都%';
insert into table chengdu select '数据开发', count(*) from work where jobname like '%数据开发%' and area like '%成都%';



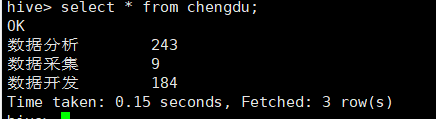
创建
在mysql数据库中建表;
create database area;
use area;
create table chengdu(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table beijing(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table shanghai(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table guangzhou(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table shenzhen(name varchar(20), num int) charset utf8 collate utf8_general_ci;

将hive表数据利用sqoop传输数据到mysql(sqoop转移数据具体用法和意义自行百度)同样只写一种
sqoop export --connect “jdbc:mysql://Hive:3306/area?characterEncoding=UTF-8" --username root --password 123456 --table chengdu --export-dir /user/hive/warehouse/test.db/chengdu --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1

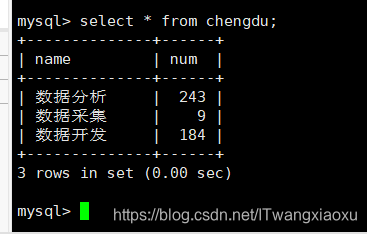

**
数据分析岗位数量分析
**
import pymysql
from pyecharts.charts import Pie
from pyecharts import options as opts
"""数据分析岗位数据"""
# 连接数据库
myClient = pymysql.connect(
host="192.168.191.100",
database='area',
user='root',
password='123456',
)
# 创建游标
cur = myClient.cursor()
#创建放置数量的列表
num=[]
# 1、成都
# 执行语句
cur.execute('select num from chengdu where name = "数据分析";')
# 获取所有结果 fetchone获取第一个
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# 2、北京
# 执行语句
cur.execute('select num from beijing where name = "数据分析";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# 3、上海
# 执行语句
cur.execute('select num from shanghai where name = "数据分析";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# 4、广州
# 执行语句
cur.execute('select num from guangzhou where name = "数据分析";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# 5、深圳
# 执行语句
cur.execute('select num from shenzhen where name = "数据分析";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
city = ['成都', '北京', '上海', '广州', '深圳']
c = (
Pie()
.add("", [list(z) for z in zip(city,num )])
.set_global_opts(title_opts=opts.TitleOpts(title="数据分析师"))
#formatter参数{a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}({d}%)"))
.render("数据分析师地区图.html")
)
可视化结果
:
数据采集岗位分析
import pymysql
from pyecharts.charts import Pie
from pyecharts import options as opts
"""
数据采集岗位数据
"""
# 连接数据库
myClient = pymysql.connect(
host="192.168.191.100",
database='area',
user='root',
password='123456',
)
#创建放置数量的列表
# 创建游标
cur = myClient.cursor()
# 1、成都
# 执行语句
num=[]
cur.execute('select num from chengdu where name = "数据采集";')
# 获取所有结果 fetchone获取第一个
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num2 = []
# 2、北京
# 执行语句
cur.execute('select num from beijing where name = "数据采集";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num3 = []
# 3、上海
# 执行语句
cur.execute('select num from shanghai where name = "数据采集";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num4 = []
# 4、广州
# 执行语句
cur.execute('select num from guangzhou where name = "数据采集";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num5 = []
# 5、深圳
# 执行语句
cur.execute('select num from shenzhen where name = "数据采集";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
city = ['成都', '北京', '上海', '广州', '深圳']
# num=[num1,num2,num3,num4,num5]
c = (
Pie()
.add("", [list(z) for z in zip(city,num )])
.set_global_opts(title_opts=opts.TitleOpts(title="数据采集师"))
#formatter参数{a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}({d}%)"))
.render("数据采集师地区图.html")
)
可视化结果
:
数据开发岗位数据分析
import pymysql
from pyecharts.charts import Pie
from pyecharts import options as opts
"""
数据开发岗位数据分析
"""
# 连接数据库
myClient = pymysql.connect(
host="192.168.191.100",
database='area',
user='root',
password='123456',
)
#创建放置数量的列表
# 创建游标
cur = myClient.cursor()
# 1、成都
# 执行语句
num=[]
cur.execute('select num from chengdu where name = "数据开发";')
# 获取所有结果 fetchone获取第一个
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num2 = []
# 2、北京
# 执行语句
cur.execute('select num from beijing where name = "数据开发";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num3 = []
# 3、上海
# 执行语句
cur.execute('select num from shanghai where name = "数据开发";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num4 = []
# 4、广州
# 执行语句
cur.execute('select num from guangzhou where name = "数据开发";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# num5 = []
# 5、深圳
# 执行语句
cur.execute('select num from shenzhen where name = "数据开发";')
# 获取所有结果
result = cur.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
city = ['成都', '北京', '上海', '广州', '深圳']
# num=[num1,num2,num3,num4,num5]
c = (
Pie()
.add("", [list(z) for z in zip(city,num )])
.set_global_opts(title_opts=opts.TitleOpts(title="数据开发师"))
#formatter参数{a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}({d}%)"))
.render("数据开发师地区图.html")
)
可视化结果

6.分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来; 以模糊匹配提取出数据岗位的记录,存入表
hive分析数据
create table p1 as select jobname,salary, workingExp from work where jobname like '%数据%';

匹配一年经验的
create table p2 as select jobname,salary, workingExp from p1 where workingExp like '%1%';

匹配2年和3年经验的
create table p3 as select jobname,salary, workingExp from p1 where workingExp like '%2%';
create table p4 as select jobname,salary, workingExp from p1 where workingExp like '%3%';


将三张表集合
insert into p4 select * from p2;
insert into p4 select * from p3;

创建新表存放清洗数据
create table p5(jobname string,salary double,workingExp string)row format delimited fields terminated by ',';
#清洗工资,统一工资单位”万/月“
insert into p5 select jobname,case
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/月',1) as double),2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)千/月',1) as double) / 12,2)
when if (regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) is NULL or regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) == '',false,true) then round(cast(regexp_extract(split(salary,'-')[1],'(.*?)万/年',1) as double) / 10,2)
else 0
end as salary,workingExp
from p4;


去除空值数据
insert overwrite table p5 select * from p5 where salary != 0.0;
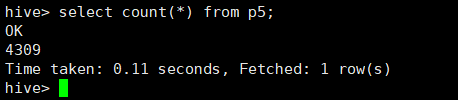
计算最值与平均值:create table salary1 as select "数据相关岗位" as jobname, min(salary) as min, max(salary) as max, regexp_extract(avg(salary),'([0-9]+.[0-9]?[0-9]?)',1) as avg from p5;

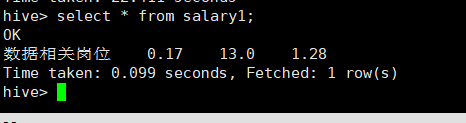
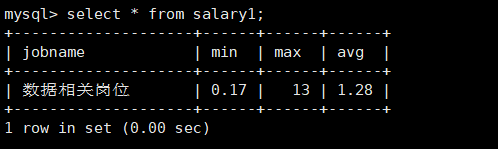
mysql创建表
create table salary1(jobname varchar(50), min double, max double, avg double)charset utf8 collate utf8_general_ci;

传输数据到MySQL
sqoop export --connect "jdbc:mysql://Hive:3306/salary?characterEncoding=UTF-8" --username root --password 123456 --table salary1 --export-dir /user/hive/warehouse/test.db/salary1 --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "," --input-lines-terminated-by "\\n" -m
岗位数据分析
import pymysql
from pyecharts.charts import Bar
from pyecharts import options as opts
"""数据相关岗位的工资最值平均值"""
# 最低薪资
num = []
# 最高薪资
# 平均薪资
# 连接数据库
myClient = pymysql.connect(
host="192.168.191.100",
database='salary',
user='root',
password='123456'
)
# 创建游标
db = myClient.cursor()
"""提取数据"""
# 执行语句
db.execute('select min from salary1;')
# 获取所有结果
result = db.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# 执行语句
db.execute('select max from salary1;')
# 获取所有结果
result = db.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# 执行语句
db.execute('select avg from salary1;')
# 获取所有结果
result =db.fetchall()
# 元祖类型result转换成列表
list_result = list(result)
for i in list_result:
num.append(i[0])
# 关闭游标
db.close()
# 绘制图表
print(num)
addr = ["最大值","最小值", "平均值"]
bar = Bar(init_opts=opts.InitOpts(width="500px", height="400px"))#图表大小
bar.set_global_opts(
title_opts=opts.TitleOpts(title="工资", subtitle="万/月"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 25}),
)
bar.add_xaxis(addr)
bar.add_yaxis("大数据岗位",num)
bar.render("大数据工资图.html")
可视化结果
