在多元线性回归中,并不是所用特征越多越好;选择少量、合适的特征既可以避免过拟合,也可以增加模型解释度。这里介绍3种方法来选择特征:最优子集选择、向前或向后逐步选择、交叉验证法。
最优子集选择
这种方法的思想很简单,就是把所有的特征组合都尝试建模一遍,然后选择最优的模型。基本如下:
- 对于p个特征,从k=1到k=p——
- 从p个特征中任意选择k个,建立C(p,k)个模型,选择最优的一个(RSS最小或R2最大);
- 从p个最优模型中选择一个最优模型(交叉验证误差、Cp、BIC、Adjusted R2等指标)。
这种方法优势很明显:所有各种可能的情况都尝遍了,最后选择的一定是最优;劣势一样很明显:当p越大时,计算量也会越发明显地增大(2^p)。因此这种方法只适用于p较小的情况。
以下为R中ISLR包的Hitters数据集为例,构建棒球运动员的多元线性模型。
> library(ISLR)
> Hitters <- na.omit(Hitters)
> dim(Hitters) # 除去Salary做为因变量,还剩下19个特征
[1] 263 20
> library(leaps)
> regfit.full = regsubsets(Salary~.,Hitters,nvmax = 19) #选择最大19个特征的全子集选择模型
> reg.summary = summary(regfit.full) # 可看到不同数量下的特征选择
> plot(reg.summary$rss,xlab="Number of Variables",ylab="RSS",type = "l") # 特征越多,RSS越小
> plot(reg.summary$adjr2,xlab="Number of Variables",ylab="Adjusted RSq",type = "l")
> points(which.max(reg.summary$adjr2),reg.summary$adjr2[11],col="red",cex=2,pch=20) # 11个特征时,Adjusted R2最大
> plot(reg.summary$cp,xlab="Number of Variables",ylab="Cp",type = "l")
> points(which.min(reg.summary$cp),reg.summary$cp[10],col="red",cex=2,pch=20) # 10个特征时,Cp最小
> plot(reg.summary$bic,xlab="Number of Variables",ylab="BIC",type = "l")
> points(which.min(reg.summary$bic),reg.summary$bic[6],col="red",cex=2,pch=20) # 6个特征时,BIC最小
> plot(regfit.full,scale = "r2") #特征越多,R2越大,这不意外
> plot(regfit.full,scale = "adjr2")
> plot(regfit.full,scale = "Cp")
> plot(regfit.full,scale = "bic")Adjust R2、Cp、BIC是三个用来评价模型的统计量(定义和公式就不写了),Adjust R2越接近1说明模型拟合得越好;其他两个指标则是越小越好。
注意到在这3个指标下,特征选择的结果也不同。这里以Adjust R2为例,以它为指标选出了11个特征:

从图中可见,当Adjusted R2最大(当然也就比0.5多一点,也不怎么样)时,选出的11个特征为:AtBat、Hits、Walks、CAtBat、CRuns、CRBI、CWalks、LeagueN、DivisionW、PutOuts、Assists。
可以直接查看模型的系数:
> coef(regfit.full,11)
(Intercept) AtBat Hits Walks CAtBat
135.7512195 -2.1277482 6.9236994 5.6202755 -0.1389914
CRuns CRBI CWalks LeagueN DivisionW
1.4553310 0.7852528 -0.8228559 43.1116152 -111.1460252
PutOuts Assists
0.2894087 0.2688277 可见这11个特征与图中一致,现在特征筛选出来了,系数也算出来了,模型就已经构建出来了。
逐步回归法
这种方法的思想可以概括为“一条路走到黑”,每一次迭代都只能沿着上一次迭代的方向继续进行,不能反悔,不能丢锅。以向前逐步回归为例,基本过程如下:
- 对于p个特征,从k=1到k=p——
- 从p个特征中任意选择k个,建立C(p,k)个模型,选择最优的一个(RSS最小或R2最大);
- 基于上一步的最优模型的k个特征,再选择加入一个,这样就可以构建p-k个模型,从中最优;
- 重复以上过程,直到k=p迭代完成;
- 从p个模型中选择最优。
向后逐步回归法类似,只是一开始就用p个特征建模,之后每迭代一次就舍弃一个特征是模型更优。
这种方法与最优子集选择法的差别在于,最优子集选择法可以选择任意(k+1)个特征进行建模,而逐步回归法只能基于之前所选的k个特征进行(k+1)轮建模。所以逐步回归法不能保证最优,因为前面的特征选择中很有可能选中一些不是很重要的特征在后面的迭代中也必须加上,从而就不可能产生最优特征组合了。但优势就是计算量大大减小(p*(p+1)/2),因此实用性更强。
> regfit.fwd = regsubsets(Salary~.,data=Hitters,nvmax = 19,method = "forward")
> summary(regfit.fwd) # 显示向前选择过程
Subset selection object
Call: regsubsets.formula(Salary ~ ., data = Hitters, nvmax = 19, method = "forward")
Selection Algorithm: forward
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits
1 ( 1 ) " " " " " " " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " " " " " " "
4 ( 1 ) " " "*" " " " " " " " " " " " " " "
5 ( 1 ) "*" "*" " " " " " " " " " " " " " "
6 ( 1 ) "*" "*" " " " " " " "*" " " " " " "
7 ( 1 ) "*" "*" " " " " " " "*" " " " " " "
8 ( 1 ) "*" "*" " " " " " " "*" " " " " " "
9 ( 1 ) "*" "*" " " " " " " "*" " " "*" " "
10 ( 1 ) "*" "*" " " " " " " "*" " " "*" " "
11 ( 1 ) "*" "*" " " " " " " "*" " " "*" " "
12 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " "
13 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " "
14 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" " "
15 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" "*"
16 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*"
17 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*"
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*"
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*"
CHmRun CRuns CRBI CWalks LeagueN DivisionW PutOuts
1 ( 1 ) " " " " "*" " " " " " " " "
2 ( 1 ) " " " " "*" " " " " " " " "
3 ( 1 ) " " " " "*" " " " " " " "*"
4 ( 1 ) " " " " "*" " " " " "*" "*"
5 ( 1 ) " " " " "*" " " " " "*" "*"
6 ( 1 ) " " " " "*" " " " " "*" "*"
7 ( 1 ) " " " " "*" "*" " " "*" "*"
8 ( 1 ) " " "*" "*" "*" " " "*" "*"
9 ( 1 ) " " "*" "*" "*" " " "*" "*"
10 ( 1 ) " " "*" "*" "*" " " "*" "*"
11 ( 1 ) " " "*" "*" "*" "*" "*" "*"
12 ( 1 ) " " "*" "*" "*" "*" "*" "*"
13 ( 1 ) " " "*" "*" "*" "*" "*" "*"
14 ( 1 ) " " "*" "*" "*" "*" "*" "*"
15 ( 1 ) " " "*" "*" "*" "*" "*" "*"
16 ( 1 ) " " "*" "*" "*" "*" "*" "*"
17 ( 1 ) " " "*" "*" "*" "*" "*" "*"
18 ( 1 ) " " "*" "*" "*" "*" "*" "*"
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*"
Assists Errors NewLeagueN
1 ( 1 ) " " " " " "
2 ( 1 ) " " " " " "
3 ( 1 ) " " " " " "
4 ( 1 ) " " " " " "
5 ( 1 ) " " " " " "
6 ( 1 ) " " " " " "
7 ( 1 ) " " " " " "
8 ( 1 ) " " " " " "
9 ( 1 ) " " " " " "
10 ( 1 ) "*" " " " "
11 ( 1 ) "*" " " " "
12 ( 1 ) "*" " " " "
13 ( 1 ) "*" "*" " "
14 ( 1 ) "*" "*" " "
15 ( 1 ) "*" "*" " "
16 ( 1 ) "*" "*" " "
17 ( 1 ) "*" "*" "*"
18 ( 1 ) "*" "*" "*"
19 ( 1 ) "*" "*" "*"
> regfit.bwd = regsubsets(Salary~.,data=Hitters,nvmax = 19,method = "backward")
> summary(regfit.bwd) # 显示向后选择过程
Subset selection object
Call: regsubsets.formula(Salary ~ ., data = Hitters, nvmax = 19, method = "backward")
Selection Algorithm: backward
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits
1 ( 1 ) " " " " " " " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " " " " " " "
4 ( 1 ) "*" "*" " " " " " " " " " " " " " "
5 ( 1 ) "*" "*" " " " " " " "*" " " " " " "
6 ( 1 ) "*" "*" " " " " " " "*" " " " " " "
7 ( 1 ) "*" "*" " " " " " " "*" " " " " " "
8 ( 1 ) "*" "*" " " " " " " "*" " " " " " "
9 ( 1 ) "*" "*" " " " " " " "*" " " "*" " "
10 ( 1 ) "*" "*" " " " " " " "*" " " "*" " "
11 ( 1 ) "*" "*" " " " " " " "*" " " "*" " "
12 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " "
13 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " "
14 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" " "
15 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" "*"
16 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*"
17 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*"
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*"
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*"
CHmRun CRuns CRBI CWalks LeagueN DivisionW PutOuts
1 ( 1 ) " " "*" " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " "*"
4 ( 1 ) " " "*" " " " " " " " " "*"
5 ( 1 ) " " "*" " " " " " " " " "*"
6 ( 1 ) " " "*" " " " " " " "*" "*"
7 ( 1 ) " " "*" " " "*" " " "*" "*"
8 ( 1 ) " " "*" "*" "*" " " "*" "*"
9 ( 1 ) " " "*" "*" "*" " " "*" "*"
10 ( 1 ) " " "*" "*" "*" " " "*" "*"
11 ( 1 ) " " "*" "*" "*" "*" "*" "*"
12 ( 1 ) " " "*" "*" "*" "*" "*" "*"
13 ( 1 ) " " "*" "*" "*" "*" "*" "*"
14 ( 1 ) " " "*" "*" "*" "*" "*" "*"
15 ( 1 ) " " "*" "*" "*" "*" "*" "*"
16 ( 1 ) " " "*" "*" "*" "*" "*" "*"
17 ( 1 ) " " "*" "*" "*" "*" "*" "*"
18 ( 1 ) " " "*" "*" "*" "*" "*" "*"
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*"
Assists Errors NewLeagueN
1 ( 1 ) " " " " " "
2 ( 1 ) " " " " " "
3 ( 1 ) " " " " " "
4 ( 1 ) " " " " " "
5 ( 1 ) " " " " " "
6 ( 1 ) " " " " " "
7 ( 1 ) " " " " " "
8 ( 1 ) " " " " " "
9 ( 1 ) " " " " " "
10 ( 1 ) "*" " " " "
11 ( 1 ) "*" " " " "
12 ( 1 ) "*" " " " "
13 ( 1 ) "*" "*" " "
14 ( 1 ) "*" "*" " "
15 ( 1 ) "*" "*" " "
16 ( 1 ) "*" "*" " "
17 ( 1 ) "*" "*" "*"
18 ( 1 ) "*" "*" "*"
19 ( 1 ) "*" "*" "*" 需要注意的是,全子集回归、向前逐步回归和向后逐步回归的特征选择结果可能不同:
> coef(regfit.full,7)
(Intercept) Hits Walks CAtBat CHits
79.4509472 1.2833513 3.2274264 -0.3752350 1.4957073
CHmRun DivisionW PutOuts
1.4420538 -129.9866432 0.2366813
> coef(regfit.fwd,7)
(Intercept) AtBat Hits Walks CRBI
109.7873062 -1.9588851 7.4498772 4.9131401 0.8537622
CWalks DivisionW PutOuts
-0.3053070 -127.1223928 0.2533404
> coef(regfit.bwd,7)
(Intercept) AtBat Hits Walks CRuns
105.6487488 -1.9762838 6.7574914 6.0558691 1.1293095
CWalks DivisionW PutOuts
-0.7163346 -116.1692169 0.3028847 交叉验证法
交叉验证法是机器学习中一个普适的检验模型偏差和方差的方法,并不局限于具体的模型本身。这里介绍一种折中的k折交叉验证法,过程如下:
- 将样本随机划入k(一般取10)个大小接近的折(fold)
- 取第i(1<=i<=k)折的样本作为验证集,其它作为训练集训练模型
- k个模型的验证误差的均值即作为模型的总体验证误差
k-fold CV比留一交叉验证法(LOOCV)的优势有两点:1、计算量小,LOOCV要计算n次,k-fold只需计算k次;2、LOOCV每次只留一个样本作为验证集,相当于差不多还是把全部整体作为训练集,这样每次拟合的模型都差不多,而且很容易造成过拟合,使验证误差方差过大。k-fold没有用那么多的样本来训练,可以有效避免过拟合的问题。
所以对于不同数量的特征,都可以用k折交叉验证法求一个验证误差,最后比较验证误差与特征数量的关系(同样,这种思想方法也不仅局限于线性模型)。
> set.seed(1)
> # 随机划分训练集和测试集
> train = sample(c(T,F),nrow(Hitters),rep=T)
> test = !train
>
> # 训练集上进行全子集最优回归
> regfit.best = regsubsets(Salary~.,data = Hitters[train,],nvmax = 19)
> test.mat = model.matrix(Salary~.,data = Hitters[test,])
>
> val.errors = rep(NA,19)
>
> for(i in 1:19){
+ coefi = coef(regfit.best,id=i)
+ pred = test.mat[,names(coefi)]%*%coefi # 这一步用向量乘法来计算测试集的预测值
+ val.errors[i] = mean((Hitters$Salary[test]-pred)^2) # 计算MSE
+ }
>
> val.errors
[1] 220968.0 169157.1 178518.2 163426.1 168418.1 171270.6
[7] 162377.1 157909.3 154055.7 148162.1 151156.4 151742.5
[13] 152214.5 157358.7 158541.4 158743.3 159972.7 159859.8
[19] 160105.6
> which.min(val.errors)
[1] 10
> coef(regfit.best,10)
(Intercept) AtBat Hits Walks CAtBat
-80.2751499 -1.4683816 7.1625314 3.6430345 -0.1855698
CHits CHmRun CWalks LeagueN DivisionW
1.1053238 1.3844863 -0.7483170 84.5576103 -53.0289658
PutOuts
0.2381662 上例是将样本随机分为训练集和测试集,然后在训练集上按不同特征数通过全子集回归构建模型并计算不同特征数下的MSE,可见10个特征下MSE最小。
下面用k-折交叉验证法来选择特征:
> k = 10
> set.seed(1)
> folds = sample(1:k,nrow(Hitters),replace = T) # 将样本可重复地划入10折中
> table(folds) # 大致差不多
folds
1 2 3 4 5 6 7 8 9 10
13 25 31 32 33 27 26 30 22 24
> cv.errors = matrix(NA,k,19,dimnames = list(NULL,paste(1:19))) # 构建一个k*19的矩阵来存放测试误差。每一行代表一折,每一列代表特征数
>
> for(j in 1:k){
+ best.fit = regsubsets(Salary~.,data = Hitters[folds!=j,],nvmax = 19) # 以第j折以外的训练集作全子集最优回归
+ for(i in 1:19){ # 计算分别取1-19个特征下的MSE
+ pred = predict(best.fit,Hitters[folds==j,],id=i)
+ cv.errors[j,i] = mean((Hitters$Salary[folds==j]-pred)^2)
+ }
+ }
>
> cv.errors
1 2 3 4 5 6
[1,] 187479.08 141652.61 163000.36 169584.40 141745.39 151086.36
[2,] 96953.41 63783.33 85037.65 76643.17 64943.58 56414.96
[3,] 165455.17 167628.28 166950.43 152446.17 156473.24 135551.12
[4,] 124448.91 110672.67 107993.98 113989.64 108523.54 92925.54
[5,] 136168.29 79595.09 86881.88 94404.06 89153.27 83111.09
[6,] 171886.20 120892.96 120879.58 106957.31 100767.73 89494.38
[7,] 56375.90 74835.19 72726.96 59493.96 64024.85 59914.20
[8,] 93744.51 85579.47 98227.05 109847.35 100709.25 88934.97
[9,] 421669.62 454728.90 437024.28 419721.20 427986.39 401473.33
[10,] 146753.76 102599.22 192447.51 208506.12 214085.78 224120.38
7 8 9 10 11 12
[1,] 193584.17 144806.44 159388.10 138585.25 140047.07 158928.92
[2,] 63233.49 63054.88 60503.10 60213.51 58210.21 57939.91
[3,] 137609.30 146028.36 131999.41 122733.87 127967.69 129804.19
[4,] 104522.24 96227.18 93363.36 96084.53 99397.85 100151.19
[5,] 86412.18 77319.95 80439.75 75912.55 81680.13 83861.19
[6,] 94093.52 86104.48 84884.10 80575.26 80155.27 75768.73
[7,] 62942.94 60371.85 61436.77 62082.63 66155.09 65960.47
[8,] 90779.58 77151.69 75016.23 71782.40 76971.60 77696.55
[9,] 396247.58 381851.15 369574.22 376137.45 373544.77 382668.48
[10,] 214037.26 169160.95 177991.11 169239.17 147408.48 149955.85
13 14 15 16 17 18
[1,] 161322.76 155152.28 153394.07 153336.85 153069.00 152838.76
[2,] 59975.07 58629.57 58961.90 58757.55 58570.71 58890.03
[3,] 133746.86 135748.87 137937.17 140321.51 141302.29 140985.80
[4,] 103073.96 106622.46 106211.72 107797.54 106288.67 106913.18
[5,] 85111.01 84901.63 82829.44 84923.57 83994.95 84184.48
[6,] 76927.44 76529.74 78219.76 78256.23 77973.40 79151.81
[7,] 66310.58 70079.10 69553.50 68242.10 68114.27 67961.32
[8,] 78460.91 81107.16 82431.25 82213.66 81958.75 81893.97
[9,] 375284.60 376527.06 374706.25 372917.91 371622.53 373745.20
[10,] 194397.12 194448.21 174012.18 172060.78 184614.12 184397.75
19
[1,] 153197.11
[2,] 58949.25
[3,] 140392.48
[4,] 106919.66
[5,] 84284.62
[6,] 78988.92
[7,] 67943.62
[8,] 81848.89
[9,] 372365.67
[10,] 183156.97
>
> mean.cv.errors = apply(cv.errors,2,mean) # 计算各特征数下10折的平均MSE
> mean.cv.errors
1 2 3 4 5 6 7
160093.5 140196.8 153117.0 151159.3 146841.3 138302.6 144346.2
8 9 10 11 12 13 14
130207.7 129459.6 125334.7 125153.8 128273.5 133461.0 133974.6
15 16 17 18 19
131825.7 131882.8 132750.9 133096.2 132804.7
> plot(mean.cv.errors,type = "b")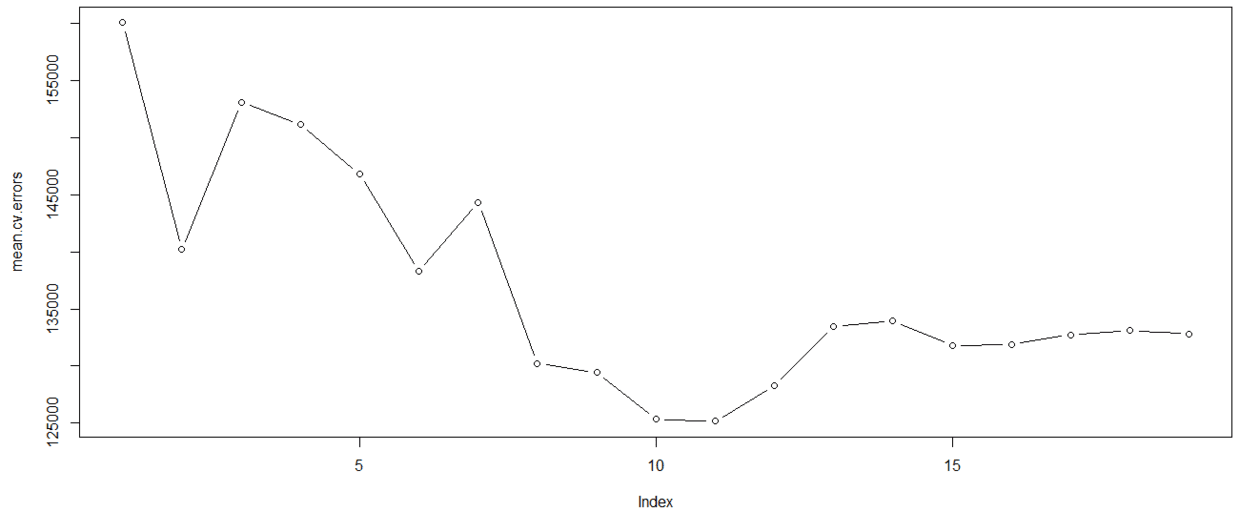
可见交叉验证的结果是选择11个特征。
那么就可以对整个数据集进行全子集回归,选择11变量结果了。
> reg.best = regsubsets(Salary~.,data = Hitters,nvmax = 19)
> coef(reg.best,11)
(Intercept) AtBat Hits Walks CAtBat
135.7512195 -2.1277482 6.9236994 5.6202755 -0.1389914
CRuns CRBI CWalks LeagueN DivisionW
1.4553310 0.7852528 -0.8228559 43.1116152 -111.1460252
PutOuts Assists
0.2894087 0.2688277 转载于:https://www.cnblogs.com/lafengdatascientist/p/7168507.html