本来是个美好的周末的,但是周五晚上领导给了一个公司名称的Excel,让把这些公司的专利信息爬取下来。本文记录了爬取企业专利信息的心酸过程。码字不易,喜欢请点赞!!!
一、找寻目标网页
在接到这个任务之后,我的内心是拒绝的。但是又不能不干。因此首先我需要先找到有公司专利信息的地方。在一番查找和问了问朋友之后,我知道中国专利网、国家知识产权网、Incopat、天眼查、企查查这些网站上面都有企业的专利信息。
- 中国专利网 和 国家知识产权局
首先我看了下这两个网站,国家知识产权网页面如下,网页可以根据公司名称来搜索专利,并且还有个好处就是可以使用关键字O R OROR连接公司名称,从而一次查询多个公司的专利信息。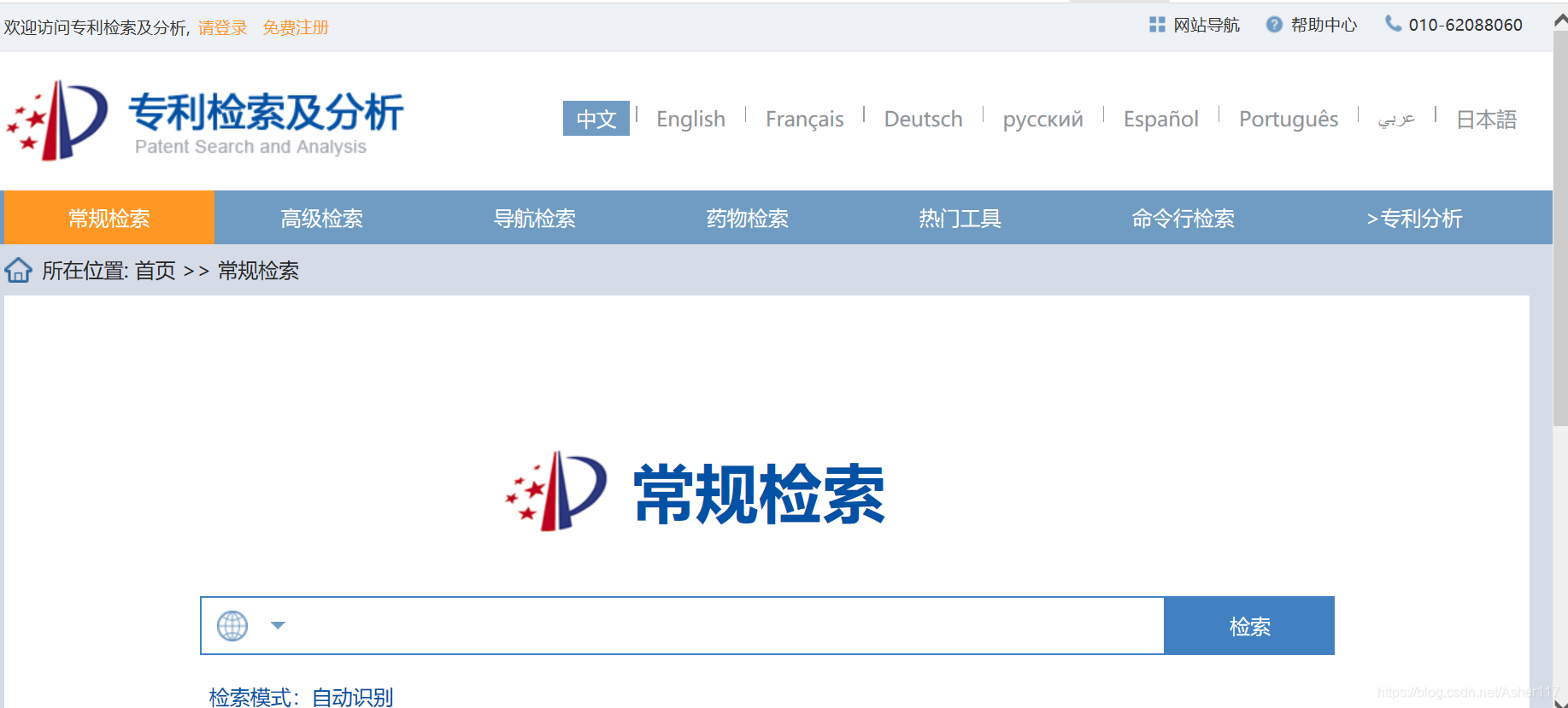
但是我还是放弃了这两个网址,是因为加载速度比较慢,如下图,点击查询或者下一页速度很慢(可能是我这边网速或者啥别的原因)。大家可以先试一下自己那边加载这个网址的速度,如果速度还行的话,建议直接在这个网页上爬取。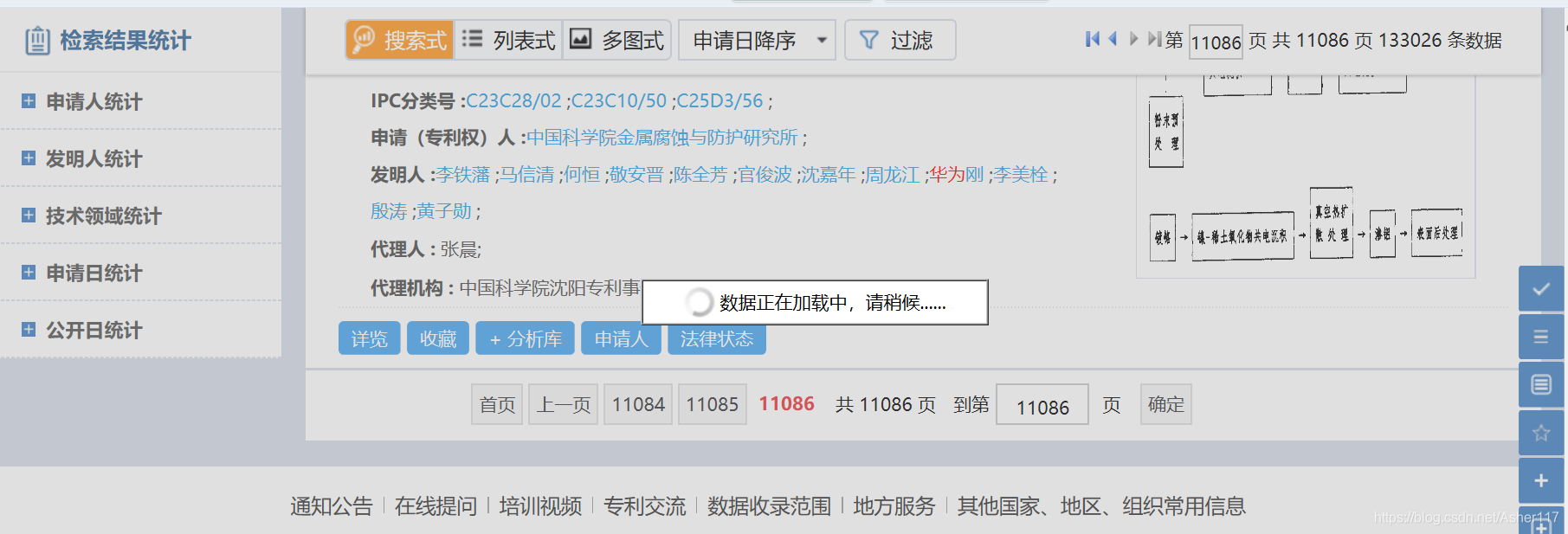
2.Incopat
Incopat网页如下,这个网页的话需要登录才能使用,当然你也可以申请试用,申请之后工作人员会联系,也比较慢。但是会有学校买过了这些数据库,比如17年大连理工买了这个数据库,当时我需要数据时候直接让大工的朋友帮忙下载的,速度很快,而且可以直接导出。
所以大家可以看看有没有哪些高校或者机构买了这个数据库,然后找一下在里面的朋友帮忙下载,速度非常快,操作十分简单。
3.天眼查和企查查
我找了一下,没找到买了Incopat的数据库的朋友。所以只好自己爬了,因为之前爬过天眼查的很多数据,所以首先看了 天眼查。
【Python爬虫】模拟登陆天眼查网站
【Python】爬取天眼查公司电话以及地址信息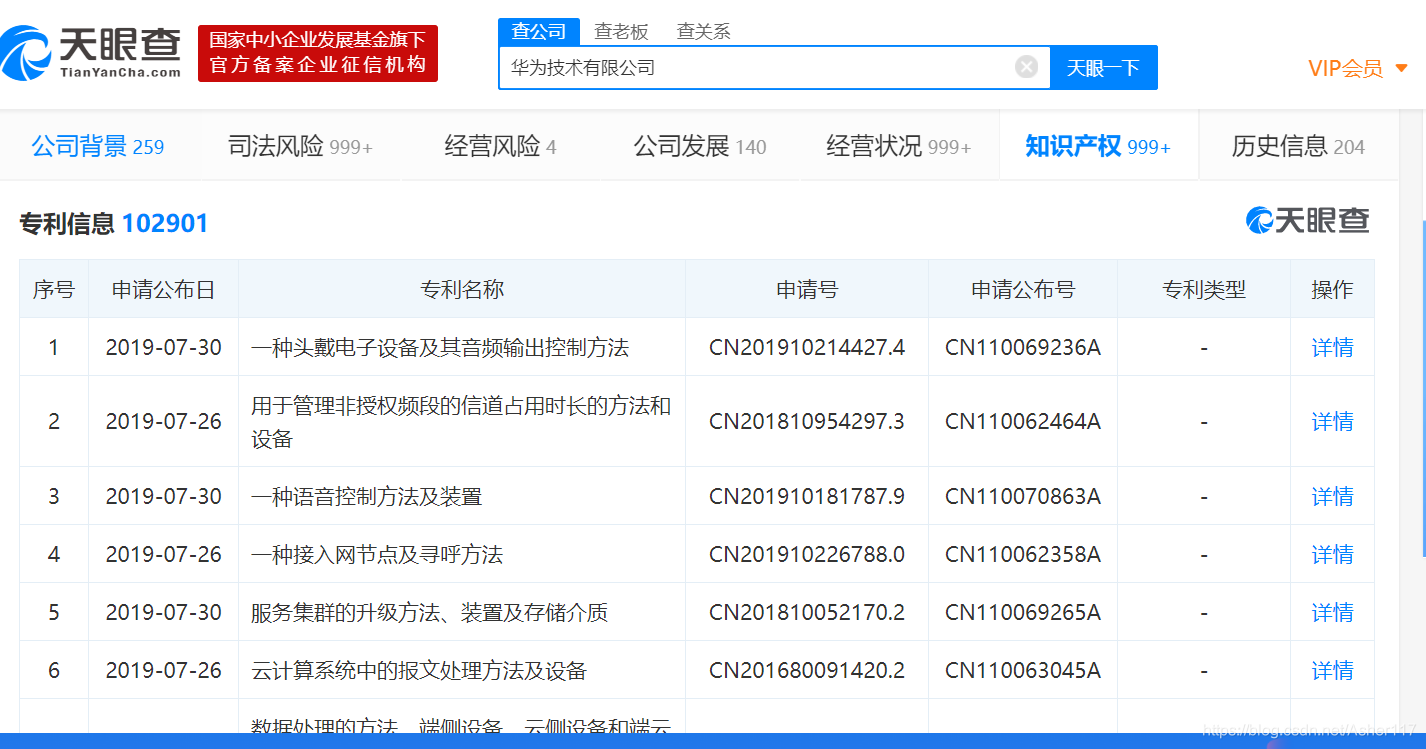
其实18年年初爬过天眼查专利信息,但是因为电脑坏了,忘记备份代码了,所以没了,很扎心!!!然后这次首先看了下天眼查专利这部分的爬虫,发现反爬做的太好了。所以选择了反差比他差一点点的企查查,企查查专利页面如下。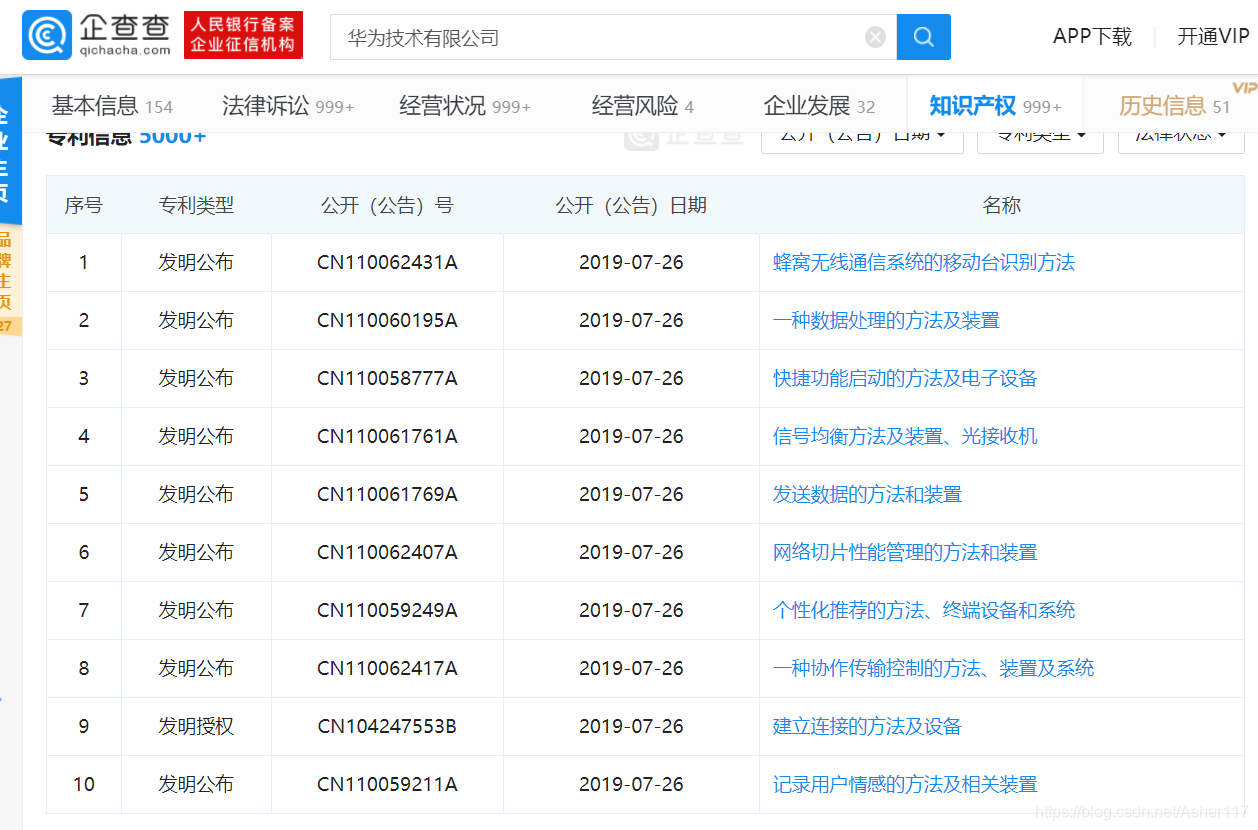
二、开始爬虫
1. 获取公司的ID
天眼查和企查查的整个网页结构是一样的,一般根据公司名称爬取企业信息,都是先获取公司的ID,然后根据公司ID进入到包含企业各项指标信息的页面。这里以华为公司为例,上面标签a的href属性值中KaTeX parse error: Expected group after '_' at position 6: /frim_̲后的一串字母数字组合就是这个公司的ID。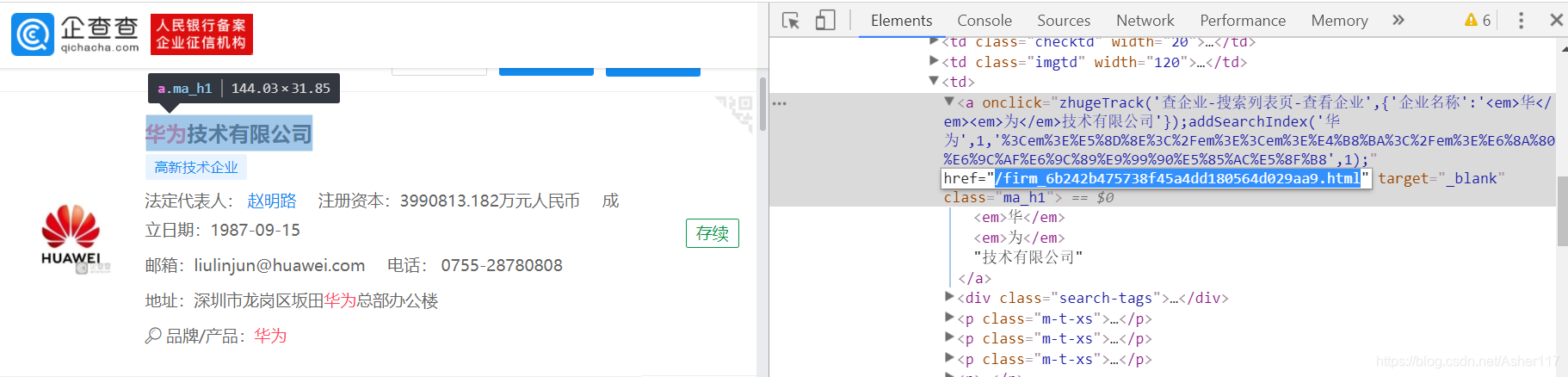
2.进入公司信息主页面
然后根据刚刚得到的公司ID(保存这个ID,后面爬取企业专利信息还需要)可以进入包含华为的内容的主页面,可以看到网址由公司ID加其他固定信息组成。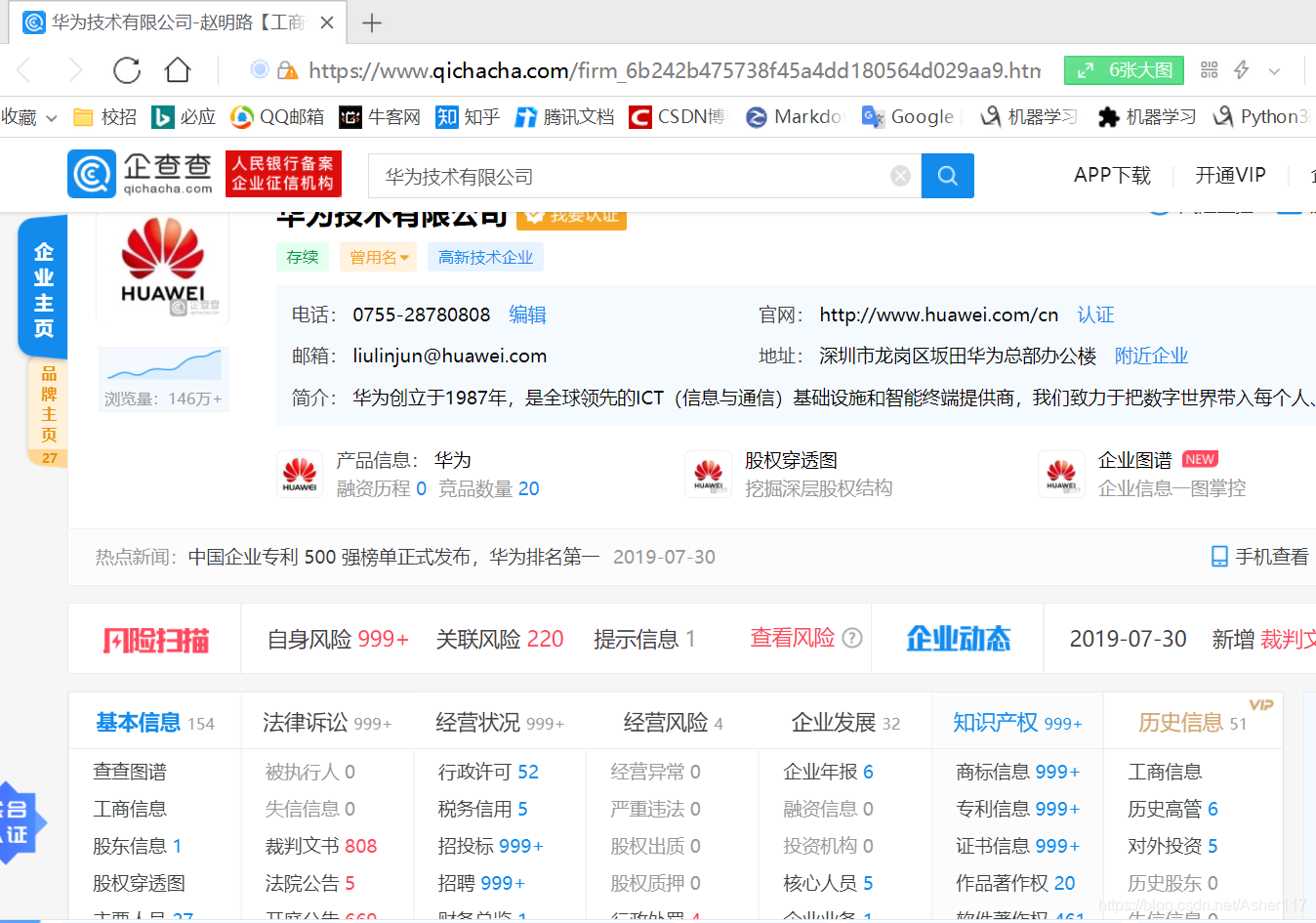
3.找到专利信息部分
专利信息在知识产权里面有,点击知识产权里面的专利信息可以跳到专利信息部分。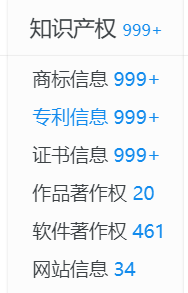
专利信息如下,到这里你会发现当一个公司的专利信息大于5000条时,只能显示最新的5000条数据。不过也没什么大关系,毕竟大部分公司的专利信息都达不到这个数据量。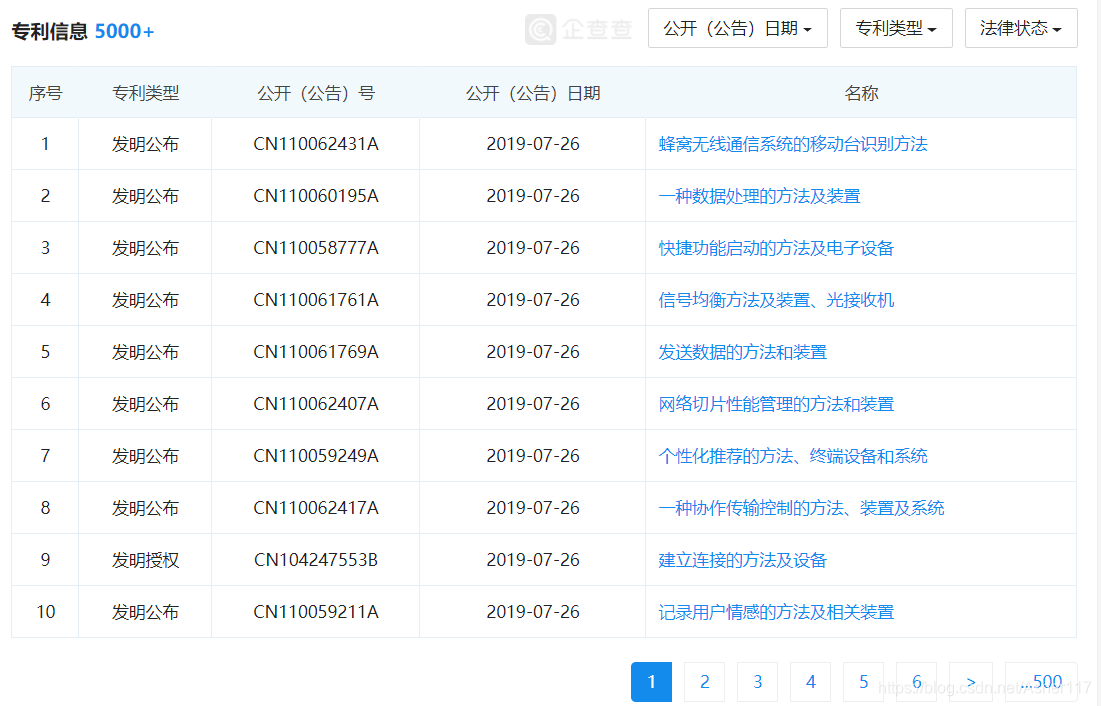
然后这里的话是动态js加载的,所以需要进入network找到页面的真是网址,来进行抓包。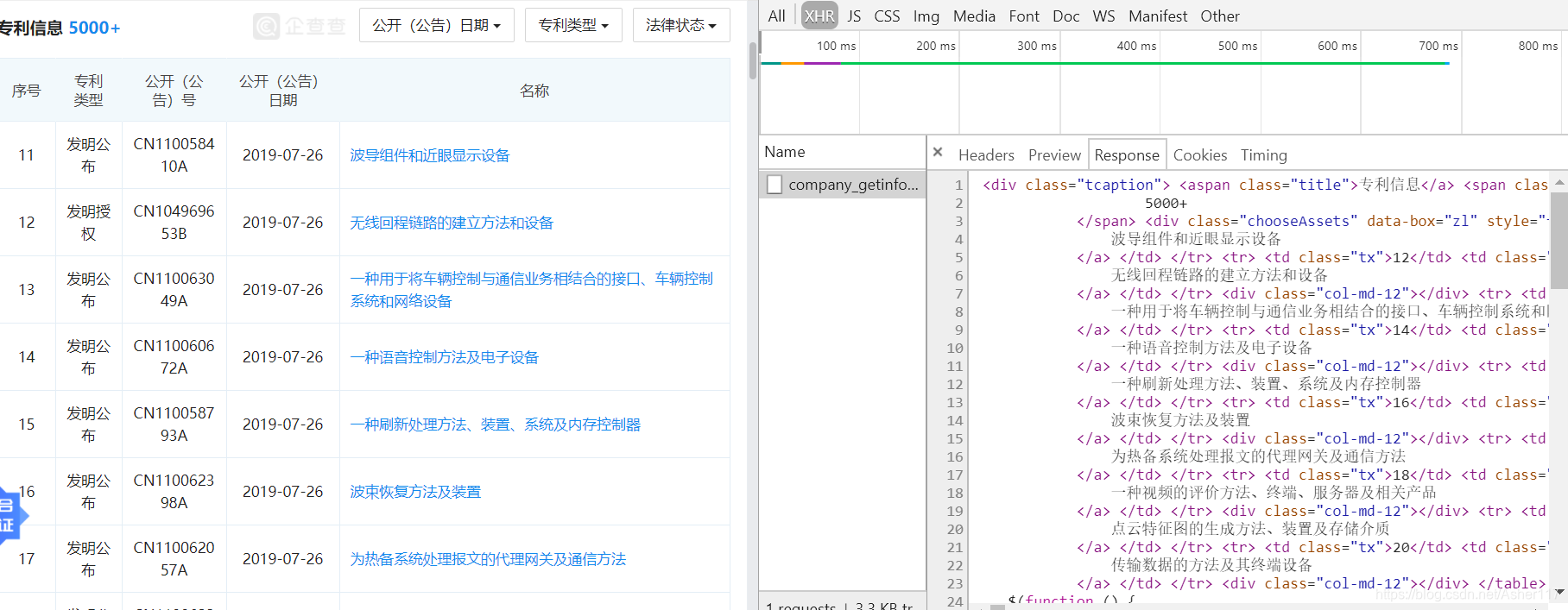
进去之后看到Response里面正好是我们要的信息。
4. 分析如何取出专利信息
然后看看Headers里面的信息,如下图,是一个Get类型请求,可以看出unique的内容就是公司的ID,而companyname后面的一串就是公司名称,p后面的数值是第几页的专利信息。
主要参数也可以直接看下面Query String Parameters部分,更加清楚。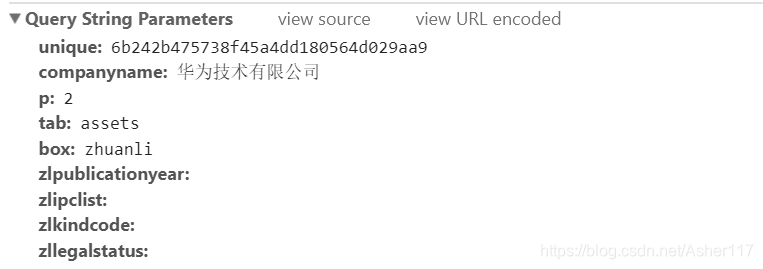
知道专利数据的请求网址之后,以前是可以直接打开,然后轻松的爬取的,现在直接打开会显示以下页面,报错显示Error 405。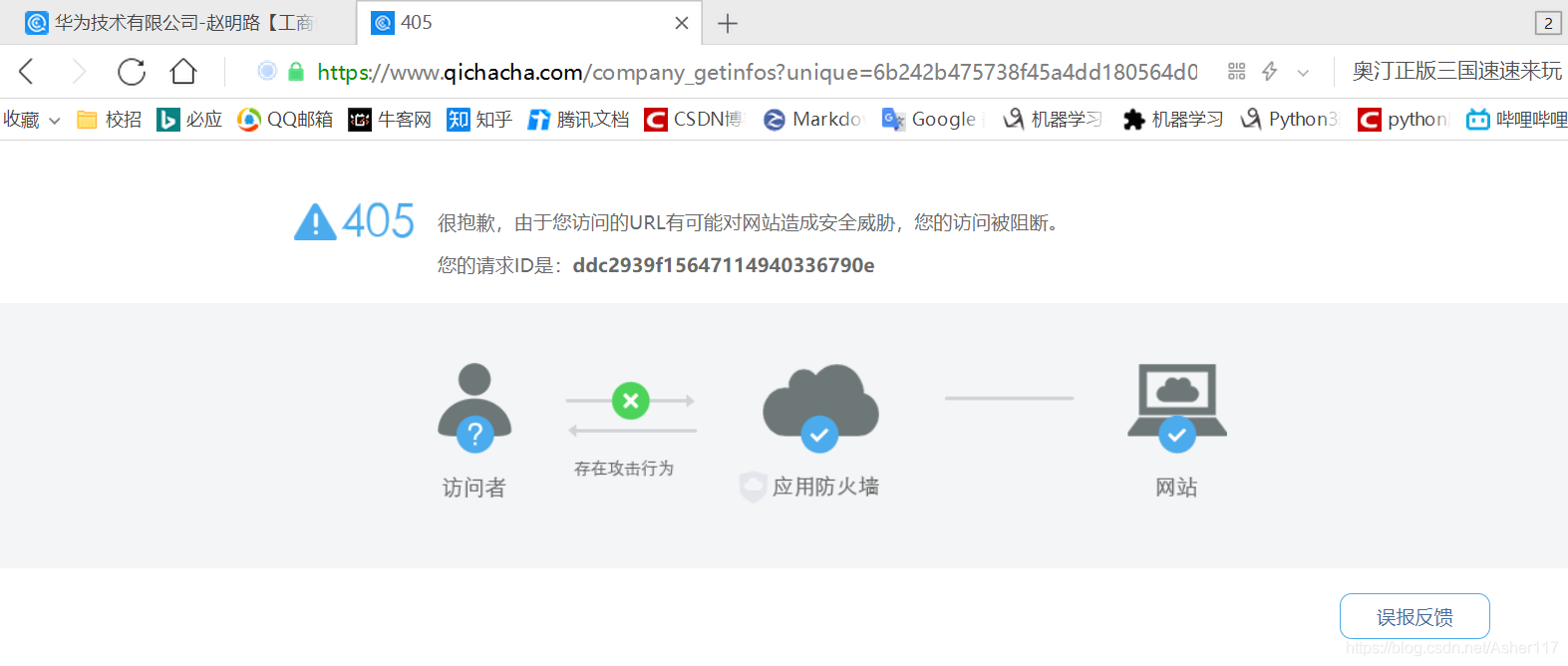
因此还是需要老老实实的根据构建请求头,下面就是这个页面的请求头信息。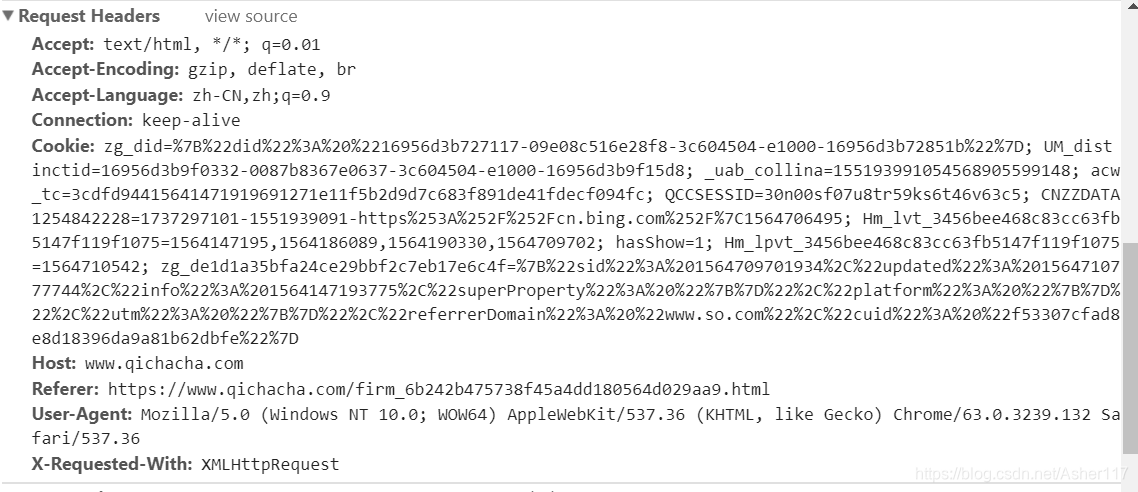
请求头里面除了cookie在你的登录信息过时了,或者被企查查要求手动检查时会更新,其他时候不会变。因此可以直接使用这些信息来抓取页面内容。
5.爬虫代码
这里按照上面的两个步骤进行的:爬虫公司ID,根据ID和公司名称爬取公司专利信息。
- 爬取所有公司ID信息
#读取公司名称
path = r"C:\公司名称.xlsx"
df = pd.read_excel(path)
df = df['Conme']
ids = [] #用来储存公司ID
for key in df[0:]:
print(key)#公司名称
url = 'https://www.qichacha.com/search?key='+key
id = get_id(url)#获取公司ID函数
id = id.split('firm_')[1].split('.html')[0]
ids.append(id)
time.sleep(0.44+random.random())#适当控制爬取速度,防止被封
#将爬取的公司ID存到文档
ids = pd.DataFrame(ids)
dfid = pd.read_excel(r"C:\companyID.xlsx")
dfid = pd.concat([dfid,ids])
dfid.to_excel(r"C:\companyID.xlsx",index=0)
- 爬取公司专利信息
data = pd.read_excel(r"C:\companyID.xlsx")#读取公司ID
messages = []#存储公司专利信息
for i in range(0,data.shape[0]):#data.shape[0]
company = data.loc[i,'company']
id = data.loc[i,'companyID']
for j in range(1,501):#最多500页专利信息
url = 'https://www.qichacha.com/company_getinfos?unique='+id + '&companyname=' + company +'&p='+ str(j) + '&tab=assets&box=zhuanli&zlpublicationyear=&zlipclist=&zlkindcode=&zllegalstatus='
try:
message = get_message(company,id,url)#获取专利信息函数
except AttributeError:
break
messages.append(message)
if(len(message[0])<10 or j==500):
break
time.sleep(0.24+random.random())
time.sleep(0.56+random.random())
#存储爬取的专利信息
dfMess = pd.read_excel(r"C:\message.xlsx")
print(dfMess.shape)
for i in range(len(messages)):
m = messages[i]
me = pd.DataFrame(data = {'company':m[0],
'xuhao':m[1],
'type':m[2],
'number':m[3],
'date':m[4],
'name':m[5]})
dfMess = pd.concat([dfMess,me])
print(dfMess.shape)
dfMess.to_excel(r"C:\message.xlsx",index=0)
参考文献:
https://blog.csdn.net/Asher117/article/details/82804506
https://blog.csdn.net/Asher117/article/details/90348758