Requests
import requests
url = 'http://blog.wpnet.info'
r = requests.get(url)
print('URL内容:',r.text)
print("Response:",type(r))
print('状态码',r.status_code)
print('头部:',r.headers)
print('编码格式:',r.encoding)
print('分析编码方式',r.apparent_encoding)
print('二进制方式显示HTTP响应:',r.content)
r = requests.get(url) 返回一个 Response 类
r.status_code 返回一个状态码
r.headers 返回页面的头部信息
这个头部信息其实就是浏览器中 response headers 中的信息
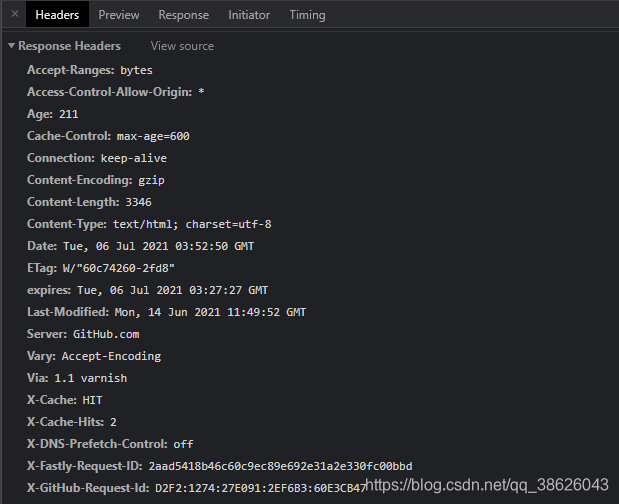
而 Response 对象包含服务器返回的所有信息,也包含我们向服务器请求信息
常用的 Response 属性
| 属性 | 说明 |
|---|---|
| r.status_code | 返回HTTP状态码 |
| r.text | 访问的URL页面内容 |
| r.encoding | 猜测相应编码方式 |
| r.apparent_encodeing | 从内容中分析相应编码方式(备用) |
| r.content | HTTP响应以二进制方式显示(图片等) |
r.encoding与 r.apparent_encodeing 区别
r.encoding 是 从 头部 得到的,而 r.apparent_encodeing 是 分析内容得到的,并不是所有服务器都有这个头部信息,如果没有这个头部信息,它会返回一个国际标准编码 ISO-8859-1 它不支持中文。
Requests库异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接异常,拒绝连接等 |
| requests.HTTPError | HTTP 错误异常 |
| requests.URLRequired | URL 缺失异常 |
| requests.TooManyRedirects | 超过最大重定向,重定向异常 |
| requests.ConnectionError | 连接服务器超时异常 |
| requests.Timeout | 请求URL超时异常 |
requests.Timeout 表示整个过程超时
requests.ConnectionError 只是连接异常
requests 通用的一个代码框架
import requests
def getText(url):
try:
r = requests.get(url,timeout = 5)
# 如果状态码不是 200,抛出 HTTPError异常
r.raise_for_status()
# 使用 apparent_encoding 使解码更加准确
r.encoding = r.apparent_encoding
return r.text
except Exception as exc:
print('异常:',exc)
exit(0)
if __name__ == '__main__':
url = 'http://blog.wpnet.info'
text = getText(url)
print(text)
requests 7个主要方法与13个访问控制参数
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各种方法的基础方法 |
| requests.get() | HTTP get方式 |
| requests.post() | HTTP post 方式 |
| requests.head() | 获取请求头 |
| requests.put | HTTP put 方式 |
| requests.patch() | 向网页局部修改请求 |
| requests.delete() | 向网页提交删除请求 |
requests.request() 方法
requests.request() 方法有三个参数,分别是
method:请求方式(get,post,put 等)
url:目标
**kwargs(13个控制访问参数)
- params:(字典或字节序列)作为参数增加到url中(get)
import requests url = 'http://blog.wpnet.info' mdict = { 'key1': 'value1', 'key2': 'value2' } r = requests.request('GET',url,params=mdict) print(r.url) # http://blog.wpnet.info/?key1=value1&key2=value2data:(字典,字节序列,文件对象,文件是通过post传递的)类似params一样的功能与参数,不过它放在post的body里(post)
json:(json格式)数据传递
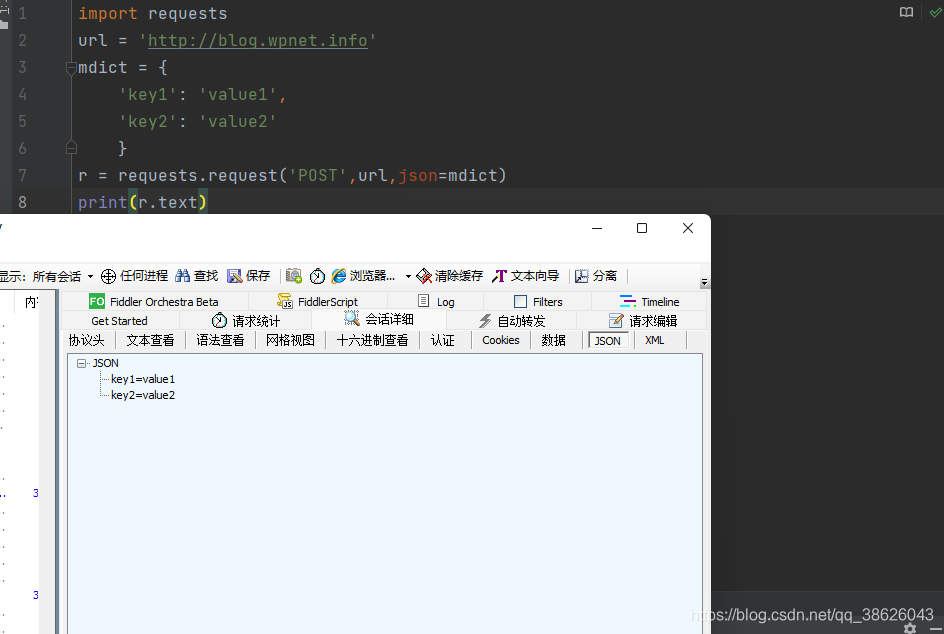
headers:(字典)自定义HTTP头
import requests url = 'http://blog.wpnet.info' mdict = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36' } r = requests.request('get',url,headers= mdict) print(r.text)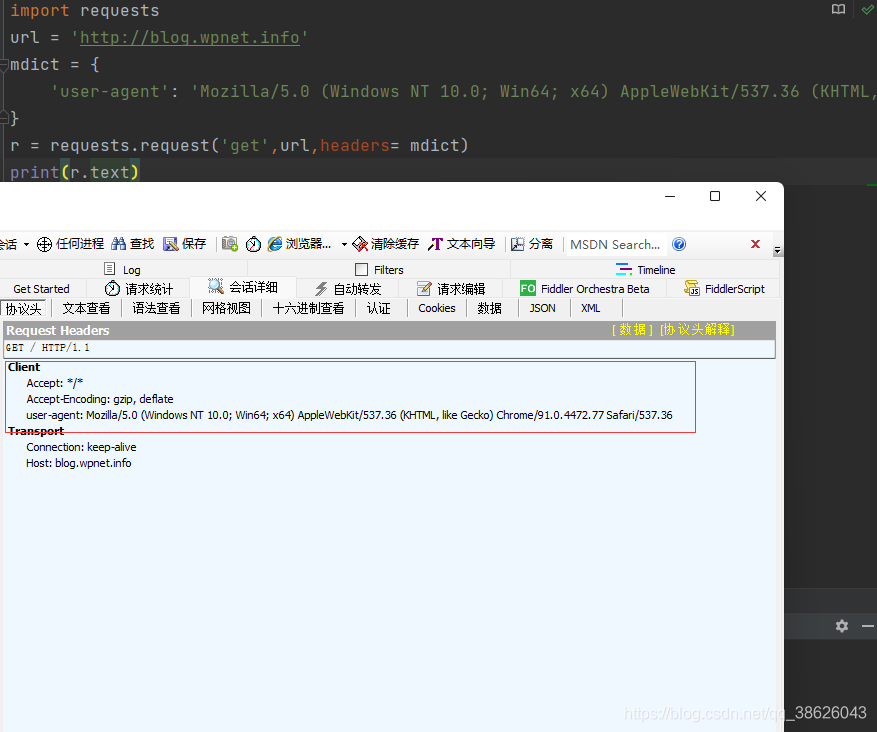
- cookies:(字典或CookieJar)自定义Cookie
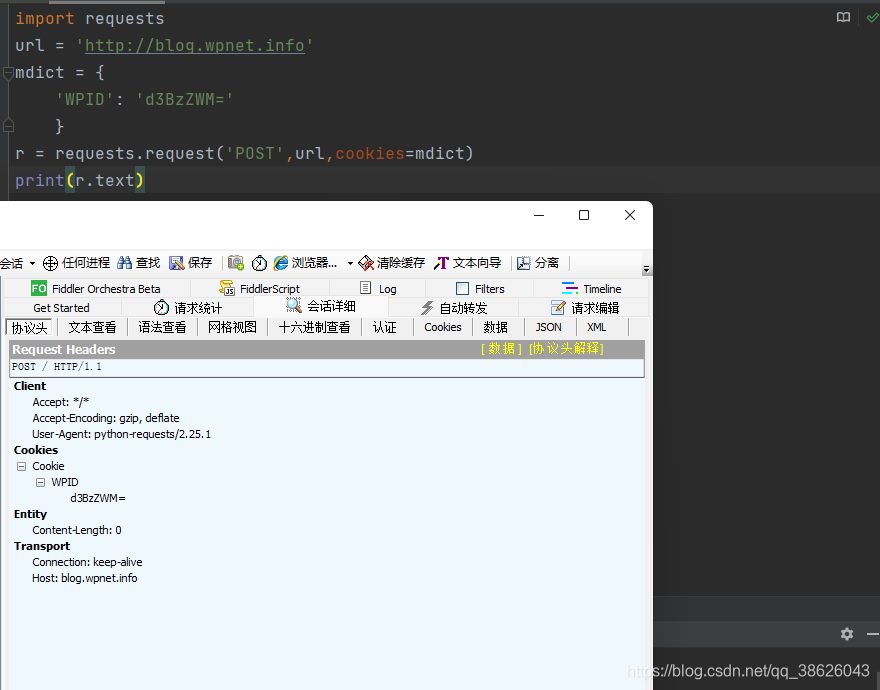
- auth:(元组)HTTP 认证功能
- files:(字典)传输文件
import requests url = 'http://blog.wpnet.info' fp = { 'file':open('test.txt','rb') } r = requests.request('POST',url,files=fp) print(r.text)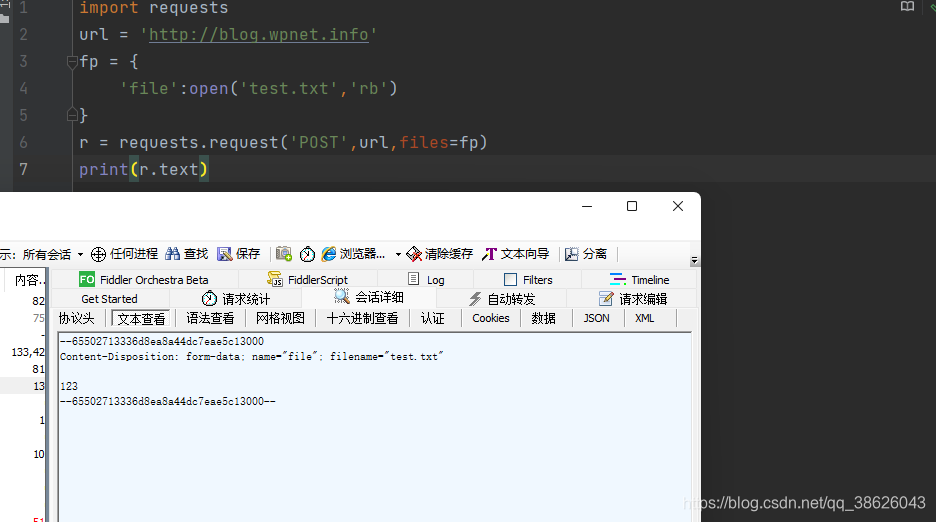
- timeout:(数值)超时,单位秒
- proxies:(字典)设置代理服务器
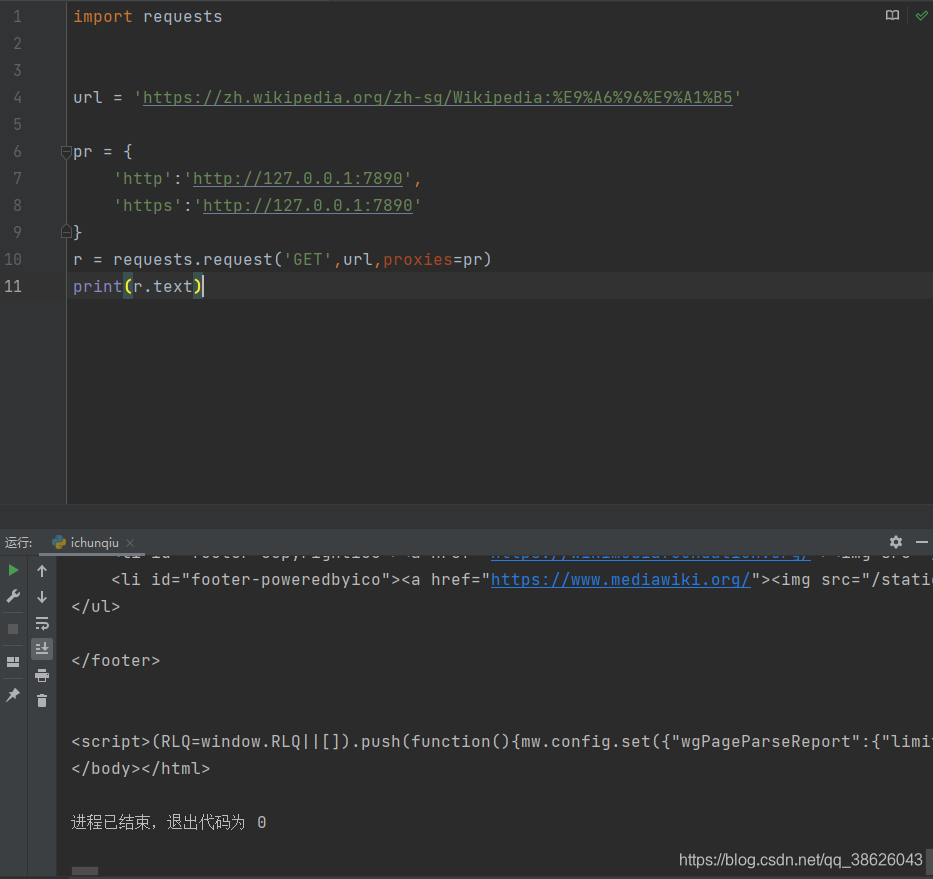
- allow_redirects:(布尔)默认为True,重定向开关
- stream:(布尔)默认为True,获取内容立即下载开关
- verify:(布尔)默认为True,认证 SSL 证书开关
- cert:(字符串)本地 SSL 证书路径
requests.get()
requests.get() 方法提供三个参数
- url:(字符串)目标
- params:(字典,字节流)参数
- **kwargs:12个访问控制参数
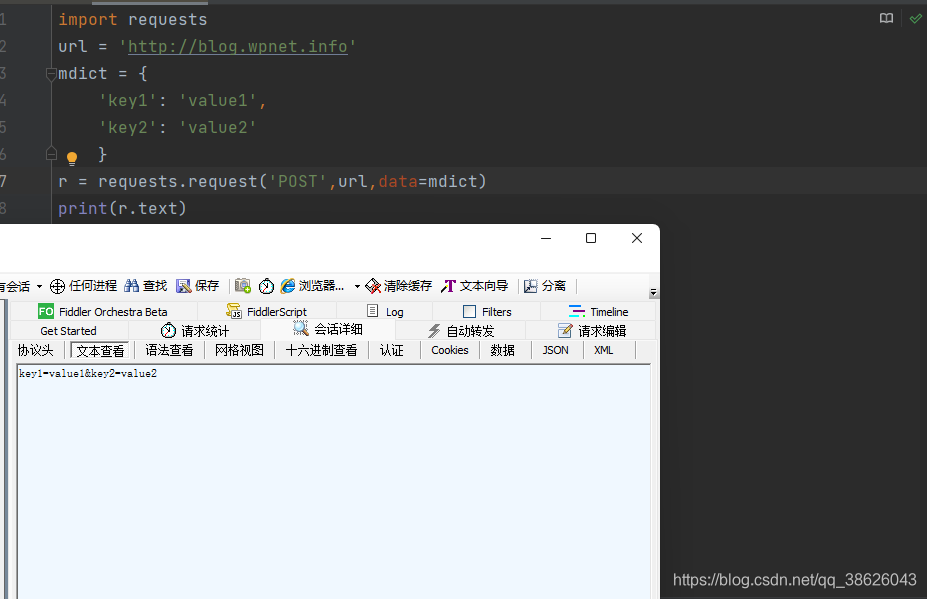
import requests
url = 'http://blog.wpnet.info'
mdict = {
'key1':'value1',
'key2':'value2'
}
r = requests.get(url,params=mdict)
print(r.text)
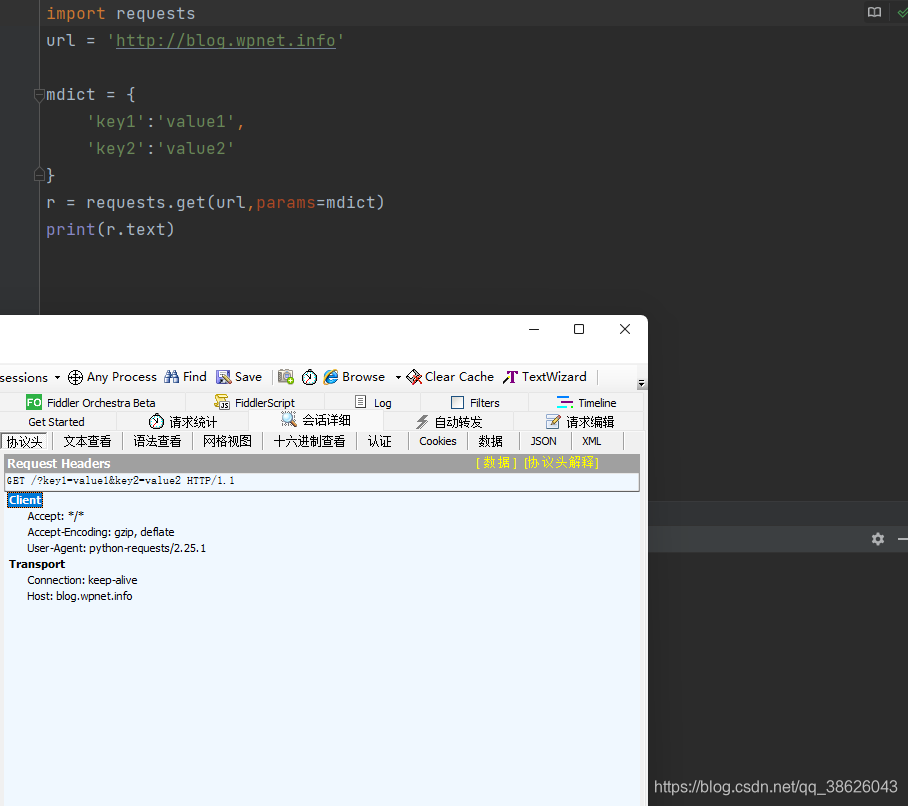
其它方法基本与 requests.request() 参数与控制参数基本上一致
robots 协议
通过基本语法告知爬虫那些目录可以访问,那些不能访问,robots.txt 一定放网站根目录,如果没有robots.txt,代表允许无限制访问以及爬取内容
https://www.baidu.com/robots.txt
* 代表所有
/ 代表根目录
User-agent 代表那些爬虫
Disallow 代表不允许爬虫访问的目录

实例
爬取京东商品
https://item.jd.com/2967929.html
import requests
def getjd(url):
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
r = requests.request('GET',url,headers = header)
status = r.status_code
if status != 200:
print('状态码错误')
exit(0)
if r.encoding == 'ISO-8859-1':
r.encoding = r.apparent_encoding
print(r.text[:1000])
if __name__ == '__main__':
url = 'https://item.jd.com/2967929.html'
getjd(url)
百度360 搜索关键词提交
百度&360api:
https://www.baidu.com/s?wd=keyword
https://www.so.com/s?q=keyword
import requests
def getsearch(url,keyword,select):
header = {
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
if select == '1':
keyword = {'wd':keyword}
elif select == '2':
keyword = {'q':keyword}
r = requests.get(url,params = keyword,headers = header)
if r.status_code != 200:
print('状态错误:',r.status_code)
exit(0)
elif r.encoding == 'ISO-8859-1':
r.encoding = r.apparent_encoding
print(r.text)
if __name__ == '__main__':
# baidu_url = 'https://www.baidu.com/s?wd='
# qihu_url = 'https://www.so.com/s?q='
baidu_url = 'https://www.baidu.com/s'
qihu_url = 'https://www.so.com/s'
keyword = str(input('关键词: '))
while True:
select = input('百度:1 360:2 :')
if select == '2':
# url = qihu_url + keyword
url = qihu_url
break
elif select == '1':
# url = baidu_url + keyword
url = baidu_url
break
elif select == 'exit':
exit(0)
elif select != '1' or '2' or 'exit':
print('输入无效重新输入(exit退出)')
print(select)
getsearch(url,keyword,select)
爬取一个站点的所有图片
import requests
import bs4
import os
def getimage(url):
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.3538.77 Safari/537.36'
}
r = requests.request('GET',url,headers = header)
if r.encoding == 'ISO-8859-1':
r.encoding = r.apparent_encoding
elif r.status_code != 200:
print('状态错误: ',r.status_code)
exit(0)
src = bs4.BeautifulSoup(r.text,'html.parser')
listsrc = src.find_all('img')
listimg = []
for i in listsrc:
listimg.append(i.attrs['src'])
dir = os.getcwd() + r'\images'
if not os.path.exists(dir):
os.mkdir(dir)
for i in listimg:
image = dir + '\\' + i.split(r'/')[-1]
if not os.path.exists(image):
if i.split(r'/')[0] != 'http' or 'https':
i = url + i
image_download = requests.get(i,headers=header)
if image_download.status_code == 200:
try:
with open(image,'wb') as file:
file.write(image_download.content)
except Exception as exc:
print('异常:',exc)
print('正在下载: ',i)
print('ok')
if __name__ == '__main__':
url = 'https://cc.cqcet.edu.cn/'
getimage(url)
API接口解析
接口一般不需要 header 头,数据返回的一般是json格式,进行json反序列化取出即可
import requests
import json
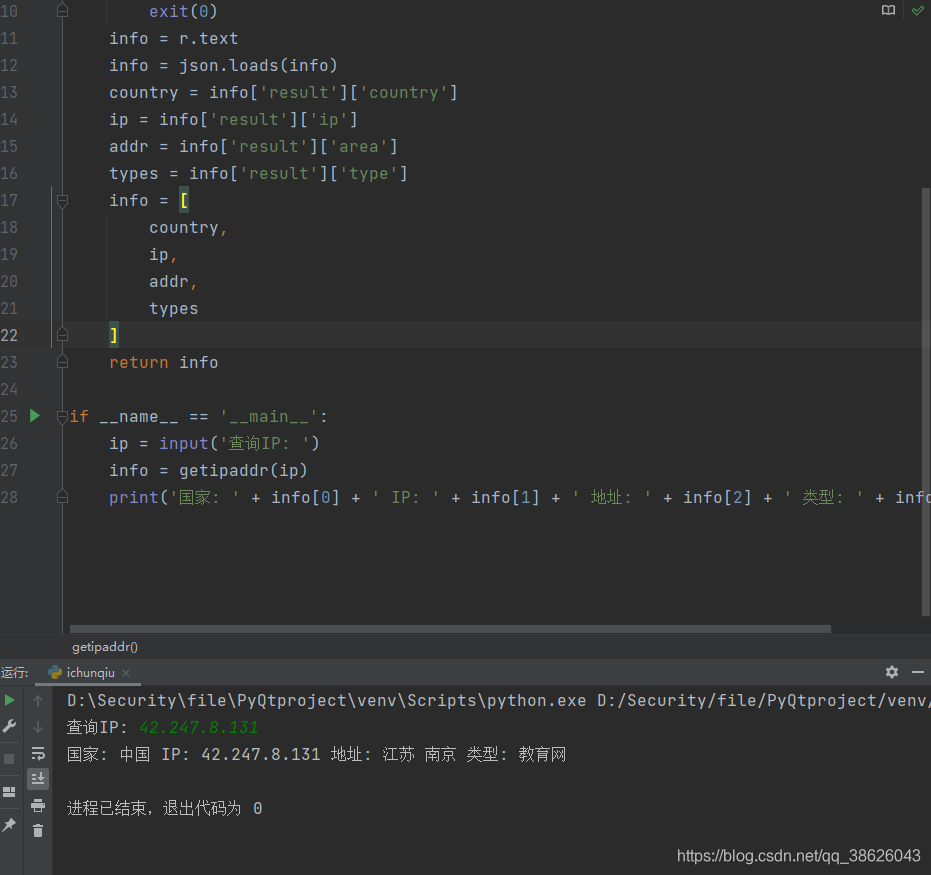
def getipaddr(ip):
key = 'null'
url = f'https://binstd.apistd.com/ip/location?ip={ip}&key={key}'
r = requests.request('GET',url)
if r.status_code != 200:
print('网络故障或 key 错误')
exit(0)
info = r.text
info = json.loads(info)
country = info['result']['country']
ip = info['result']['ip']
addr = info['result']['area']
types = info['result']['type']
info = [
country,
ip,
addr,
types
]
return info
if __name__ == '__main__':
ip = input('查询IP: ')
info = getipaddr(ip)
print('国家: ' + info[0] + ' IP: ' + info[1] + ' 地址: ' + info[2] + ' 类型: ' + info[3])
Beautiful Soup4
bs4 一般搭配 requests 使用或者直接解析 .html 文件,对bs4 中,在实例化之后对自己的处理就是对 html 内容的处理。
简单使用
import requests
import bs4
def getimage(url):
r = requests.request("GET",url)
url_text = r.text
soup = bs4.BeautifulSoup(url_text,'html.parser')
print(soup.prettify())
if __name__ == '__main__':
url = 'http://blog.wpnet.info/'
getimage(url)
soup = bs4.BeautifulSoup(url_text,'html.parser')
使用 Bs4中 BeautifulSoup 以 html解析的方式解析 url_text
bs4库四种解析器
| 解析器 | 条件 |
|---|---|
| bs4的HTML解析器(bs4.BeautifulSoup(url_text,‘html.parser’)) | bs4库自带 |
| lxml的HTML解析器 (bs4.BeautifulSoup(url_text,‘lxml’)) | 安装 lxml |
| lxml的XML解析器 (bs4.BeautifulSoup(url_text,‘xml’)) | 安装 lxml |
| html5lib的解析器 (bs4.BeautifulSoup(url_text,‘html5lib’)) | 安装 html5lib |
bs4 库 基本元素
五种基本元素
| 基本元素 | 说明 |
|---|---|
| tag | 标签 |
| name | 标签名,格式:.name |
| attributes | 标签属性,格式:.attrs |
| navigablestring | 标签内非属性字符串,格式:.string |
| comment | 标签内注释的内容,特殊类型 |
import requests
import bs4
def getimage(url):
r = requests.request("GET",url)
url_text = r.text
soup = bs4.BeautifulSoup(url_text,'html.parser')
# 打印 a 标签
print(soup.a)
# 打印 a 标签的 父标签名字
print(soup.a.parent.name)
# 打印 a 标签 属性
print(soup.a.attrs)
# 打印 a 标签中的 字符串
print(soup.a.string)
if __name__ == '__main__':
url = 'http://blog.wpnet.info/'
getimage(url)
基于bs4 遍历
bs4 的 HTML 标签的遍历分为
- 向下遍历
- 向上遍历
- 平行遍历
向下遍历
| 属性 | 说明 |
|---|---|
| .contents | 一个节点的子节点的列表,将所有子节点存列表 |
| .children | 一个节点的子节点的迭代类型,与 contents 类似 |
| .descendants | 一个节点后所有的子孙节点的迭代类型,包含所有子孙节点 |
import requests
import bs4
def getimage(url):
r = requests.request("GET",url)
url_text = r.text
soup = bs4.BeautifulSoup(url_text,'html.parser')
# 输出 head 标签
# print(soup.head)
# 输出 head 下的 子节点
print(soup.head.contents)
# 输出子 head 下面的 标签数量(子节点数量)
print(len(soup.head.contents))
# 输出第一个 head 下面 的第一个 标签
print(soup.head.contents[1])
# 遍历 head 下的 子标签
for label in soup.head.children:
print(label)
if __name__ == '__main__':
url = 'http://blog.wpnet.info/'
getimage(url)
向上遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 父亲节点的迭代,用于遍历 |
import requests
import bs4
def getimage(url):
r = requests.request("GET",url)
url_text = r.text
soup = bs4.BeautifulSoup(url_text,'html.parser')
# 输出html 标签会输出所有前端内容,因为html上面没有父标签
print(soup.html.parent)
print('--------------------------------')
# 打印 a 标签上层的所有 父类 标签
for label in soup.a.parents:
if label == None:
print(label)
else:
print(label.name)
if __name__ == '__main__':
url = 'http://blog.wpnet.info/'
getimage(url)
平行遍历
平行遍历需要同一个父类标签
平行遍历的下一数据不一定是标签
| 属性 | 说明 |
|---|---|
| .next_sibling | 按HTML 文本顺序的下个平行节点标签 |
| .pravious_sibling | 按HTML 文本顺序的上一个平行标签 |
| .next_siblings | 迭代类型,按HTML 顺序的后续所有平行标签 |
| .previous_siblings | 迭代类型,按HTML 文本顺序的前序所有平行标签 |
prettify 格式化 HTML 信息 以增加可读性
prettify()函数可以在每个标签后面加上换行,从而格式化有些不标准的html 信息,让数据具有跟高的可读性。
import requests
import bs4
def getimage(url):
r = requests.request("GET",url)
url_text = r.text
soup = bs4.BeautifulSoup(url_text,'html.parser')
print(soup)
print('--------------------------------------------')
print(soup.prettify())
if __name__ == '__main__':
url = 'https://python123.io/ws/demo.html'
getimage(url)
信息组织与提取
- 标记后的信息可以形成组织结构,增加信息纬度
- 标记后的信息用于通信,存储
- 标记后的信息便于人类理解
信息标记
国际信息标记一般三种形式
- xml
- json
- yaml
信息提取
信息提取一般方法
完整提取信息,在提取关键信息
– 优点:信息解析准确
– 缺点:效率低,需完全了解信息结构无视标记形式,通过正则等关键字提取
– 优点:提取效率高
– 缺点:需要调试正确内容结合前两种方法
实例
提取一个HTML 中的所有超连接
import requests
import bs4
def getinfo(url):
r = requests.request('GET',url)
if r.status_code != 200:
print('status error:',r.status_code)
exit(0)
r_text = r.text
soup = bs4.BeautifulSoup(r_text,'html.parser')
for i in soup.find_all('a'):
add = str(i.get('href'))
if add.split('//')[0] == 'https:' or add.split('//')[0] == 'http:':
print(add)
else:
print(url+add)
if __name__ == '__main__':
url = 'http://blog.wpnet.info'
getinfo(url)
bs4 库的html 内容查找 find_all
ba4 库中有个 find_all 方法,用于查找对应结果 ,它有 五个参数
find_all(name,attrs,recursive,string,**kwargs)
| 参数 | 作用 |
|---|---|
| name | 对标签名称进行检索 |
| attrs | 对标签属性值检索 |
| recursive | 是否对子孙标签全部检索(默认True) |
| string | 对标签中字符串区域检索 |
find_all 方法的简写
<tag>(...) === <tag>.find_all(...)
soup(...) === soup.find_all(...)
虽然可以这样写,但不建议这样写,可读性并不高
import requests
import bs4
def getinfo(url):
r = requests.request('GET',url,timeout = 5)
if r.status_code != 200:
print('status error:',r.status_code)
exit(0)
r_text = r.text
soup = bs4.BeautifulSoup(r_text,'html.parser')
# 检索 a 标签所有 hover-underline 属性的标签
print(soup.find_all('a','hover-underline'))
# 检索 字符串 信息安全
print(soup.find_all(string = '信息安全'))
# 简写 find_all 方法
print(soup(string='信息安全'))
if __name__ == '__main__':
url = 'http://blog.wpnet.info'
getinfo(url)
bs4 find 系列的其它 七个 方法
除了常用的 find_all() 方法以外的七种方法
| 方法 | 描述 |
|---|---|
| find() | 搜索但只返回一个结果,返回字符串 |
| find_parents() | 在先辈节点中搜索,返回列表 |
| find_parent() | 在先辈节点中搜索但只返回一个结果,返回字符串 |
| find_next_siblings() | 在后续平行节点中搜索,返回列表 |
| find_next_sibling() | 在后续平行节点中搜索但只返回一个结果,返回字符串 |
| find_previous_siblings() | 在前序平行节点中搜索,返回列表 |
| find_previous_sibling() | 在前序平行节点中搜索但只返回一个结果,返回字符串 |
bs4 库的 CSS 选择器 select
soup.select('title') #通过标签获取元素
soup.select('html body p') #获取html下的body标签下的p标签中内容
soup.select('div [class="text"]')[0] #获取 标签为 div 元素为 class="text" 里的内容,类型为Tag
soup.select('div [class="text"]') #同上,但是类型为 ResultSet
实例
校友会中国高等职业院校2021排名定向爬取
ps:截至2021/07/10 校友会 无robots信息,可以合法爬取。
http://www.cuaa.net/paihang/news/news.jsp?information_id=137267
假设我们只需要 2021校友会中国高职院校排名(I类) 这个表里面的信息
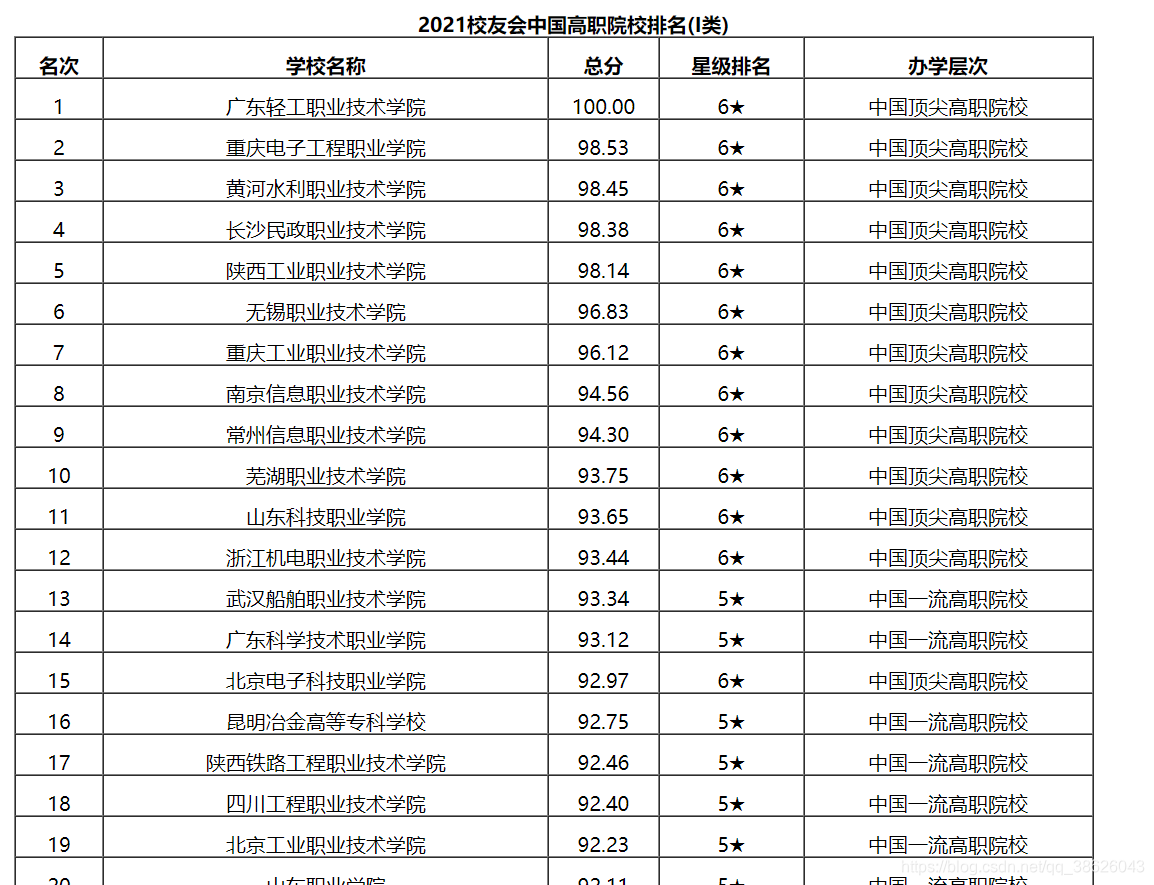
import requests
import bs4
import re
def gettext(url):
header = {
'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
r = requests.request('GET',url,headers = header,timeout = 10)
if r.status_code != 200:
print('status error :',r.status_code)
exit(0)
r.encoding = r.apparent_encoding
url_text = r.text
return url_text
def gethtmllist(html_text):
soup = bs4.BeautifulSoup(html_text,'html.parser')
div_att = soup.find_all(attrs={'class':'text'})[0]
selecttag = div_att.find_all()
for i in selecttag:
if "2021校友会中国高职院校排名(I类)" == i.get_text():
value = bs4.BeautifulSoup(str(selecttag[selecttag.index(i)+6]),'html.parser')
getvalue = value.find(attrs={'align':'center'})
return str(getvalue)
def reg(getvalue):
info_dict = []
rank = re.compile(r'>(.*\d)<')
rank = rank.findall(getvalue)
name = re.compile(r'<td nowrap=\"\" width=\"40%\">\n<p align=\"center\">(.*)</p></td>')
name = name.findall(getvalue)
name.pop(0)
num = re.compile(r'<p align=\"center\">(\d*.*) </p></td>')
num = num.findall(getvalue)
chenci = re.compile(r'<p align=\"center\">(.*)</p></td></tr>')
chenci = chenci.findall(getvalue)
chenci.pop(0)
for n in range(len(name)):
info_dict.append({"校名": name[n], "名次": rank[n],"分数":num[n],"层次":chenci[n]})
sorted(info_dict, key=lambda i: (i["名次"]))
return info_dict
if __name__ == '__main__':
url = 'http://www.cuaa.net/paihang/news/news.jsp?information_id=137267'
html_text = gettext(url)
getvalue = gethtmllist(html_text)
info = reg(getvalue)
print(info)
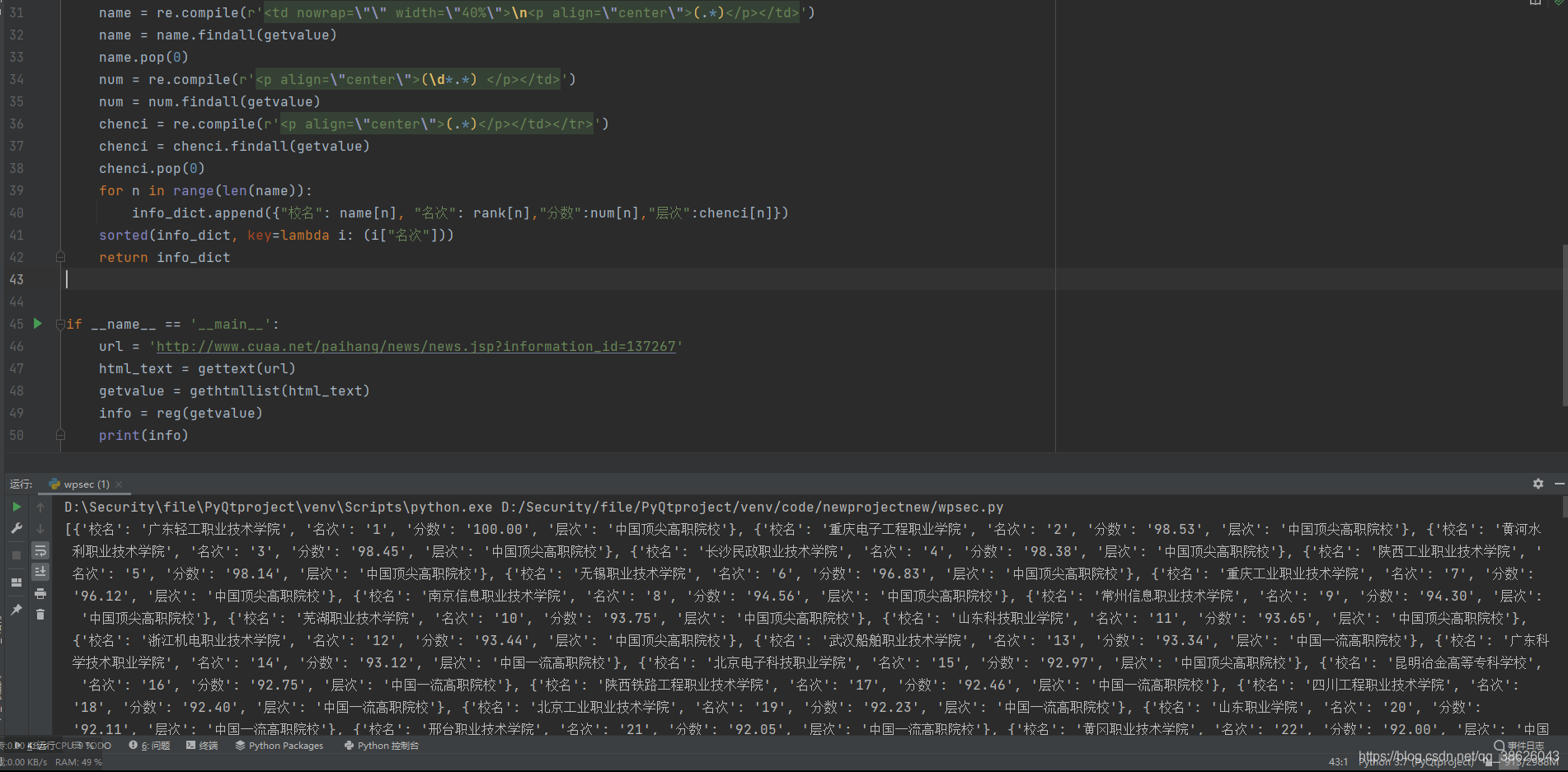
淘宝商品信息定向爬虫
ps:截至2021/07/10 淘宝网 robots信息仅不允许
baiduspider爬取,其它爬虫可以合法爬取。
假设我需要爬取鼠标相关信息,分析 url,每个页面为 44个 商品,参数变量 s 就是商品的编号
第一页:
第二页:
第三页
import requests
import re
def get_text(url):
cookie_str = 'null'
header = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Brave Chrome/90.0.4430.72 Safari/537.36'
}
cookie = {
}
for i in cookie_str.split(';'):
key,value = i.strip().split('=',1)
cookie[key] = value
r = requests.request('GET',url,headers=header,cookies=cookie)
if r.status_code != 200:
print('status_error:',r.status_code)
exit(0)
r.encoding = r.apparent_encoding
return r.text
def get_info(url_text):
# 价格
price = re.compile(r'\"view_price\":\"(\d+\.\d*)')
price = price.findall(url_text)
# 地点
area = re.compile(r'\"item_loc\":\"(\D+)\",')
area = area.findall(url_text)
paynum = re.compile(r'\"view_sales\":\"(.+?)\"')
paynum = paynum.findall(url_text)
name = re.compile(r'\"nick\":\"(\D*)\",')
name = name.findall(url_text)
print(price)
print(area)
print(name)
print(paynum)
print(len(name))
def main():
depth = 2
findname = '鼠标'
url = "https://s.taobao.com/search?q={}".format(findname)
for i in range(depth):
try:
url = url + '&s=' + str(44*i)
url_text = get_text(url)
get_info(url_text)
except:
print('error')
if __name__ == '__main__':
main()
Scrapy 爬虫框架
- Request 类
Request 类 和 Request 库不是一个东西,但跟request库相似
| 属性或方法 | 说明 |
|---|---|
| .url | request对应请求的URL地址 |
| .method | 对应的请求方法,‘GET’'POST’等 |
| .headers | 请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加扩展信息,在scrapy内部模块传递使用 |
| .copy() | 复制该请求 |
- Response类
对应一个HTTP响应,由downloader生成,由 spider 处理
| 属性或方法 | 说明 |
|---|---|
| .url | Response对应的URL地址 |
| .status | HTTP状态码 |
| .headers | 响应头 |
| .body | Response响应内容,字符串类型 |
| .flags | 标记 |
| .request | 产生Response类的对应Request对象 |
| .copy() | 复制该响应 |
- Item类
表示一个HTML页面中提取的信息内容
由 spider 生成,由 Item Pipeline 处理
Item类似字典类型
Scrapy 爬虫 提取信息的方法
- Bs4
- lxml
- re
- Xpath
- CSS select
框架 5+2 结构
五个主要模块
其中 ENGINE SCHEDULER DOWNLOADER 一般无需用户修改
- SPIDERS(常用)
解析downloader返回的 response ,产生爬取项,请求 - ENGINE(核心)
控制所有模块的数据流 - SCHEDULER
调度管理 - DOWNLOADER
根据请求下载网页 - INTERNET
两个中间件
- MIDDLEWARE
对 ENGINE SCHEDULER DOWNLOADER 模块进行用户可配置控制(修改,丢弃,新增请求) - ITEM PIPELINES
以流水线处理 SPIDERS 的 爬取项
框架的数据路径
路径1
路径2
requests 和 scrapy
相同点
- 可用性好,文档丰富
- 均为爬虫
不同点
| requests | scrapy |
|---|---|
| 网页级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性不足 | 性能高 |
| 重点页面下载 | 重点爬虫结构 |
| 定制灵活 | 一般定制灵活,深度困难 |
| 简单 | 相对requests困难 |
scrapy 命令行
scrapy <命令> [参数] [参数]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U9K0EIlI-1626343395582)(en-resource://database/1681:1)]
常用命令
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapt startproject [dir] |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| settings | 获得爬虫配置信息 | scrapy settings [option] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动 URL 调试命令行 | scrapy shell [url] |
实例
- 新建 scrapy 工程
scrapy startproject wpsecblog - 编写 scrapy 爬虫
scrapy genspider wpsec blog.wpnet.info
创建一个工程后会生成一些目录
- scrapy.cfg
部署scrapy爬虫的配置文件 - wpsecblog外层目录
– __init__.py 初始化脚本
– items.py Items 代码模板(继承类)
– middlewares.py Middlewares代码模板(继承类)
– pipelines.py Pipelines代码模板(继承类)
– settings.py scrapy爬虫配置文件
– spiders/ 当前工程的爬虫
创建爬虫后会在 spiders 目录下生成一个你的爬虫
- 修改 spider 内容
爬取一个页面并保存它
import scrapy
class WpsecSpider(scrapy.Spider):
name = 'wpsec'
allowed_domains = ['blog.wpnet.info']
start_urls = ['http://blog.wpnet.info/index.html']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as file:
file.write(response.body)
pass
- 运行
scrapy crawl wpsec
爬取并保存的相关文件
yield 关键字
yield <–>生成器
- 生成器就是一个不断生产的函数
- 包含yield语句的函数是一个生成器
- 生成器每次生产一个值(yield语句),函数被冻结,被唤醒后再生产一个值
摘录
北京理工大学 嵩天-Python网络爬虫与信息提取