函数式接口:
接口中只有一个抽象方法,可使用
@FunctionalInterface注解表明。使用后,接口中添加第二个抽象方法会报错。4大内置核心函数式接口
Consumer<T>:消费型接口 void accept(T t);Supplier<T>:供给型接口 T get();Function<T,R>:函数型接口,T为参数,R为返回值 R apply(T t);Predicate<T>:断言型接口 boolean test(T t);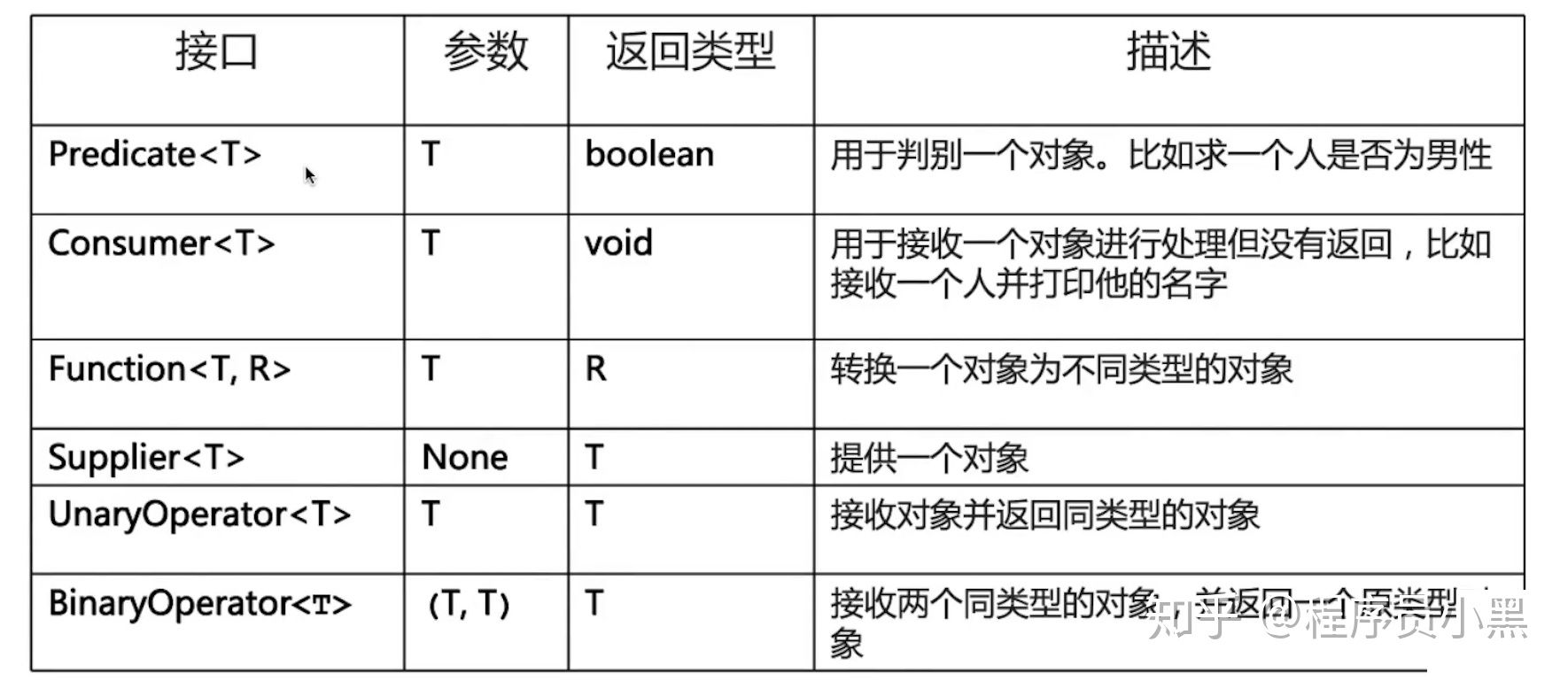
Stream流
Stream的三个操作步骤1.创建Stream2.中间操作(不会执行)3.中止操作(一次性执行全部内容,即“惰性求值”)。
创建Stream
可以通过Collection系列集合提供的
stream()或parallelStream();List<String> list = new ArrayList<>(); Stream<String> stream = list.stream();通过
Arrays中的静态方法stream()获取数组流Employee[] emps = new Employee[10]; Stream<Employee> stream = Arrays.stream(emps);通过
Stream类中的静态方法of()Stream<String> stream = Stream.of("aa","bb","cc");创建无限流
Stream<Integer> stream = Stream.iterate(0,x->x+2);//迭代 Stream.generate(()->Math.random());//生成
中间操作
filter()——接收lambda,从流中排除某些元素。limit(n)——截断流,使元素不超过给定数量,短路执行,找到满足限制的元素即停止迭代。skip(n)——跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit(n)互补。distinect——筛选,通过流所生成元素的hashCode()和equals()去除元素。map——接收lambda,将元素转换成其他形式或提取信息。接收一个函数作为参数,该参数会被应用到每个元素上,并将其映射成一个新的元素。list.stream().map(str->str.toUpperCase()).forEach(System.out::println);//接收lambda employees.stream().map(Employee::getName).forEach(System.out::println);//接收函数flatMap——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。和map的区别类似add(Object obj)和addAll(Collection col),前者把集合中的元素依次加入,后者把集合直接加入。
String[] str = {"hello", "worlds"};
List<String[]> c1 = Arrays.stream(str)
.map(w -> w.split(""))
.collect(Collectors.toList());
//c1=[h,e,l,l,o],[w.o.r.l.d.s]
List<String> c2 = Arrays.stream(str)
.map(w -> w.split(""))
.flatMap(Arrays::stream)
.collect(Collectors.toList());
//c2=[h,e,l,l,o,w.o.r.l.d.s]
sorted()——自然排序(Comparable)sorted(Comparator com)——定制排序(Comparator)
中止操作
查找与匹配
allMatch——检查是否匹配所有元素,类似SQL的allanyMatch——检查是否至少匹配一个元素,类似SQL的anynoneMatch——检查是否没有匹配所有元素findFirst——返回第一个元素,得到的是Optional容器类findAny——返回当前流中的任意元素count——返回流中的元素的总个数max——返回流中最大值min——返回流中最小值
规约
reduce(T identity 起始值,BinaryOperator) 返回值T/reduce(BinararyOperator) 返回值Optional<T>——可以将流中的元素反复结合起来,得到一个值。BinaryOperator属于Function系列。map(提取)-reduce(规约)模式较出名。
List<Integer> list = Arrays.asList(1,2,3,4,5);
Integer sum = list.stream().reduce(0,(x,y)->x+y);
//reduce(BinararyOperator)有可能会产生空指针,所以会返回Optional容器类,上面不会产生空指针(起始值为0)
0为起始值,赋值给x,list中的1赋值给y ,得到的结果1赋值给x,list的2赋值给y,以此循环。每次计算的结果作为x。
收集
collect——将流转换为其他形式,接收一个Collector接口的实现,用于给Stream中元素做汇总处理。提供了一个Collectors类,可转list,set等等。如果想转更具体的,例如HashSet,则需要用toCollection(Supplier<C> collectionFactory 供给型)方法。
list.stream().collect(Collectors.toCollection(HashSet::new));
List list = Arrays.asList(“jack”, “jack”, “alice”, “mark”);
#### Collectors
##### Collectors.toList()
```java
List<String> listResult = list.stream().collect(Collectors.toList());
将stream转换为list。这里转换的list是ArrayList,如果想要转换成特定的list,需要使用toCollection方法。
Collectors.toSet()
Set<String> setResult = list.stream().collect(Collectors.toSet());
toSet将Stream转换成为set。
上面的toMap,toSet转换出来的都是特定的类型,如果我们需要自定义,则可以使用
toCollection()
List<String> custListResult = list.stream().collect(Collectors.toCollection(LinkedList::new));
上面的例子,我们转换成了LinkedList。
Collectors.collectingAndThen()
collectingAndThen允许我们对生成的集合再做一次操作。
List<String> collectAndThenResult = list.stream()
.collect(Collectors.collectingAndThen(
Collectors.toList(), l -> {return new ArrayList<>(l);}));
Collectors.joining()
Joining用来连接stream中的元素:
String joinResult = list.stream().collect(Collectors.joining());
//3个参数依次:前缀,连接,后缀
String res = list.stream().collect(Collectors.joining("-","",""));
Collectors.counting()
counting主要用来统计stream中元素的个数:
Long countResult = list.stream().collect(Collectors.counting());
Collectors.summarizingDouble/Long/Int()
SummarizingDouble/Long/Int为stream中的元素生成了统计信息,返回的结果是一个统计类:
IntSummaryStatistics intResult = list.stream()
.collect(Collectors.summarizingInt(String::length));
//IntSummaryStatistics{count=4, sum=17, min=4, average=4.250000, max=5}
Collectors.averagingDouble/Long/Int()
averagingDouble/Long/Int()对stream中的元素做平均:
Double averageResult = list.stream().collect(Collectors.averagingInt(String::length));
Collectors.summingDouble/Long/Int()
summingDouble/Long/Int()对stream中的元素做sum操作:
Double summingResult = list.stream().collect(Collectors.summingDouble(String::length));
Collectors.maxBy()/minBy()
maxBy()/minBy()根据提供的Comparator,返回stream中的最大或者最小值:
Optional<String> maxByResult = list.stream().collect(Collectors.maxBy(Comparator.naturalOrder()));
Collectors.groupingBy()
GroupingBy根据某些属性进行分组,并返回一个Map:
Map<Integer, Set<String>> groupByResult = list.stream()
.collect(Collectors.groupingBy(String::length, Collectors.toSet()));
//{4=[jack, mark], 5=[alice]}
Collectors.partitioningBy() 分区
PartitioningBy是一个特别的groupingBy,PartitioningBy返回一个Map,这个Map是以boolean值为key,从而将stream分成两部分,一部分是匹配PartitioningBy条件的,一部分是不满足条件的:
Map<Boolean, List<String>> partitionResult = list.stream()
.collect(Collectors.partitioningBy(s -> s.length() > 3));
//{false=[bob], true=[jack, alice, mark]}