一、知网介绍
提起中国知网,如果你曾经写过论文,那么基本上都会与中国知网打交道,因为写一篇论文必然面临着各种查重,当然翟博士除外。但是,本次重点不在于写论文跟查重上,而在于我们要爬取知网上一些论文的数据,什么样的数据呢?我们举一个例子来说,在知网上,搜索论文的方式有很多种,但是对于专业人士来说,一般都会使用高级检索,因为直接去查找作者的话,容易查找到很多重名作者,所以我们本次的爬虫也是使用了高级检索(泛称)的爬虫,再具体就是专业检索,有助于我们唯一定位到作者。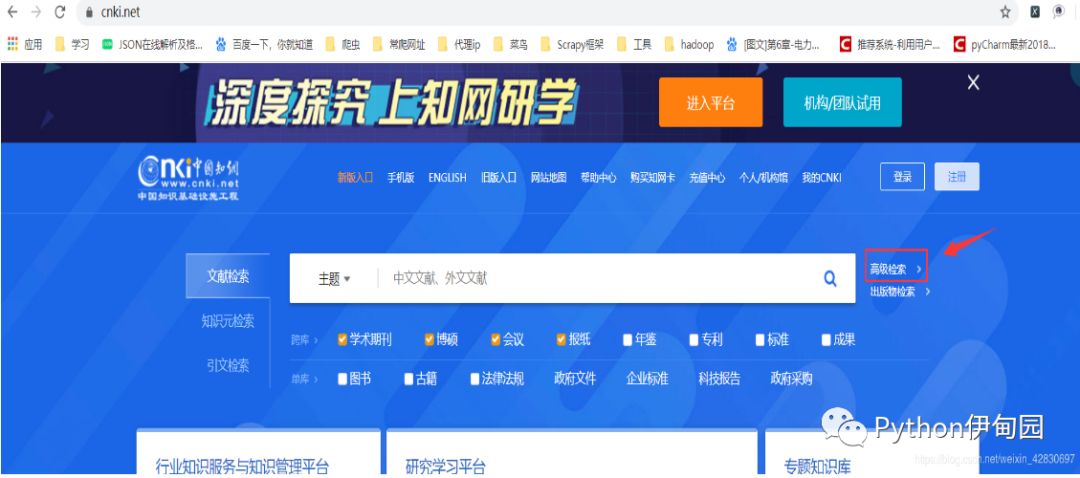
二、常规步骤—页面分析
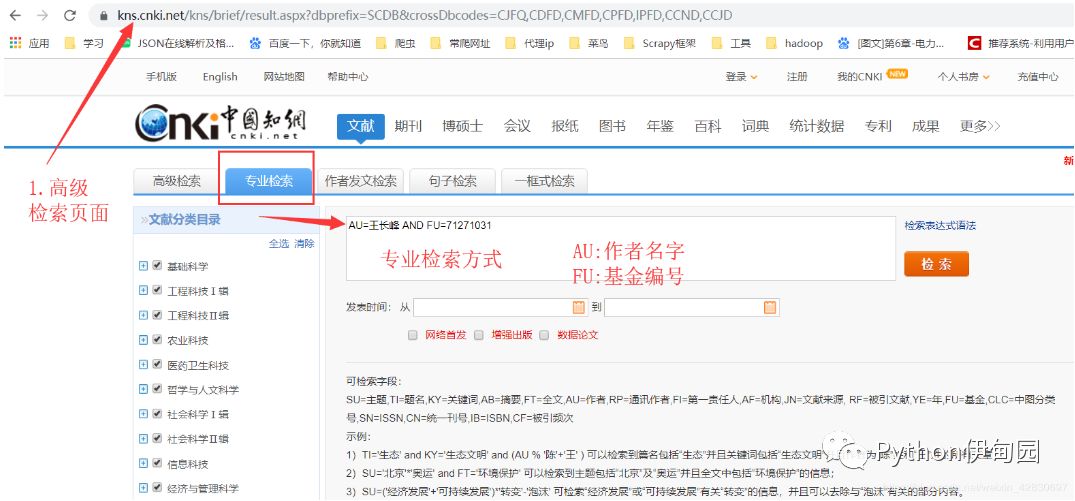
1.来到高级检索页面,以【AU=王长峰 AND FU=71271031】为例检索,结果如下:
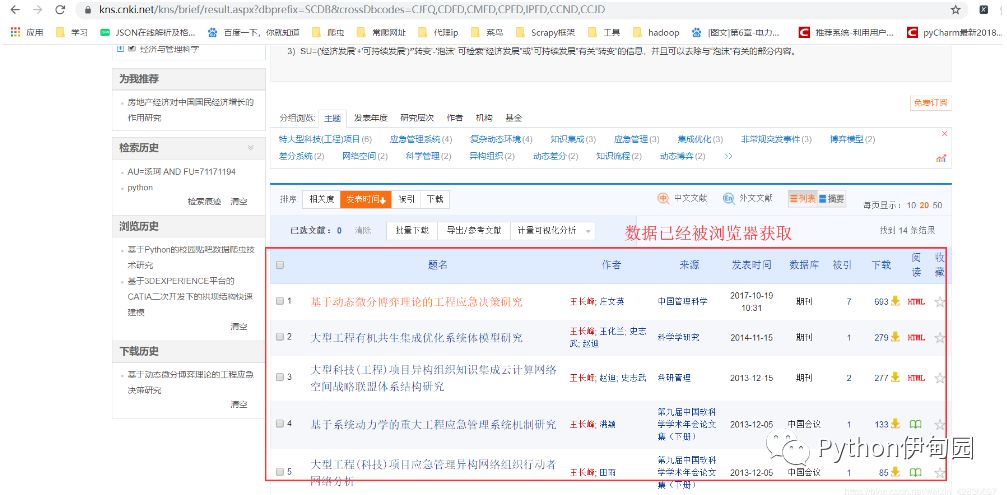
2.利用Xpath语法尝试获取这些数据,却发现一无所获。
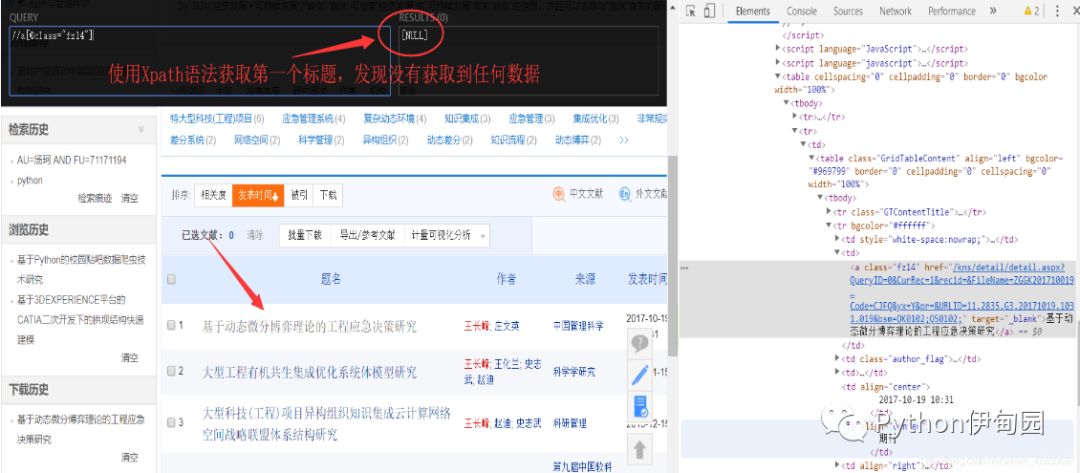
3.按照常理来说,即使是动态网页也可以利用Xpath语法提取到数据,只是在Python里面获取不到而已,所以在这里存在我们所不知道的问题。
三、知网反爬虫机制
常见的反爬虫机制一般有两种:
第一种是请求头反爬虫,这个也是最简单的,如果你不给定请求头,对方服务器就不会理你。需要设置的参数有User-Agent、Referer和Cookie。
第二种是动态网页,利用Ajax技术使用js接口来传递数据。
毫无疑问,对于数据非常金贵的中国知网来说,肯定使用了以上两种反爬方式,并且中国知网的js接口非常复杂,虽说复杂,但是只要你的内功要是足够强的话,还是能够分析得出来,但是对于不懂js以及web开发的朋友来说,这将是一个非常困难的事情,所以使用selenium来进行爬虫将是一件相对来说比较容易的事情。
另外,知网也不是仅仅只有这两层反爬虫机制,还有第三层,那就是iframe,由于很多朋友并没有做过网站开发,所以不太清楚了这是什么东西,导致即使发现自己的Xpath语法正确,也无法正确获取数据,从而怀疑人生,实际上,iframe比较常见的一种反爬虫机制,不过,如果你不知道这个东西,那么你就基本上无缘爬取中国知网了。
四、什么是iframe?
了解iframe前,你首先得知道一个网页是什么,没错,一个网页就是一个html页面。接下来我们从感性和源码两个方面来认识一下iframe.
1.感性认知。
一句话:一个完整的网页内部又嵌套了多个完整的网页,嵌套的页面就叫做iframe。

2.网页源码认识。
比如一个非常简单的html页面(如下图所示),一个html页面是拥有一个完整的html标签的,也就是起始html【】和闭合html【】,而iframe则是在这一个完整的html标签里面又嵌套了一个完整的html标签。
<html><body><p>Python伊甸园p>body>html>
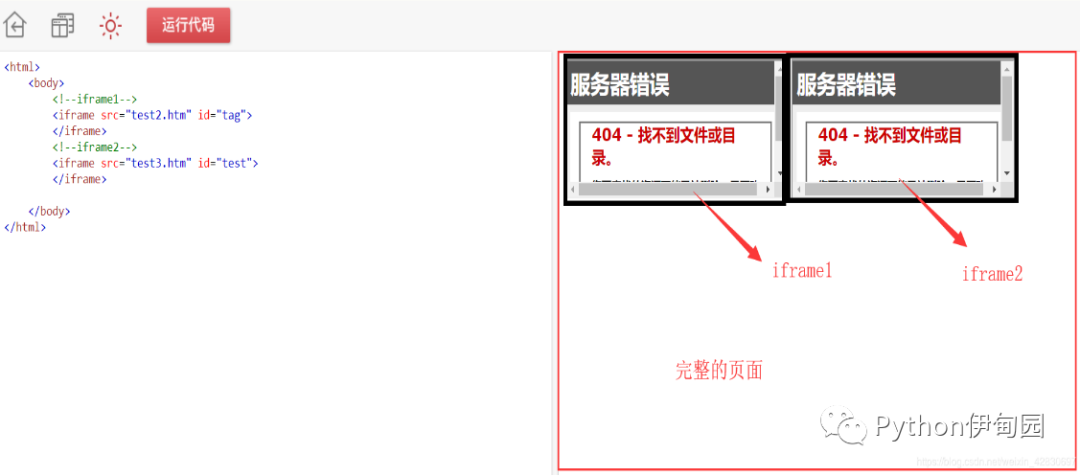
3.看一下中国知网的源码,发现果然存在一个iframe,所以这个就是中国知网的第三种反爬虫机制。
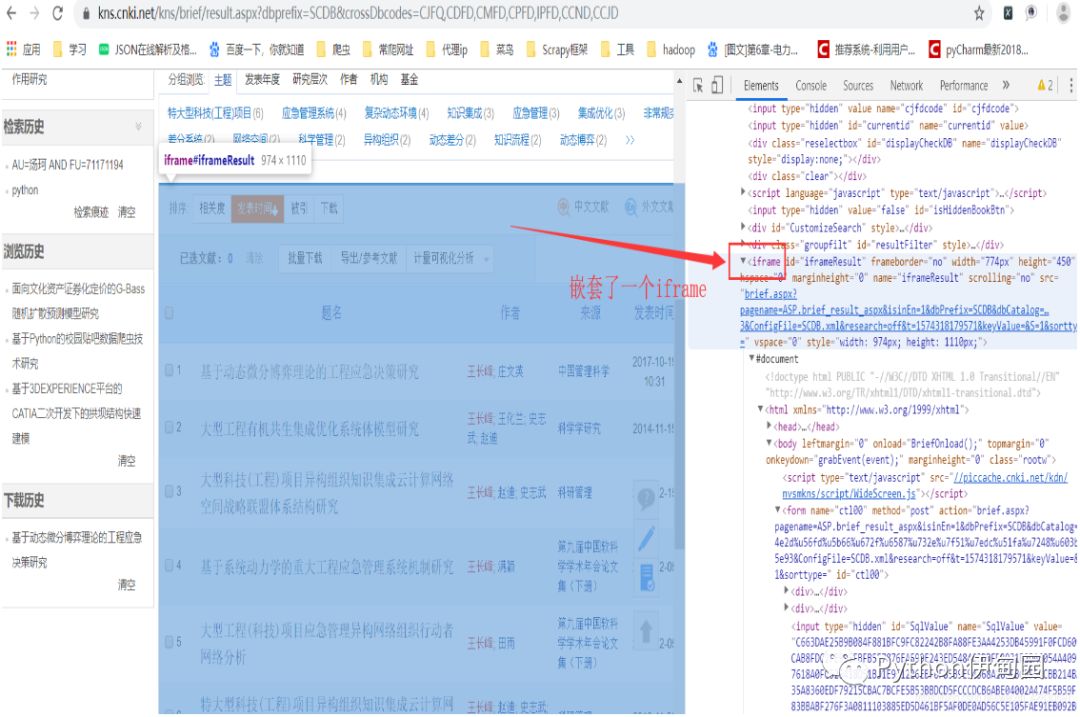
五、最后给出中国知网的爬虫
1.ways.py
import pandas as pd#AU=王长峰 AND FU=71271031def get_data(): data_list = pd.read_excel(r"C:\Users\wwb\Desktop\科学基金.xls", encoding='utf8') leaders = data_list.leader.values.tolist() codes = data_list.code.tolist() results = [] for leader,code in zip(leaders,codes): result = "AU={} AND FU={}".format(leader,code) results.append(result) return results2.main.py
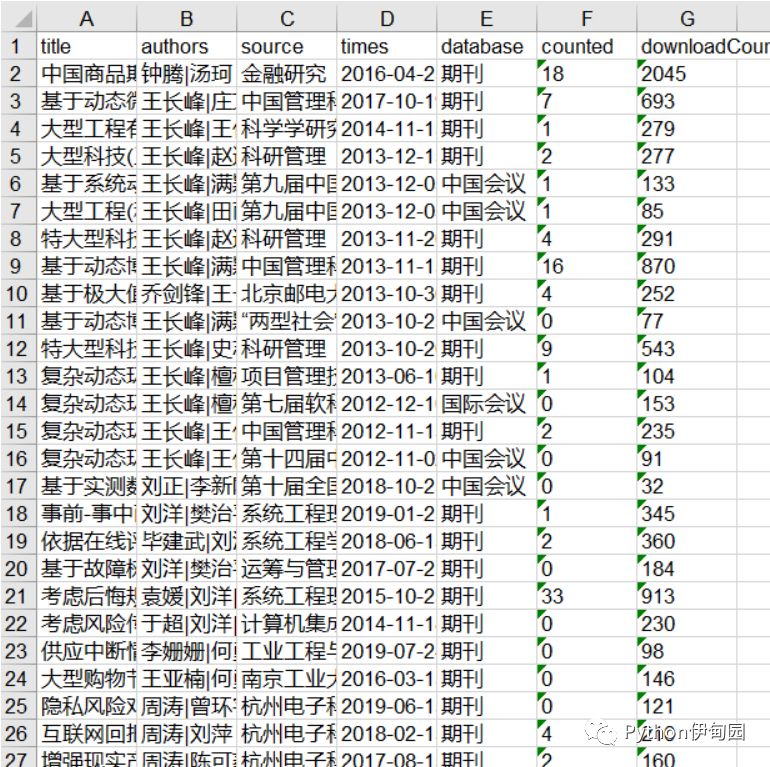
from selenium import webdriverfrom lxml import etreeimport timefrom ways import get_dataimport randomdef pasre_page(driver): html = etree.HTML(driver.page_source) trs = html.xpath('//tr[@bgcolor]') for tr in trs: title = tr.xpath('./td//a[@]/text()')[0] authors = tr.xpath('./td[@]/a[@]//text()') authors = "|".join(authors) source = tr.xpath('./td//a[@target="_blank"]/text()')[1] times = tr.xpath('./td[@align="center"]/text()')[0].strip() database = tr.xpath('./td[@align="center"]/text()')[1].strip() counted = tr.xpath('./td//span[@]/a/text()') if len(counted) == 0: counted = 0 else: counted = counted[0] downloadCount = tr.xpath('./td//span[@]/a/text()') if len(downloadCount) == 0: downloadCount = 0 else: downloadCount = downloadCount[0] data = { "title":title, "authors":authors, "source":source, "times":times, "database":database, "counted":counted, "downloadCount":downloadCount, } datas.append(data) print(title) time.sleep(random.uniform(2,4)) driver.switch_to.parent_frame() search_win = driver.find_element_by_id('expertvalue') search_win.clear() time.sleep(random.uniform(2,4)) driver_path = r"C:\Users\wwb\Desktop\chromedriver.exe"driver = webdriver.Chrome(executable_path=driver_path)url = "https://www.cnki.net/"driver.get(url)home_page = driver.find_element_by_id('highSearch')home_page.click()driver.switch_to_window(driver.window_handles[1])search_page = driver.find_element_by_id('1_3')search_page.click()datas = []results = get_data()for result in results: search_win = driver.find_element_by_id('expertvalue') search_win.send_keys(result) search_btn = driver.find_element_by_id('btnSearch') search_btn.click() iframe = driver.find_element_by_id('iframeResult') driver.switch_to.frame(iframe) time.sleep(random.uniform(2,4)) pasre_page(driver)3.部分结果展示:
Python伊甸园qq交流总群:725962878,有兴趣大家一块儿交流Python知识。
微信公众号:Python伊甸园
