一、前言
在个人理解中,首先我们拿到一份数据后会经过以下几个流程:
1.清除数据的重复值
2.填充数据中的NULL值,空值
3.清洗数据中带有异常符号的值(最为困难)
4.更改数据类型
5.重建数据的索引
因此,我打算从这四个方面总结以下我们常用的函数。
1.1查看重复值
1.DataFrame.duplicated()
这个函数可以查看行与行间是否具有重复值,返回布尔值
如果是DataFrame.duplicated([‘v1’]),
如果指定v1列,则是查看v1列的重复值;也可以传入多个列
2.DataFrame.drop_duplicates()
删除行与行的重复值;同样可以指定删除某列或多列的重复值,它的一个参数为keep=‘last’,即保留最后的一个重复值。


1.2填充数据中的NULL值,空值
1.查看缺失值isnull(),notnull()
对于DataFrame对象

DataFrame对象使用i是null()我发现没什么用,除非每一行都是nan值,我们才有用
接下来我们看下Series中的isnull()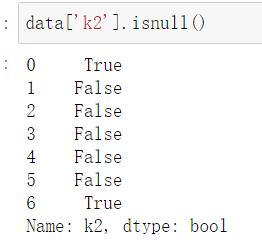
很明显,我们可以得到一列的布尔值,基于此布尔值,我们就可以对df对象或者Series对象进行过滤nan值(后面会说到)
2.既然我们知道了nan在哪,我们就有两种思路,一种是直接删除,一种是填充。我们先说删除的方法。
2.1一种是使用dropna(),默认按列删除
在df对象中,使用有两个参数how和axis
我们对data新增加了一列
axis=0,表示删除有nan值的行
axis=0,表示删除有nan值的列
how = ‘all’表示删除行中所有值都为nan的行
另一种清除缺失值的方法是使用布尔值进行清除过滤,如
data[data[‘K2’].notnull(),但不常用。
2.2 另一种是填充缺失值fillna()方法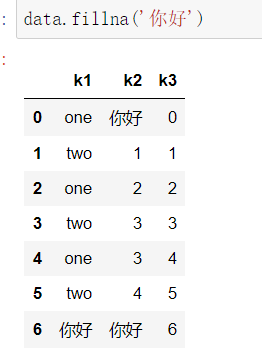
这种方法也就是骗骗小白,因为在一份数据中,我不可能对于所有的nan值都用同样的值填充,对于数值型的数据,我们可以用均值,中位数,众数或者插值或者向前,向后方法填充,而对于object对象我们更多采用向前,向后方法填充,当然object对象对于缺失值填充还是比较困难的,这里只是为了演示向前,向后填充的方法。在实际中,我们更多的是对数值型数据进行填充。