hadoop
1.hadoop部署
创立一个 hadoop用户 切换
**下载 解压 安装包 和 jdk **
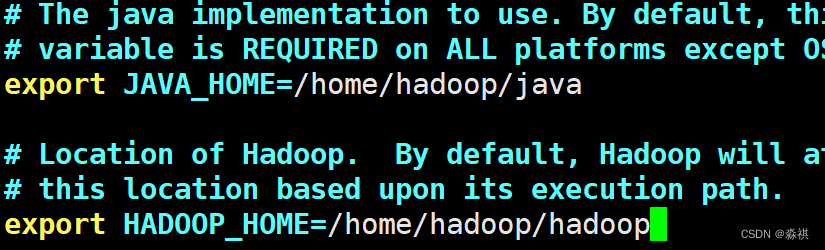
安装后 修改 配置文件
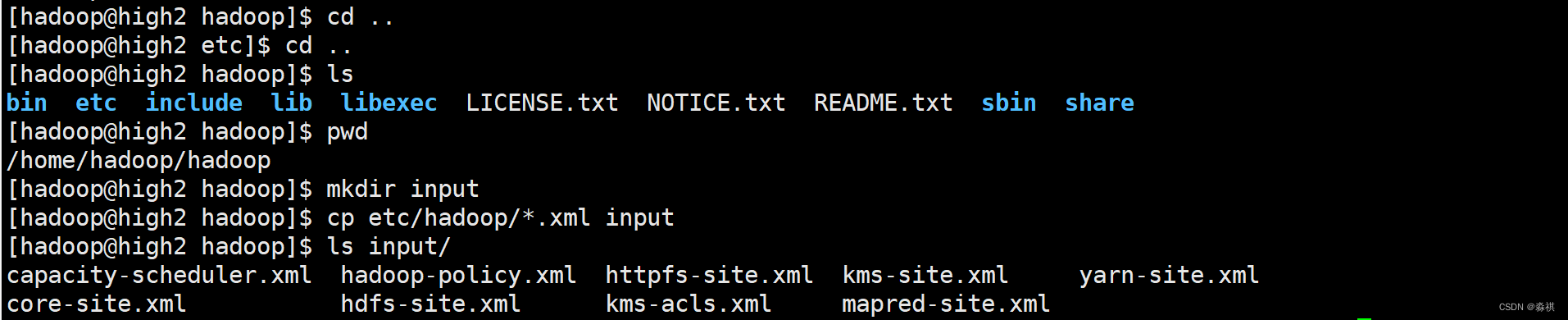
创建目录 复制一些文件
直接调用 java压缩包




2.伪分布式部署
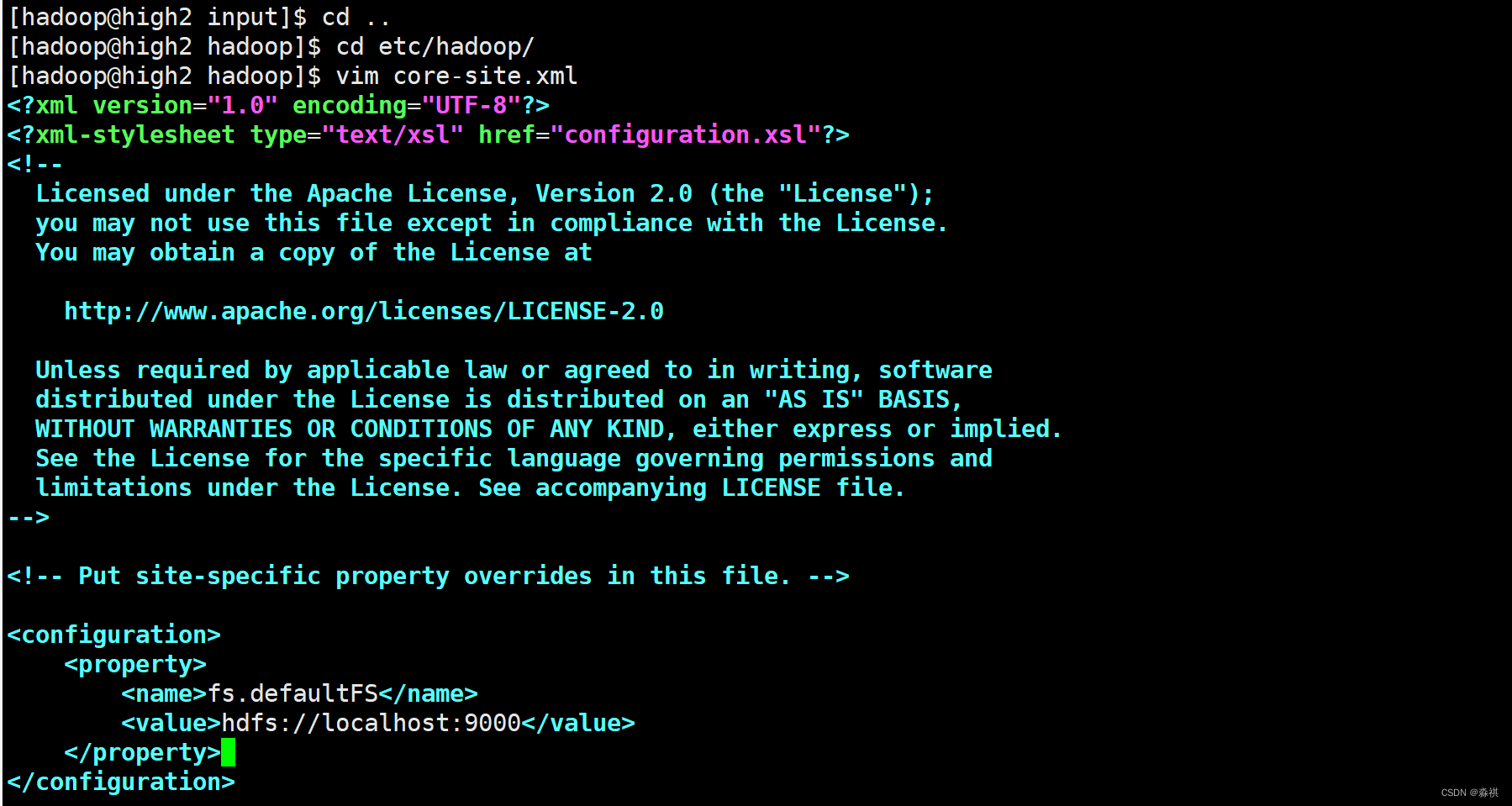
修改配置文件
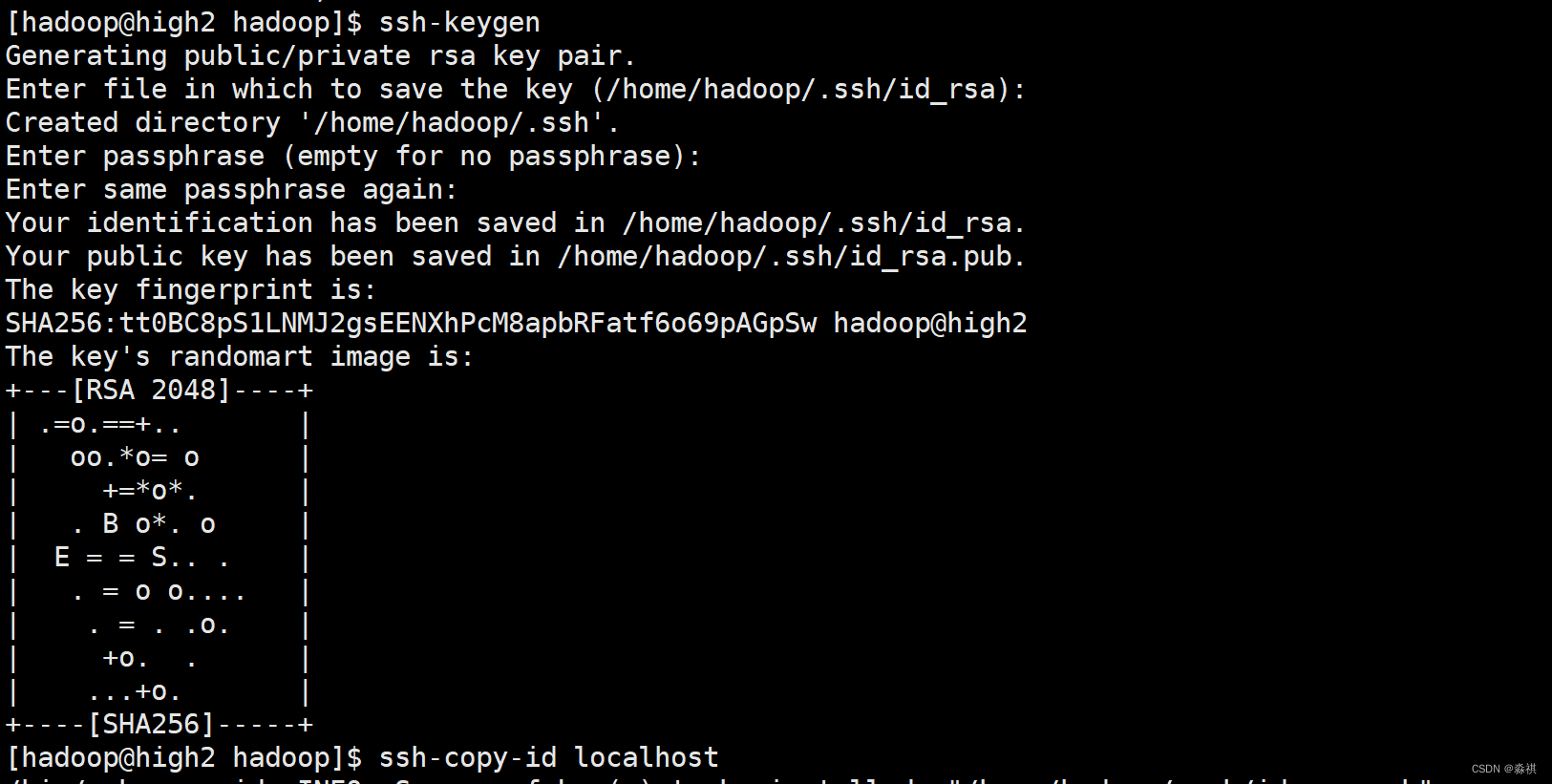
给localhost设置免密认证
格式化
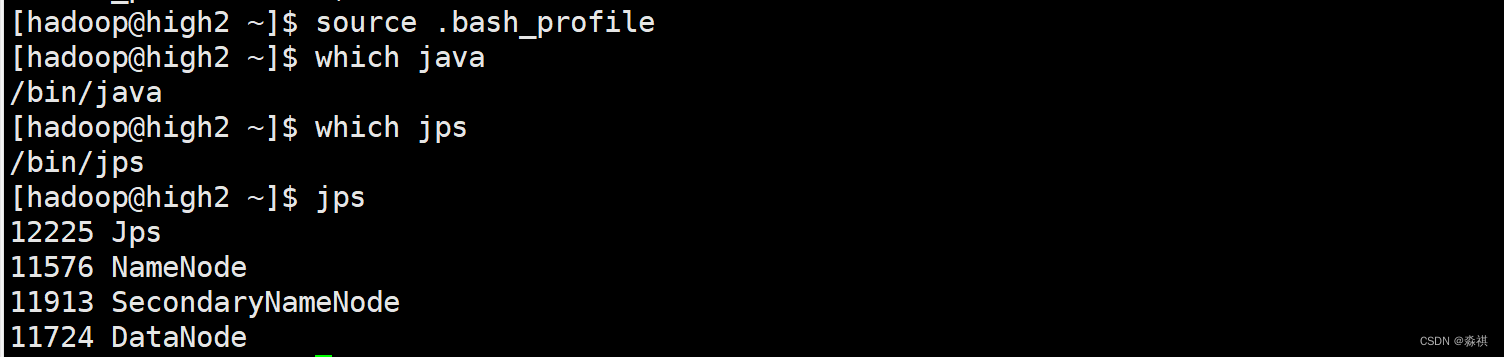
调用 启动脚本
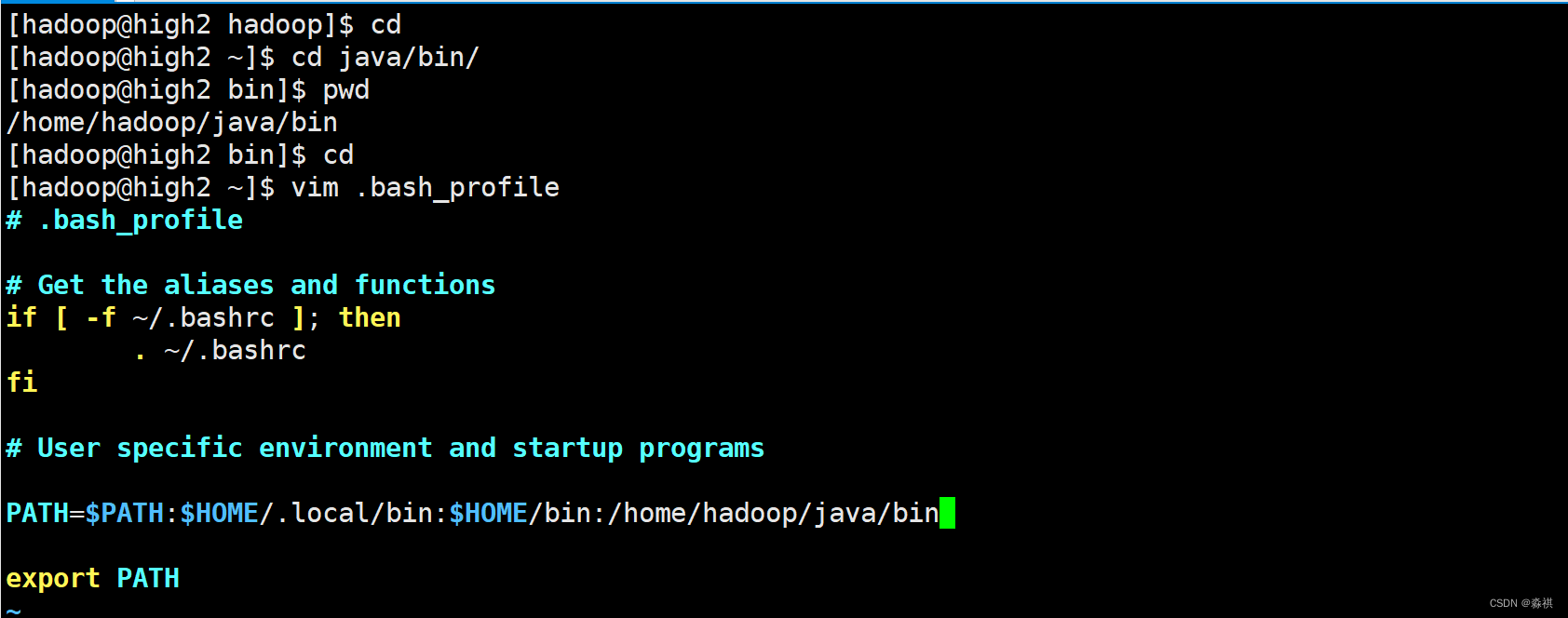
更改下环境变量
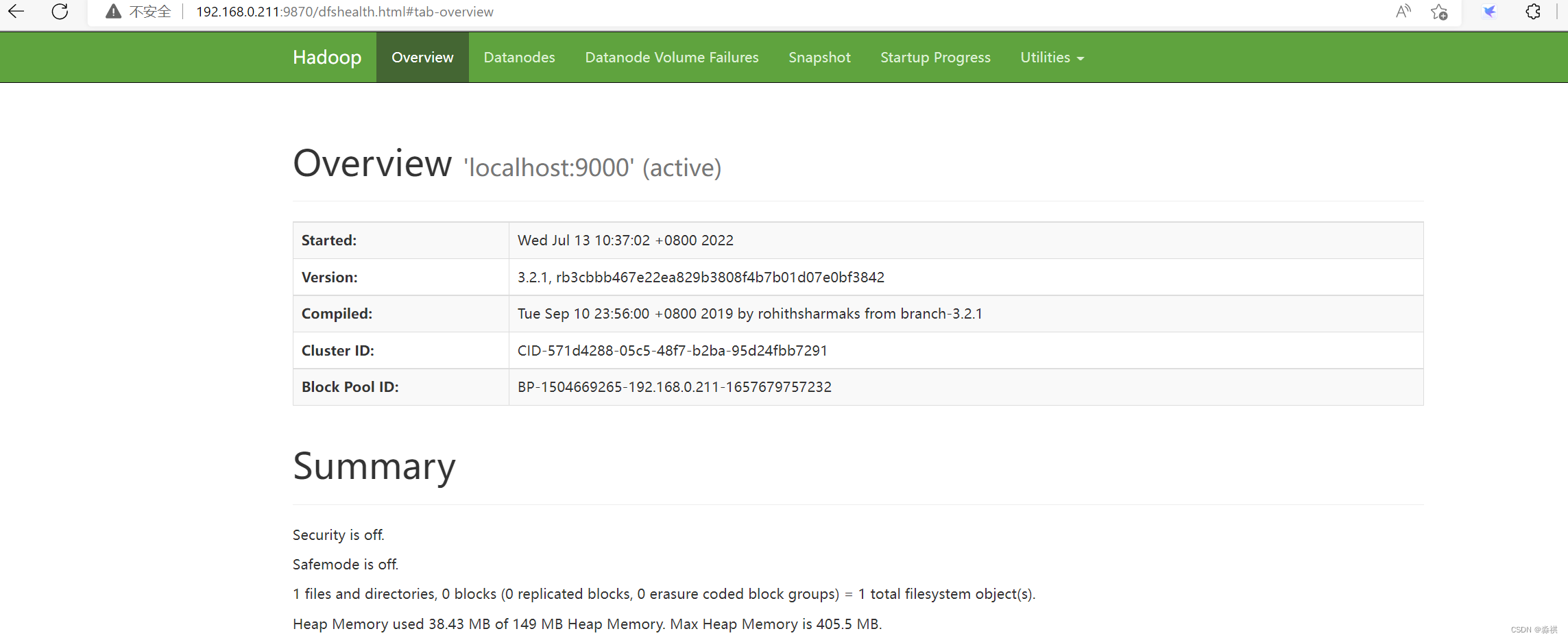
可以使用网页 9870端口打开
使用命令更改分布式发布目录
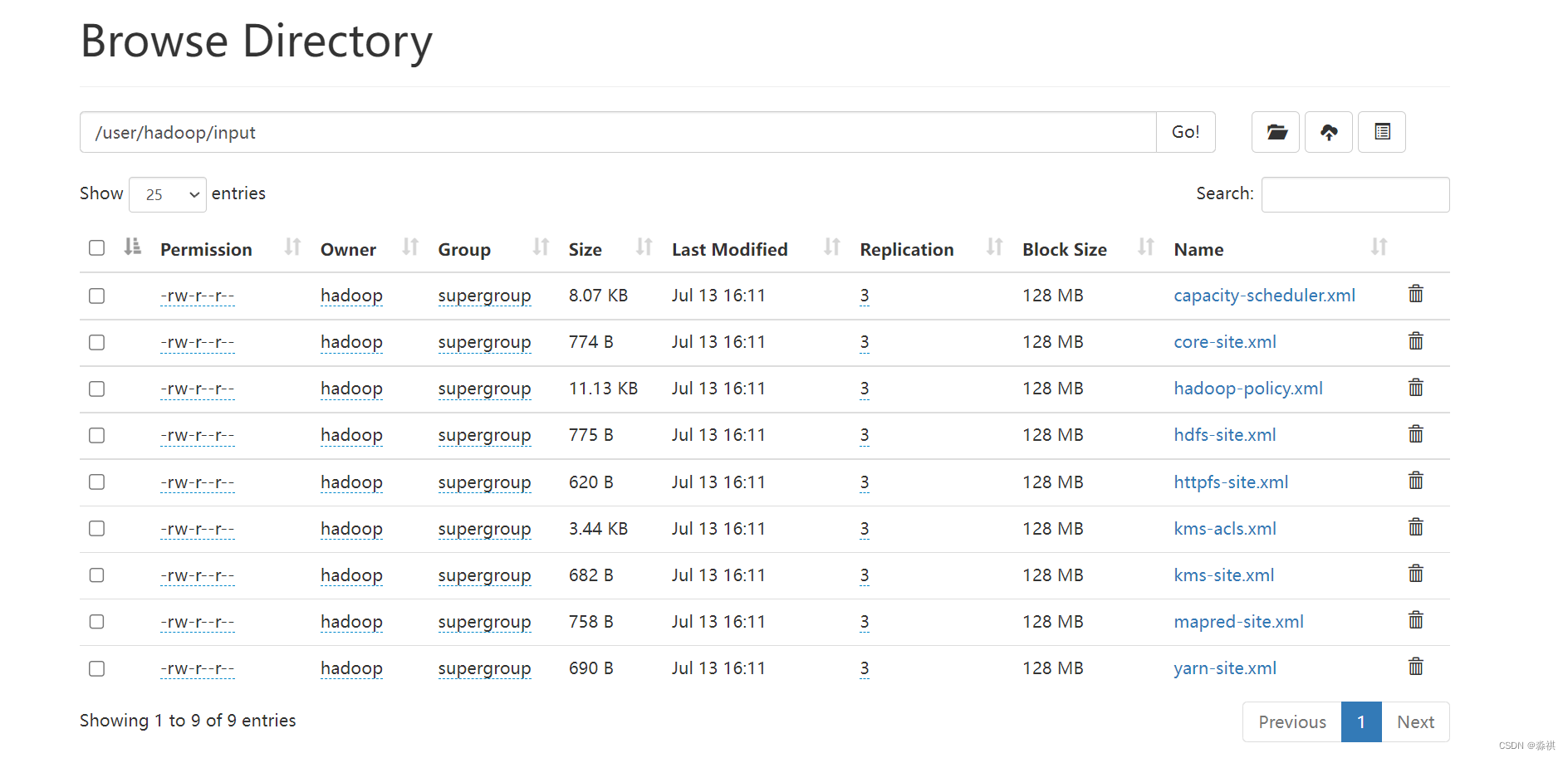
上传input
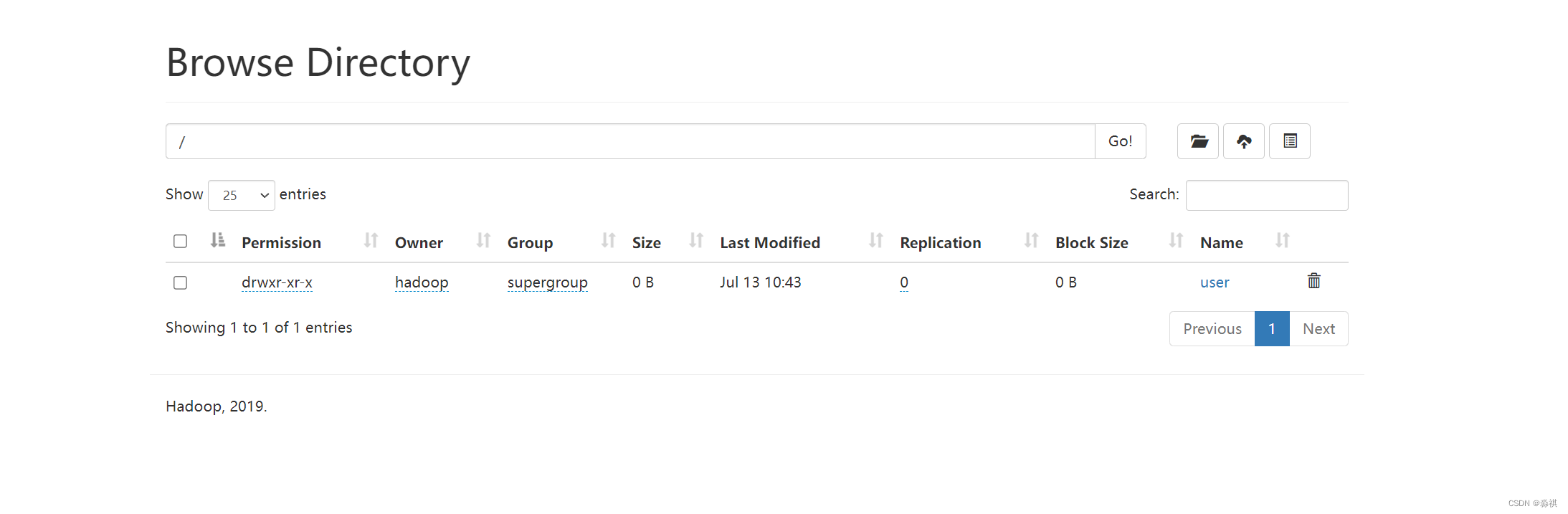
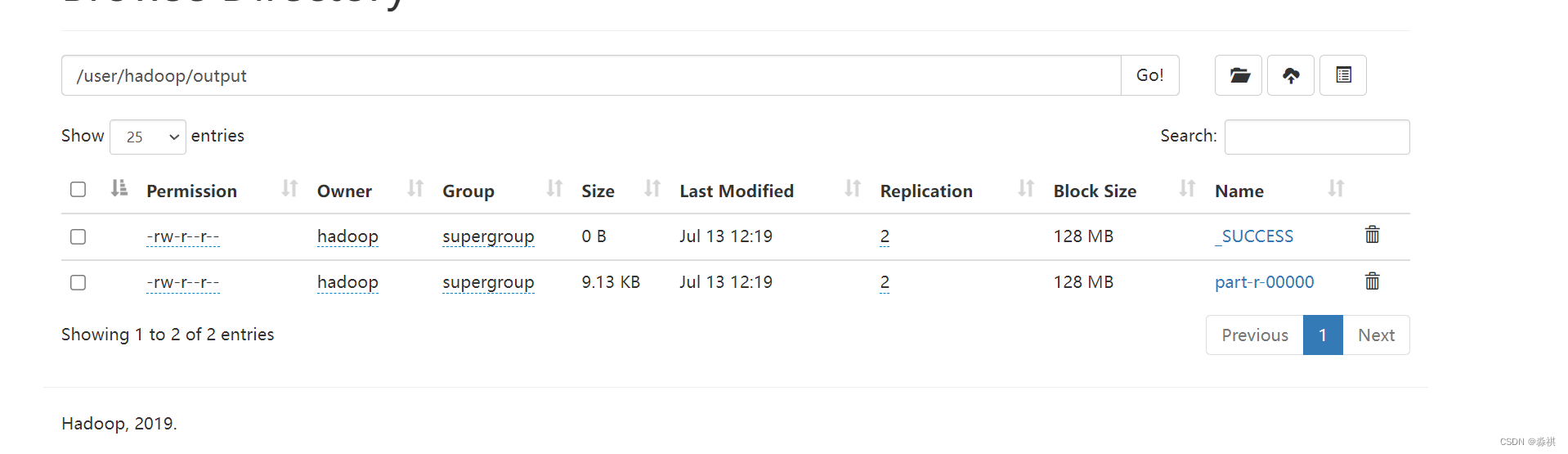
网页可以看到
上传output可以通过命令查看 下载 删除




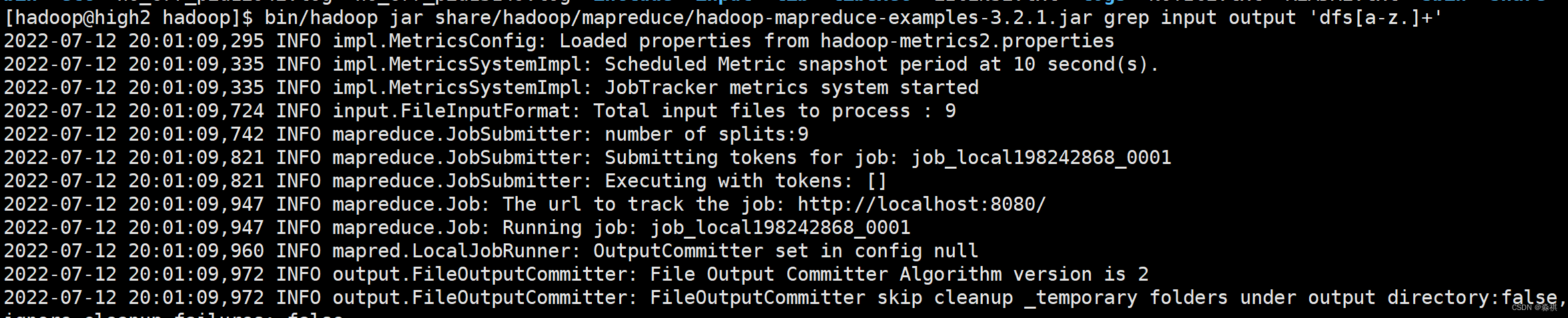

3.分布式 部署
准备 两台 虚拟机 做 数据节点 一台 名称节点 全部安装 nfs
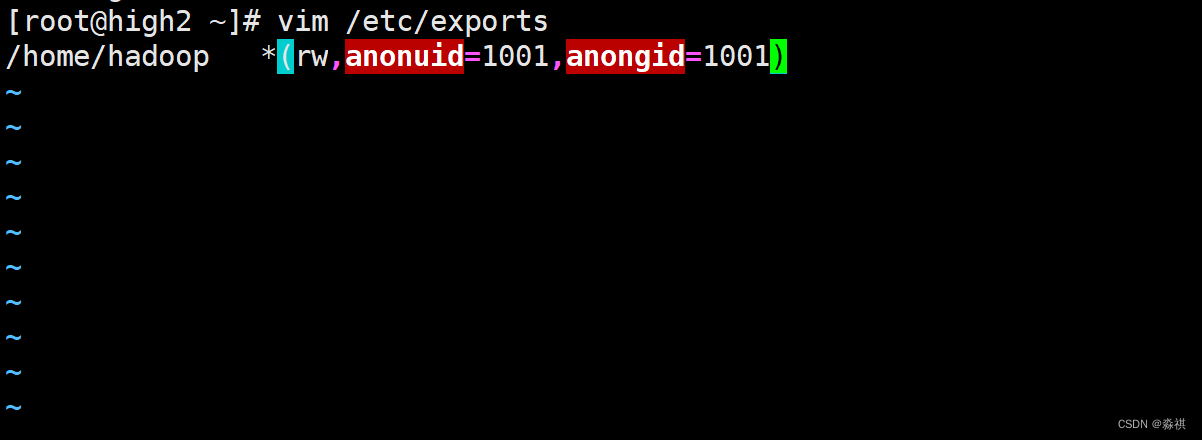
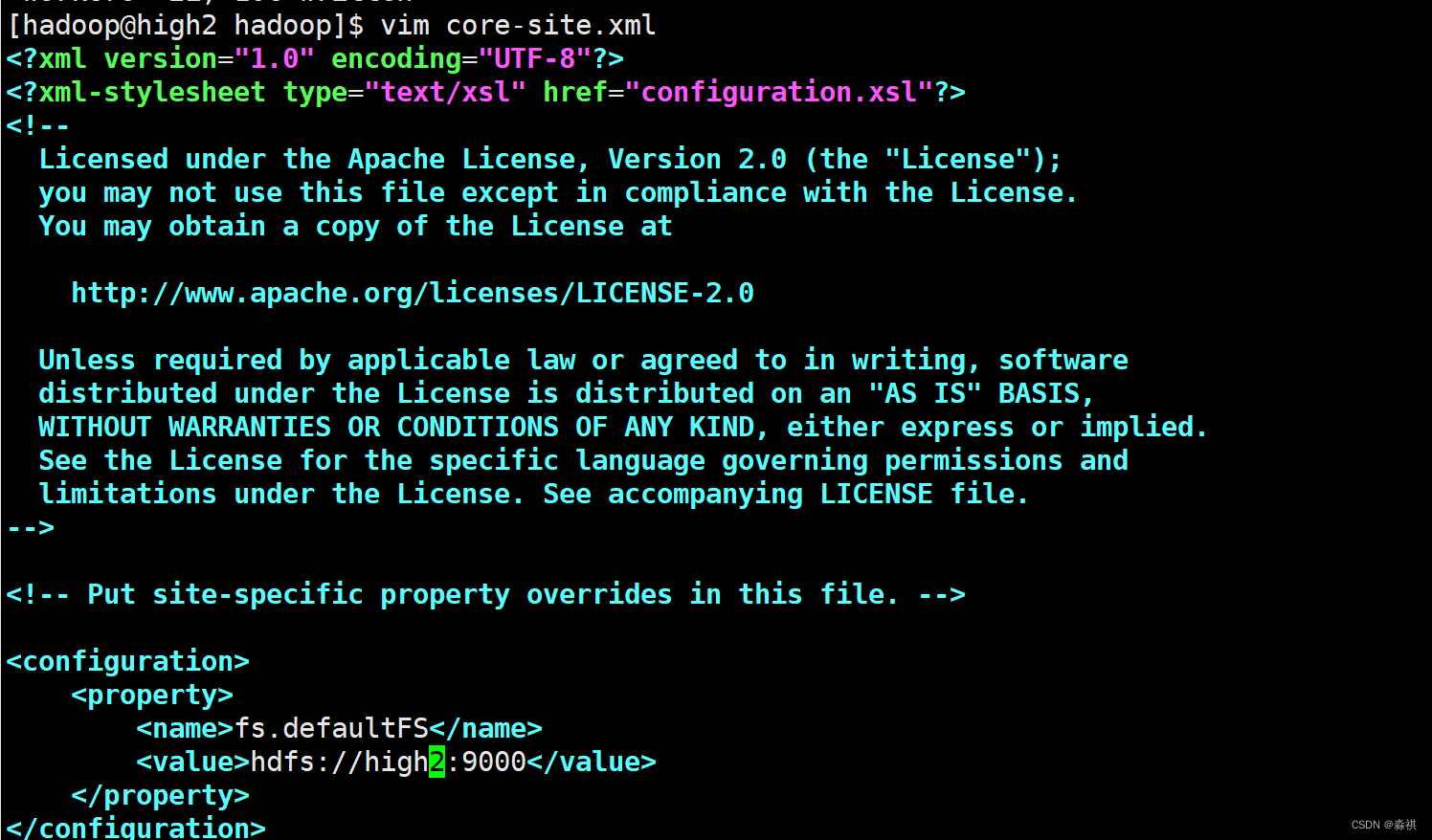
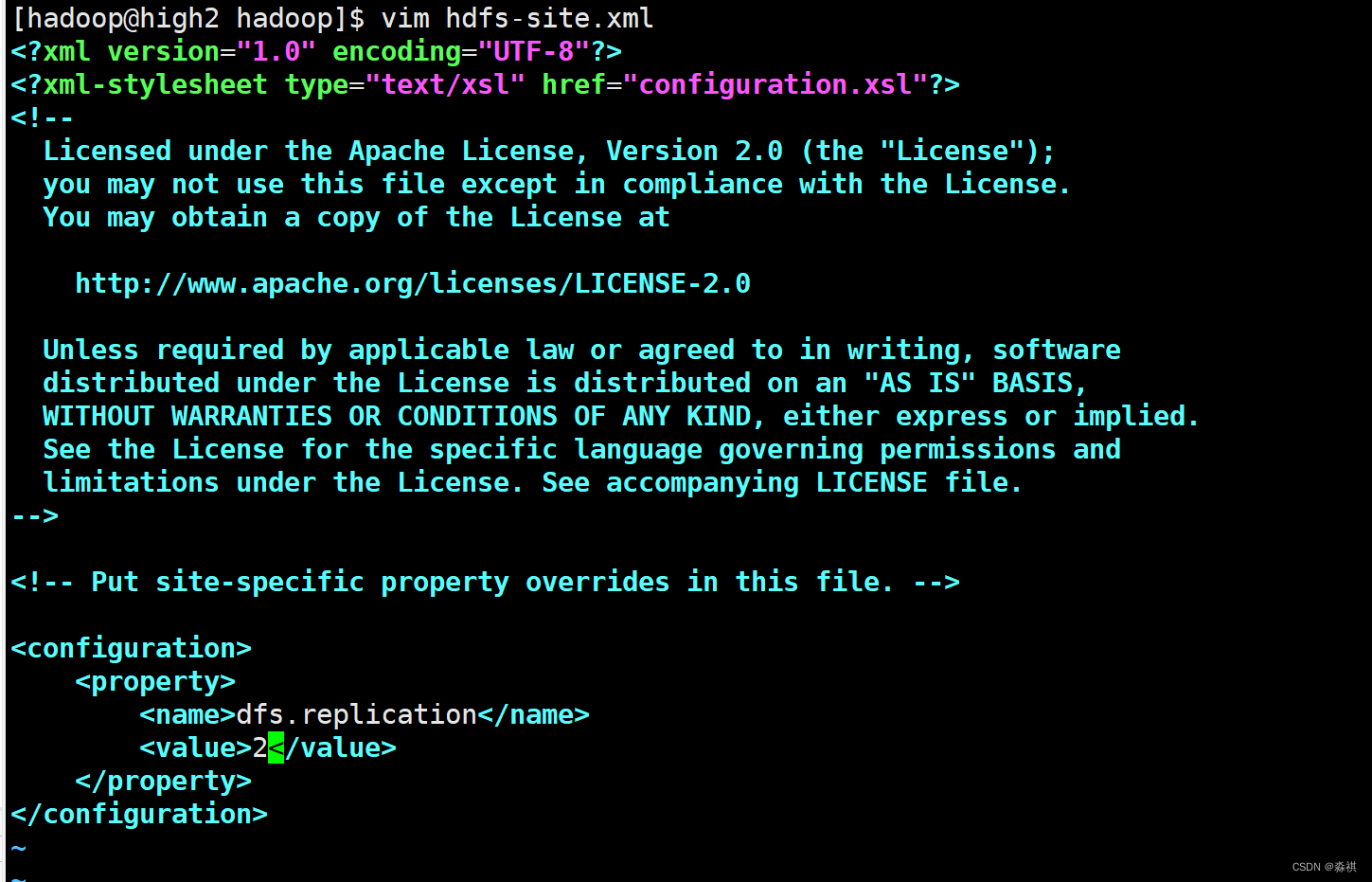
**修改配置文件 将hadoop目录共享出去 **在所有节点上 挂接
名称节点 上修改配置 如果有host解析 可以填写域名 也可以填写ip不需要解析
重新格式化启动
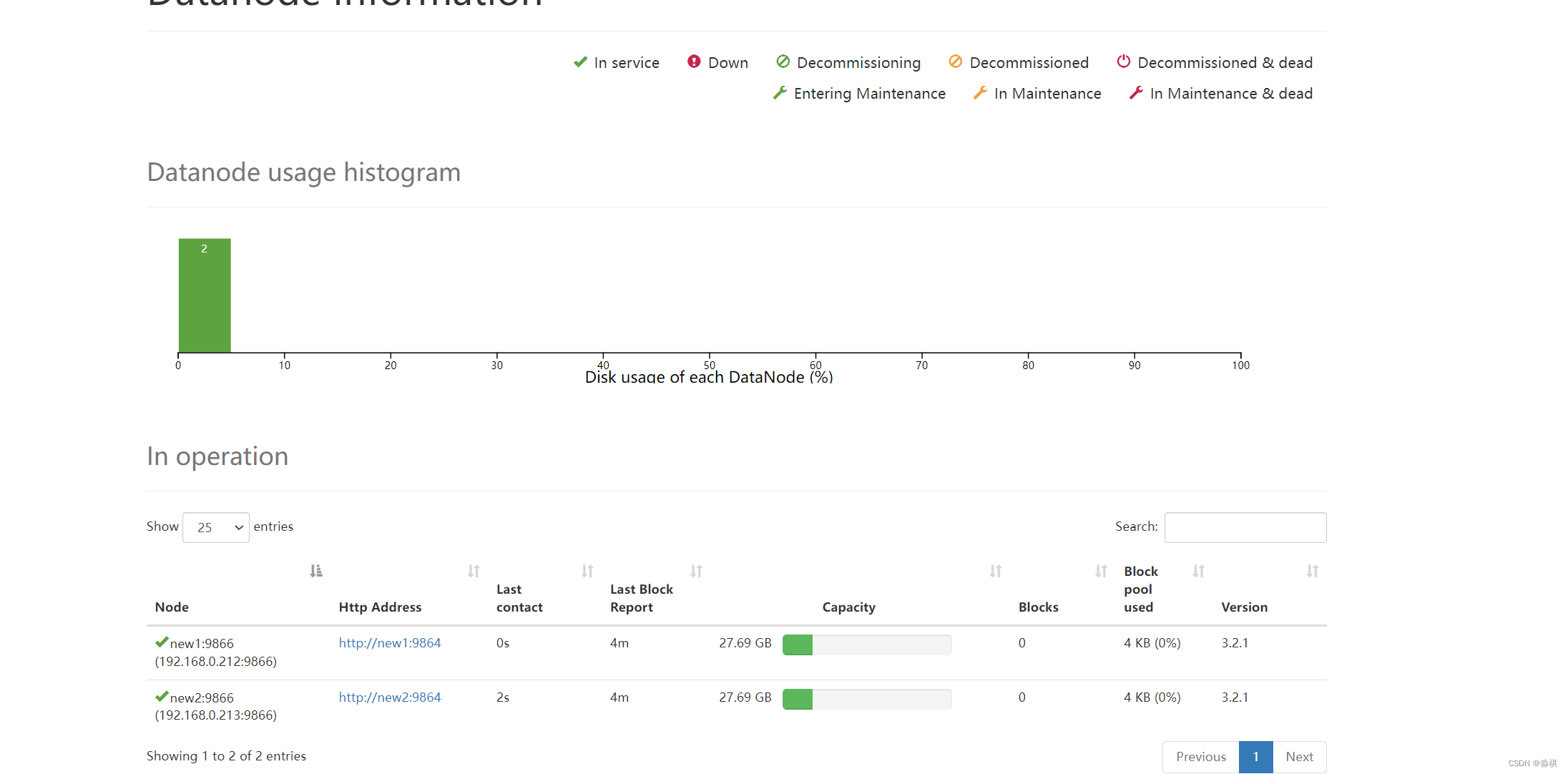
网页成功显示
上传 可正常显示


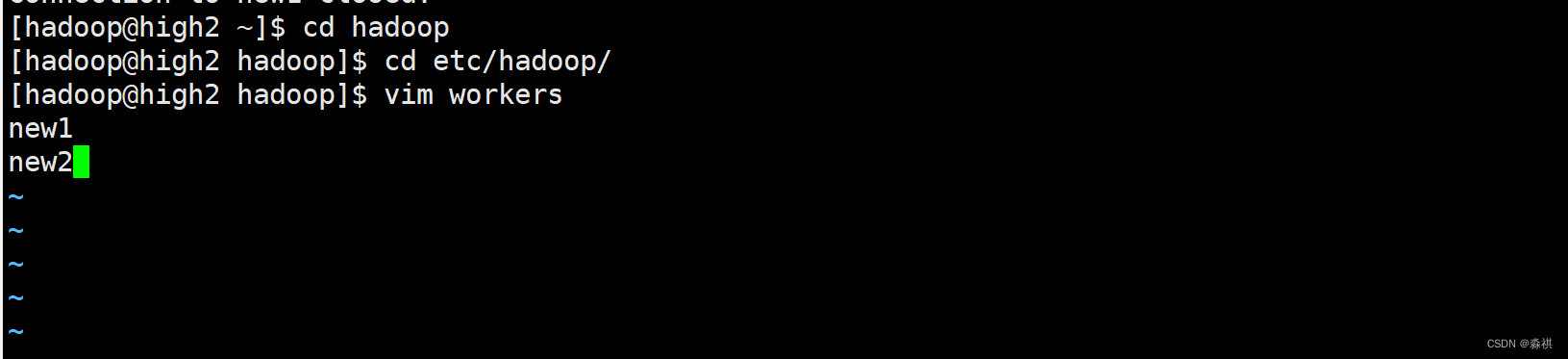



4.YARN管理器配置
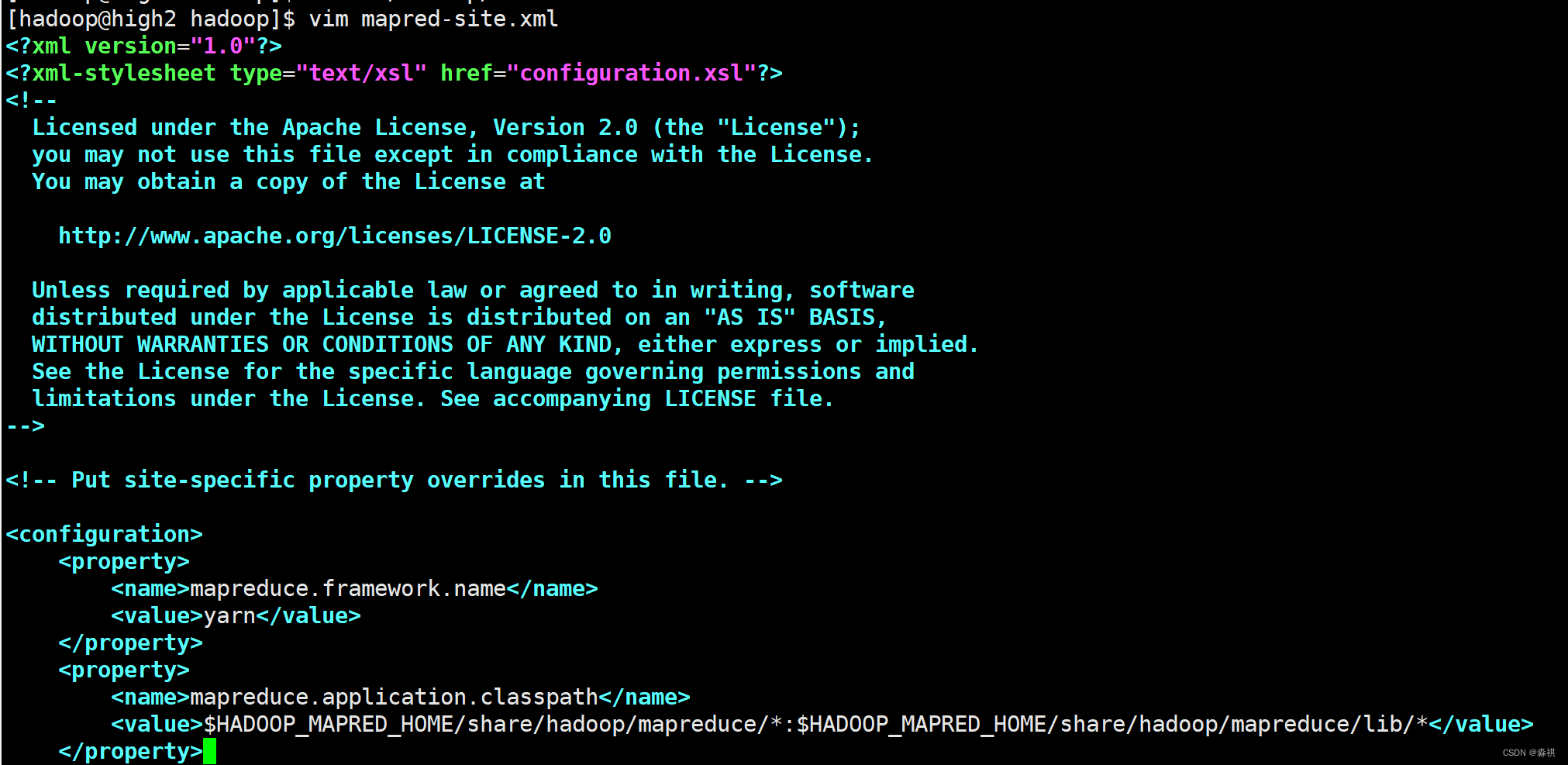
修改配置文件
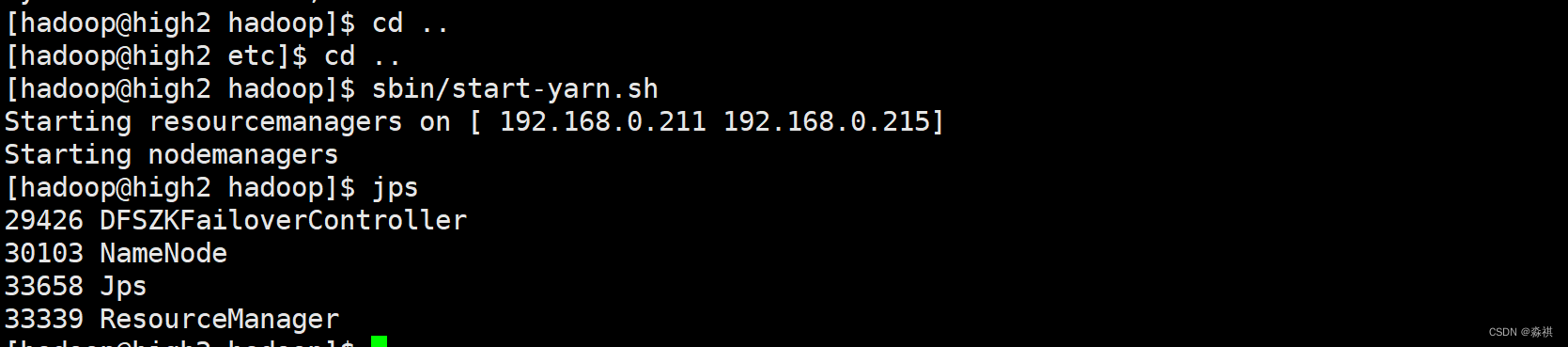
使用脚本 开启 成功
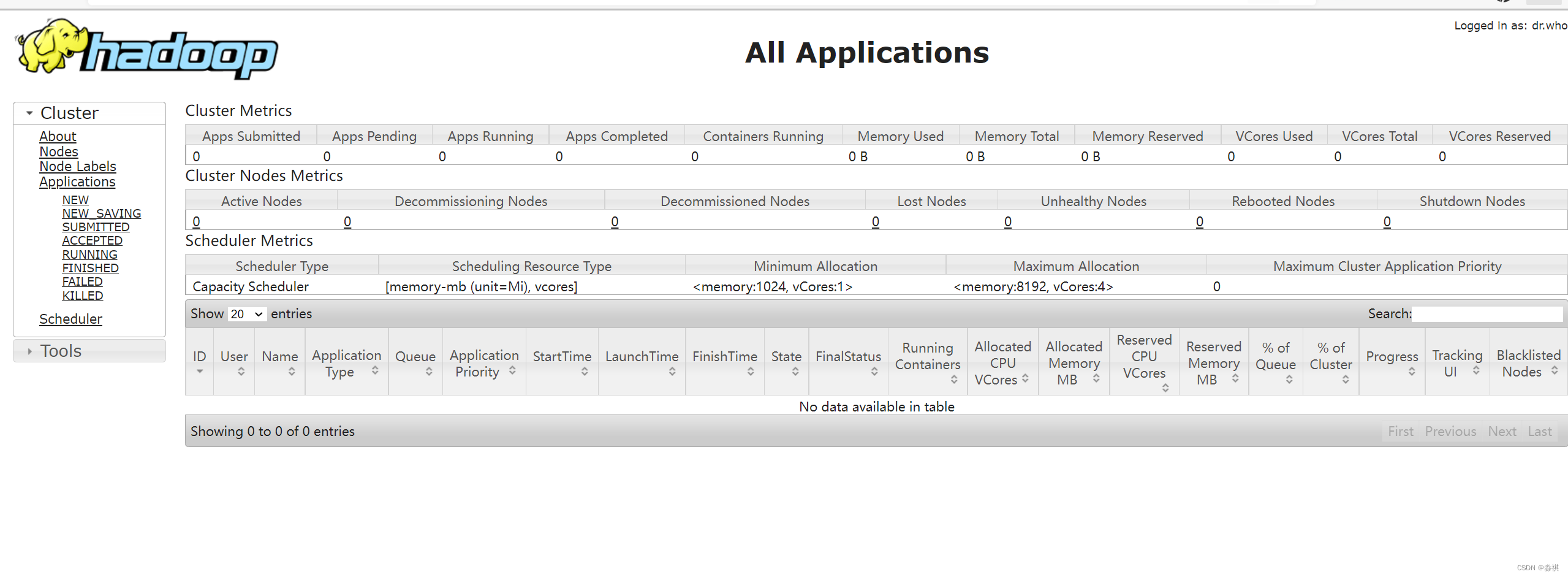
网页 可以从8088端口访问
5.hadoop 高可用
准备 五台虚拟机 两台 名称节点 三台 数据节点 通过nfs 传输
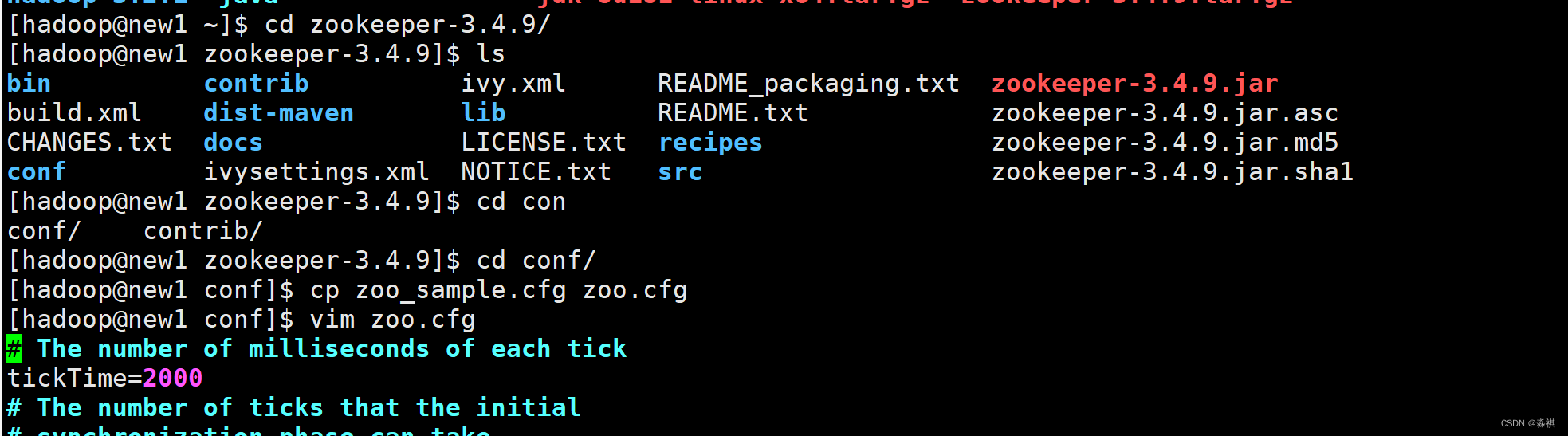
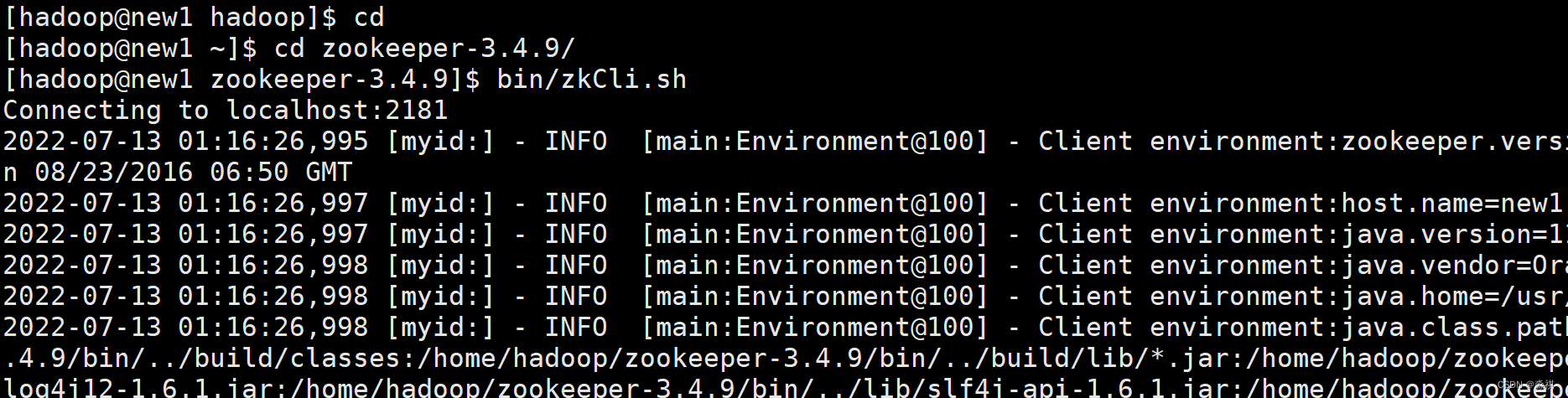
部署 zookeeper集群 下载安装包 解压
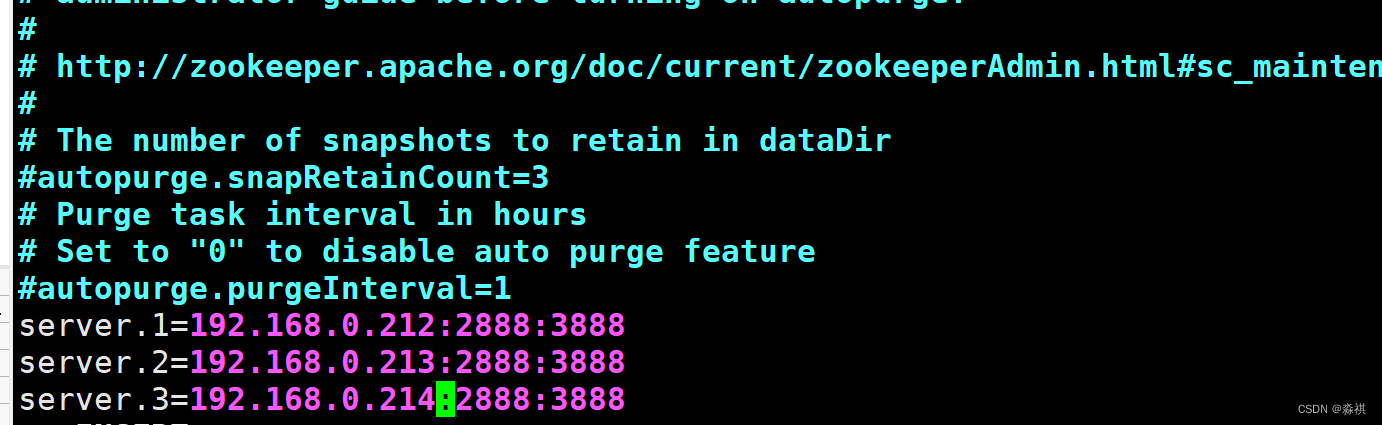
用一台数据节点 修改配置文件>
分别创建目录 以及 . 后的数字
zookeeper集群 部署完毕 接下来 接入到 hadoophdfs高可用
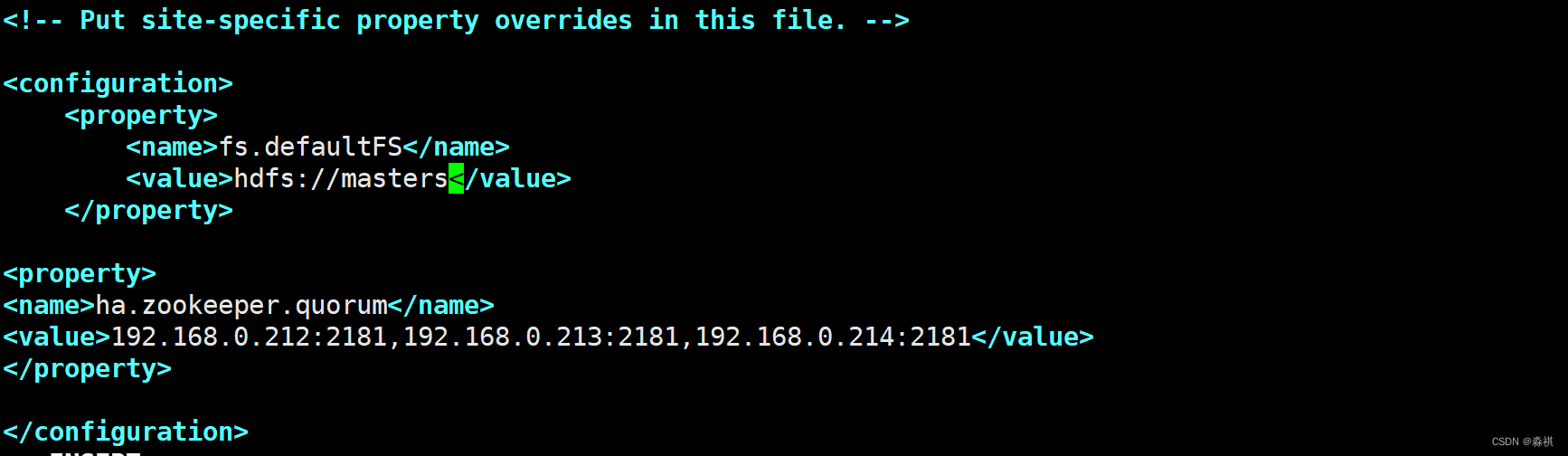
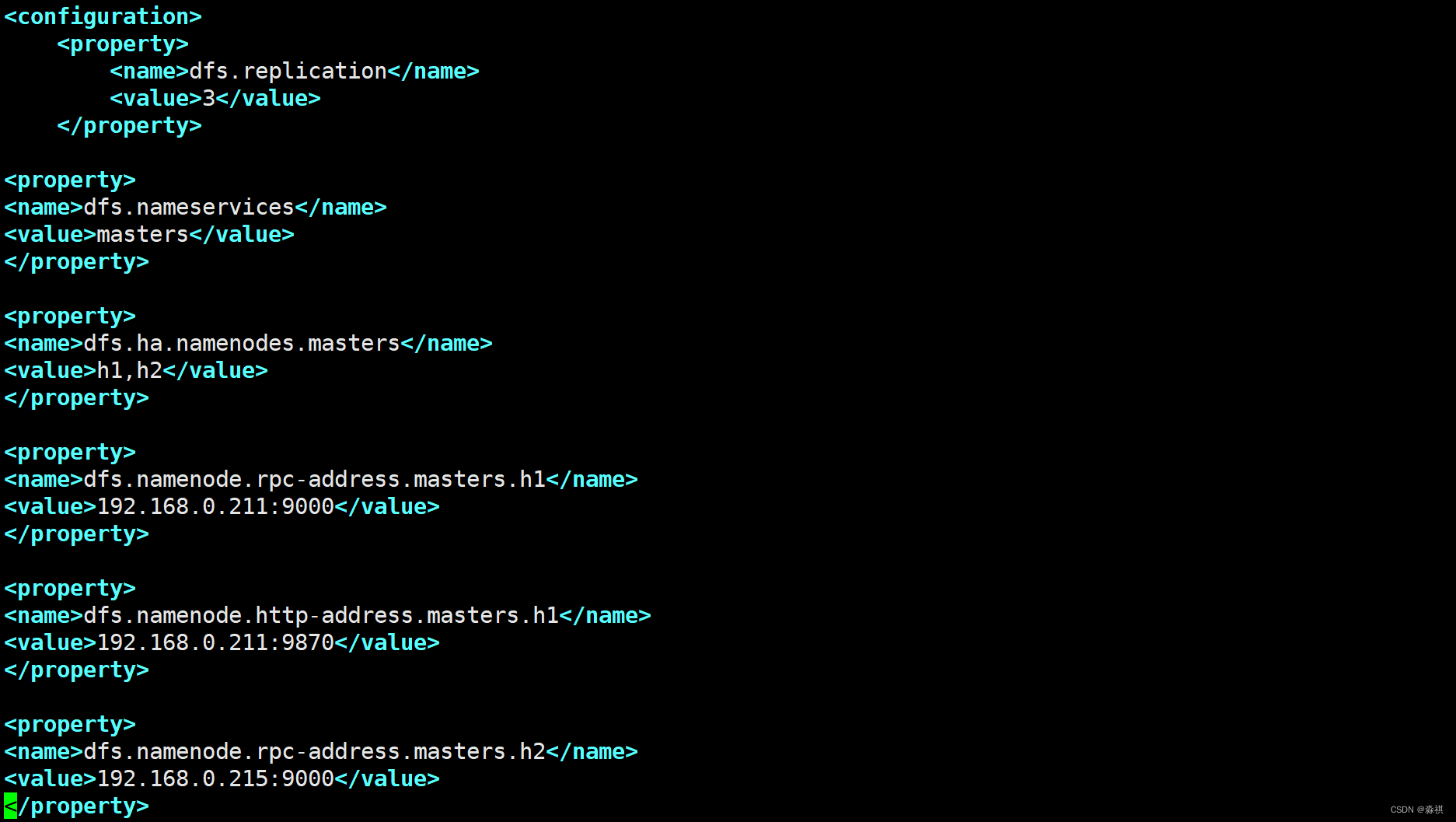
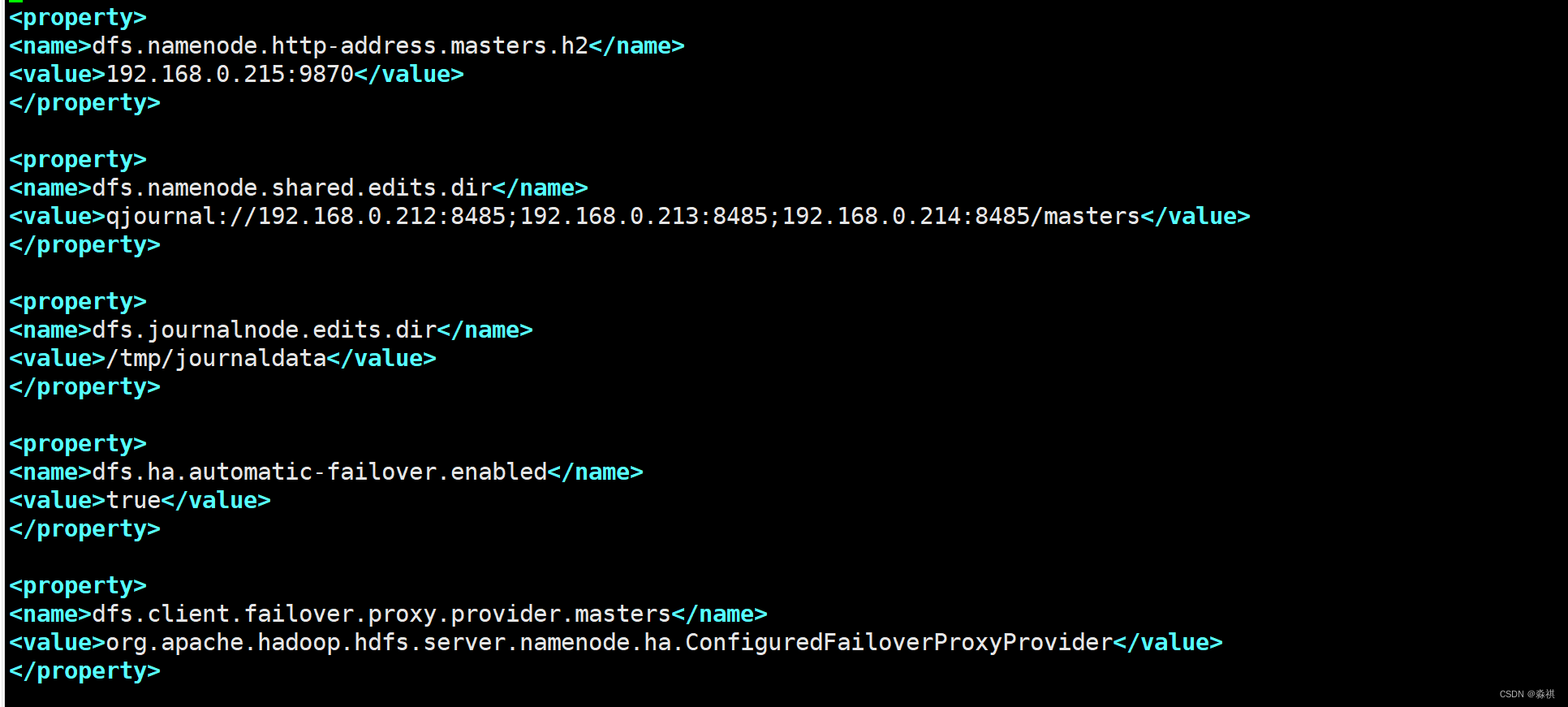
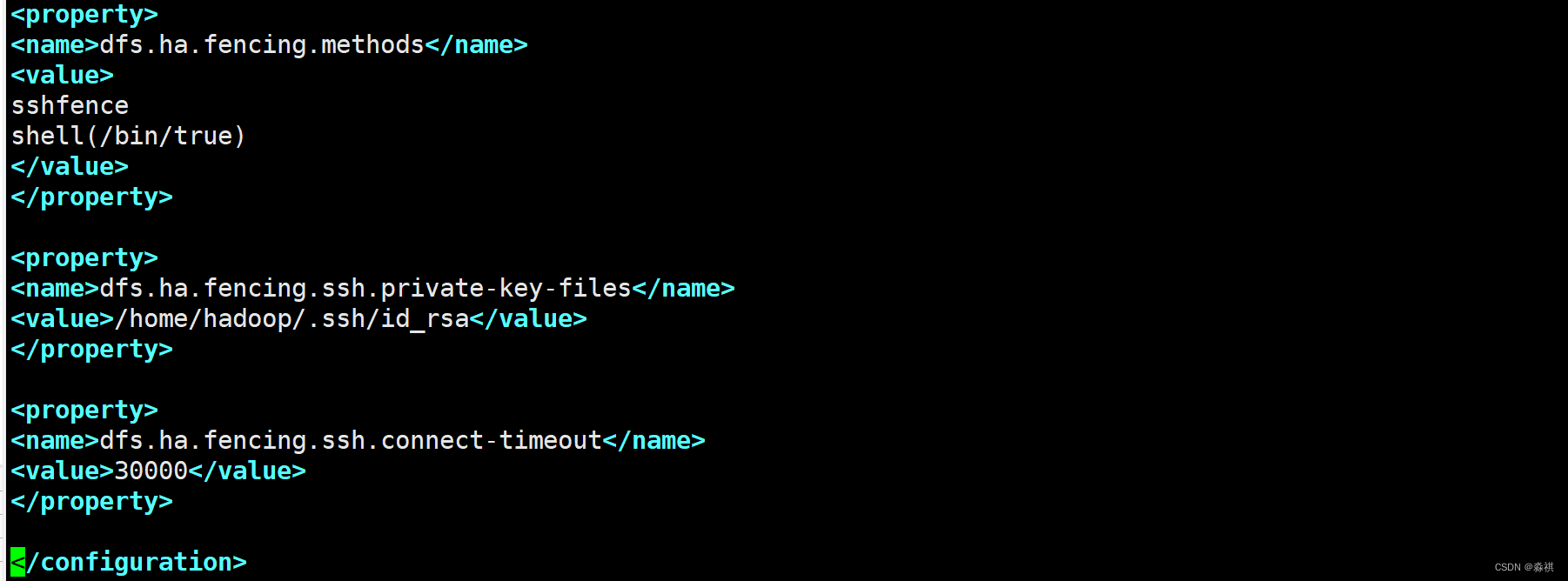
hadoop配置
修改配置文件
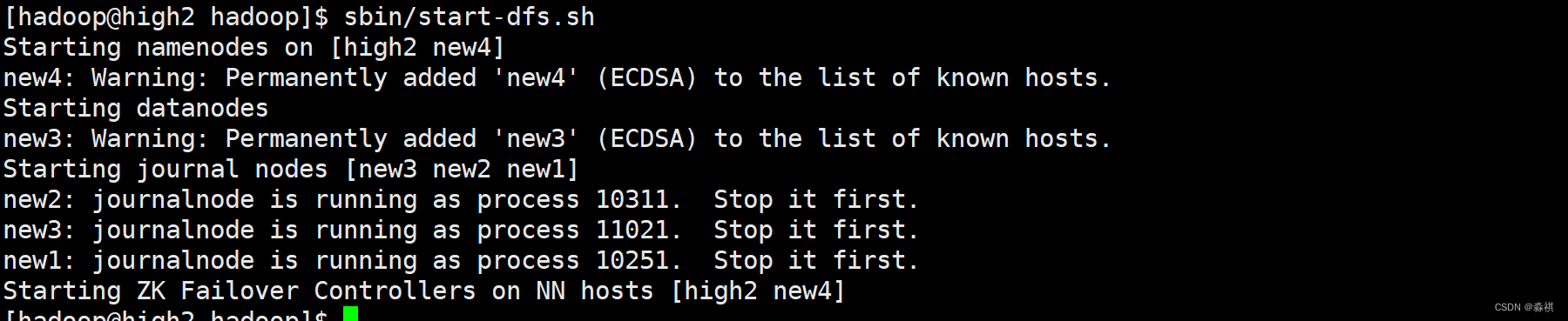
在三个 数据节点 上依次启动 journalnode
格式化 名称节点
bin/hdfs namenode -format
格式化 zookeeper启动hdfs集群
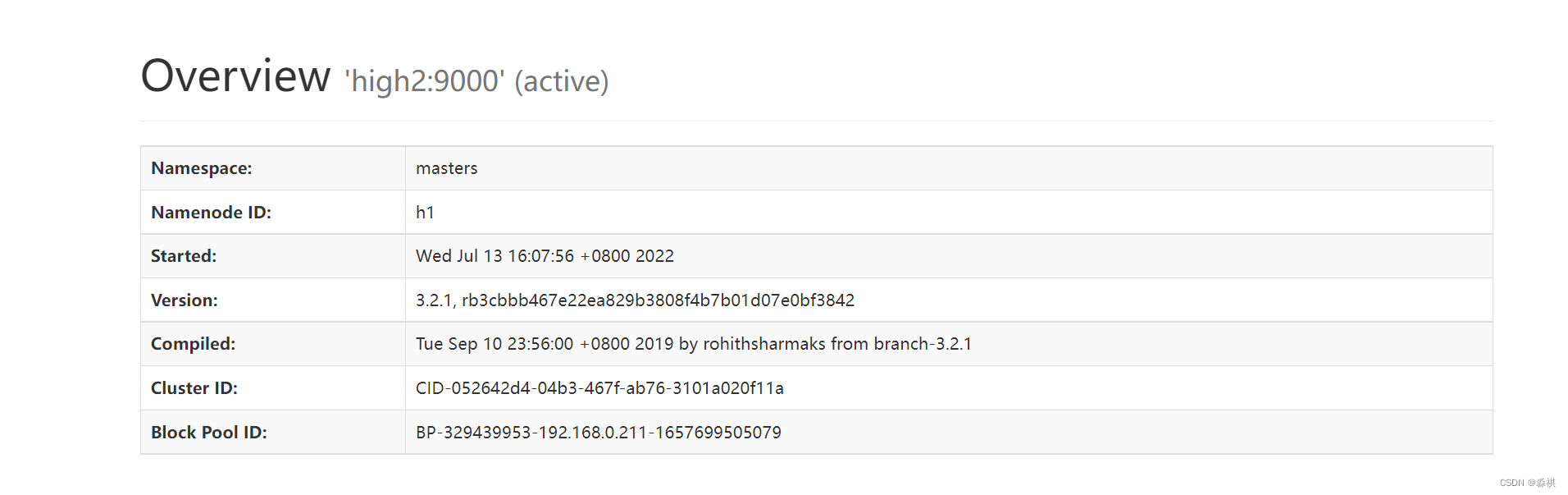
网页端可以访问
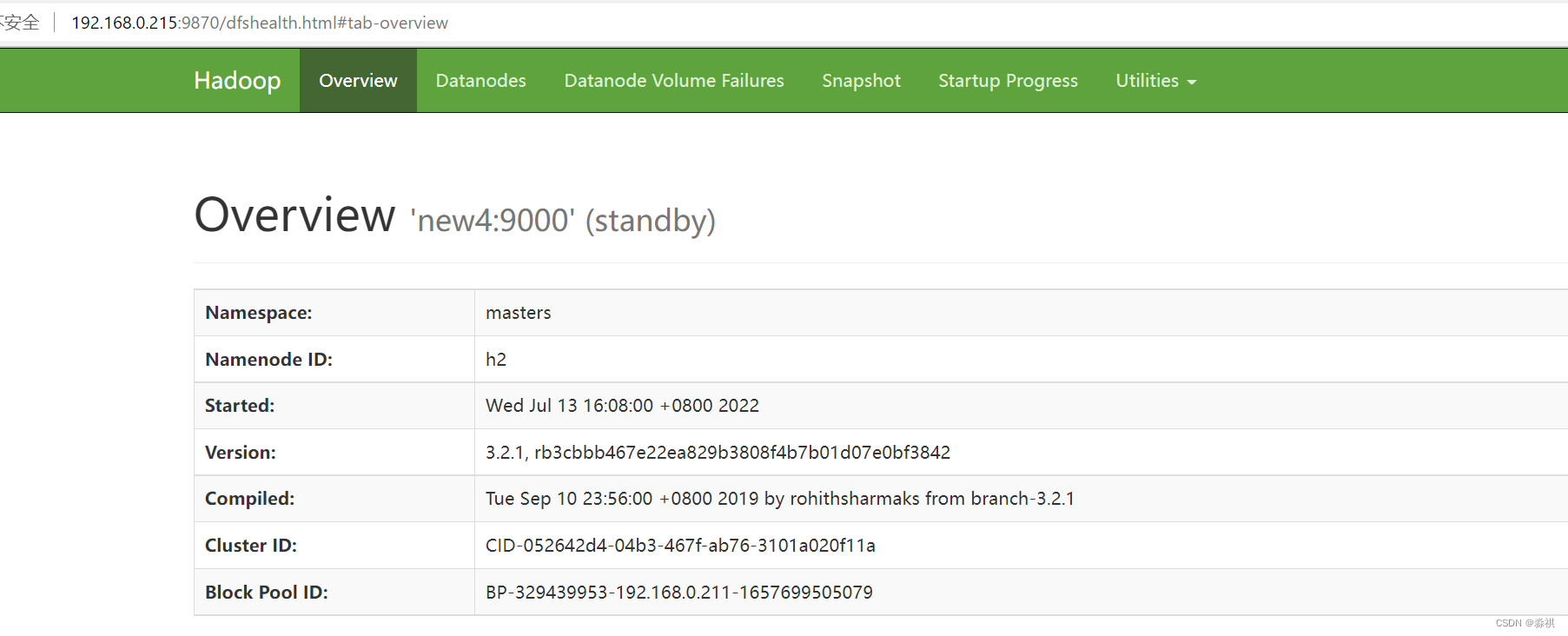
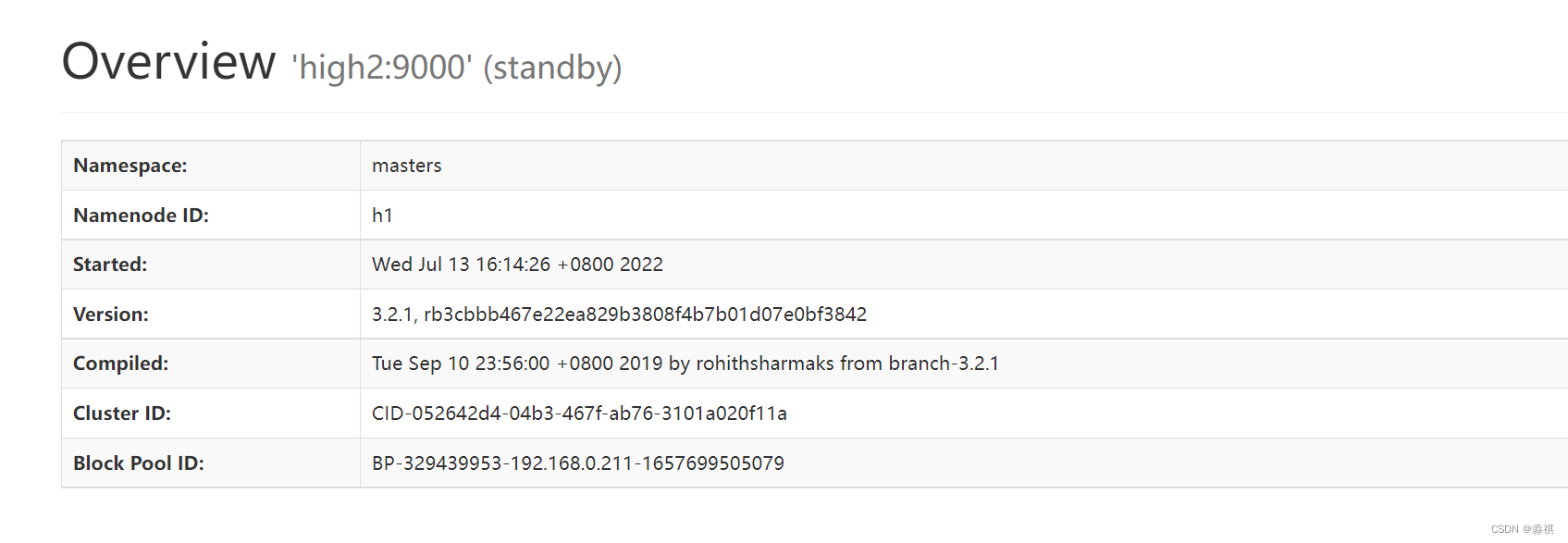
另一台为standby
上传input
网页成功看到
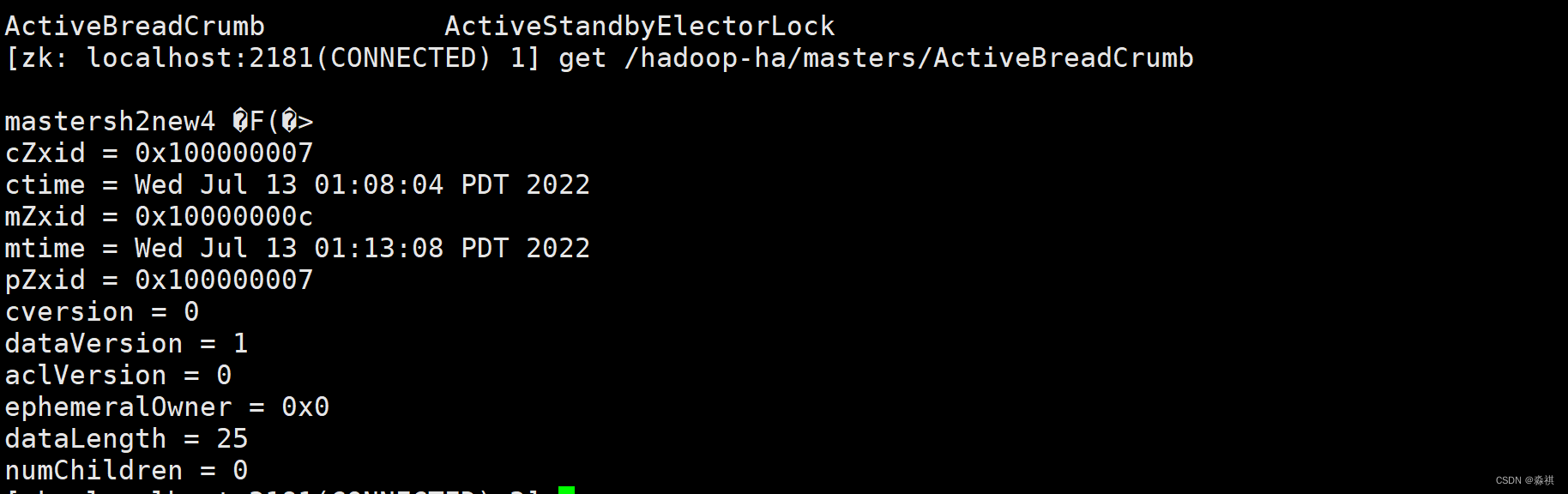
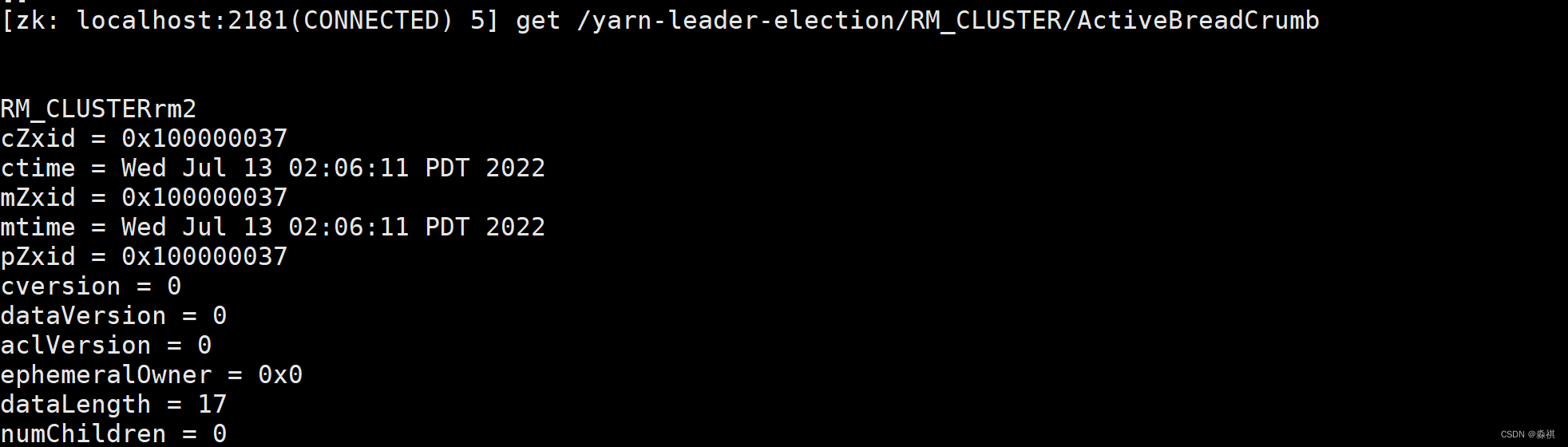
故障切换存储端进入zook
另一台主机 迅速接管重新启动 进入 standby
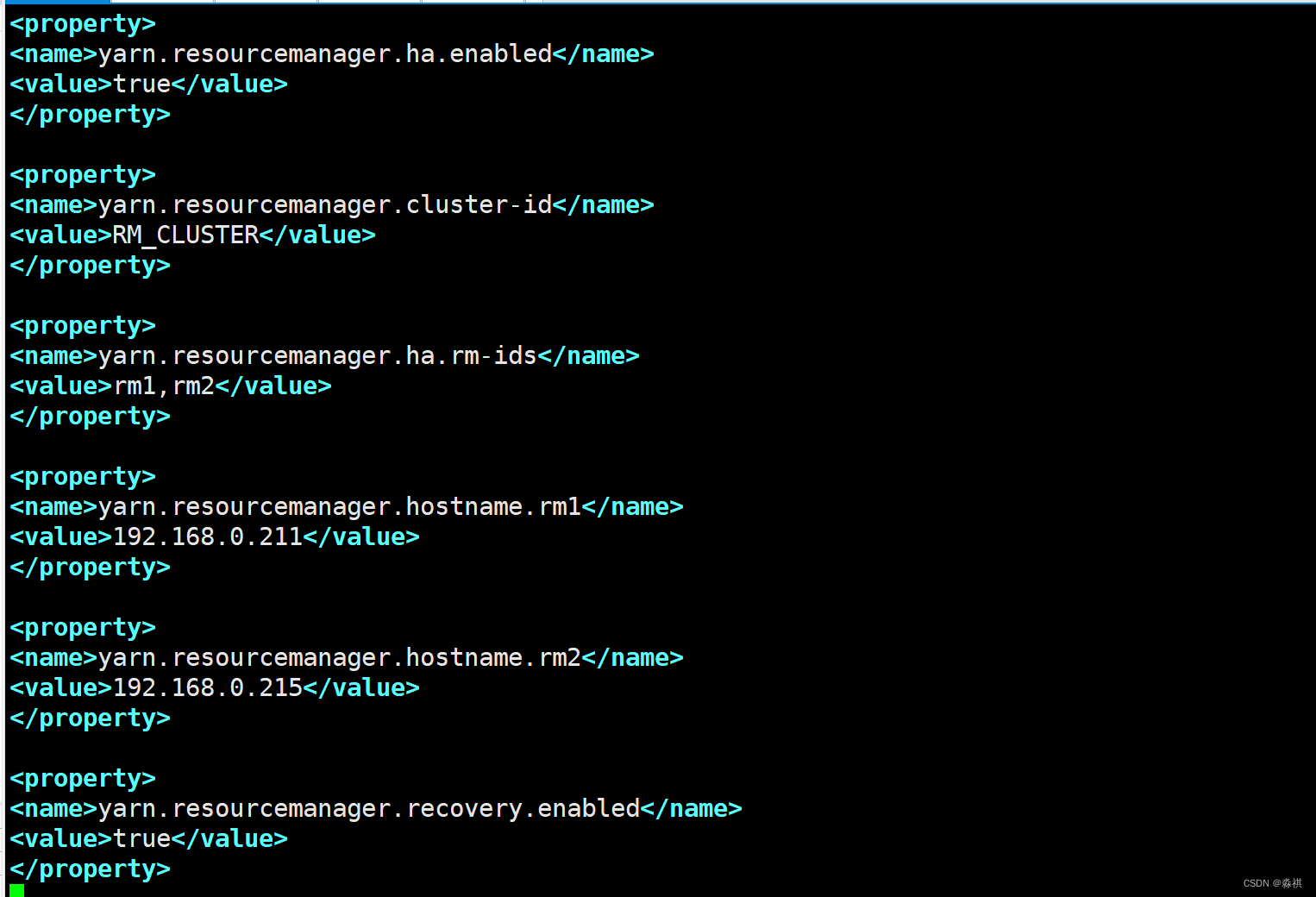
yarn高可用
编辑 yarn文件
启用 yarn成功
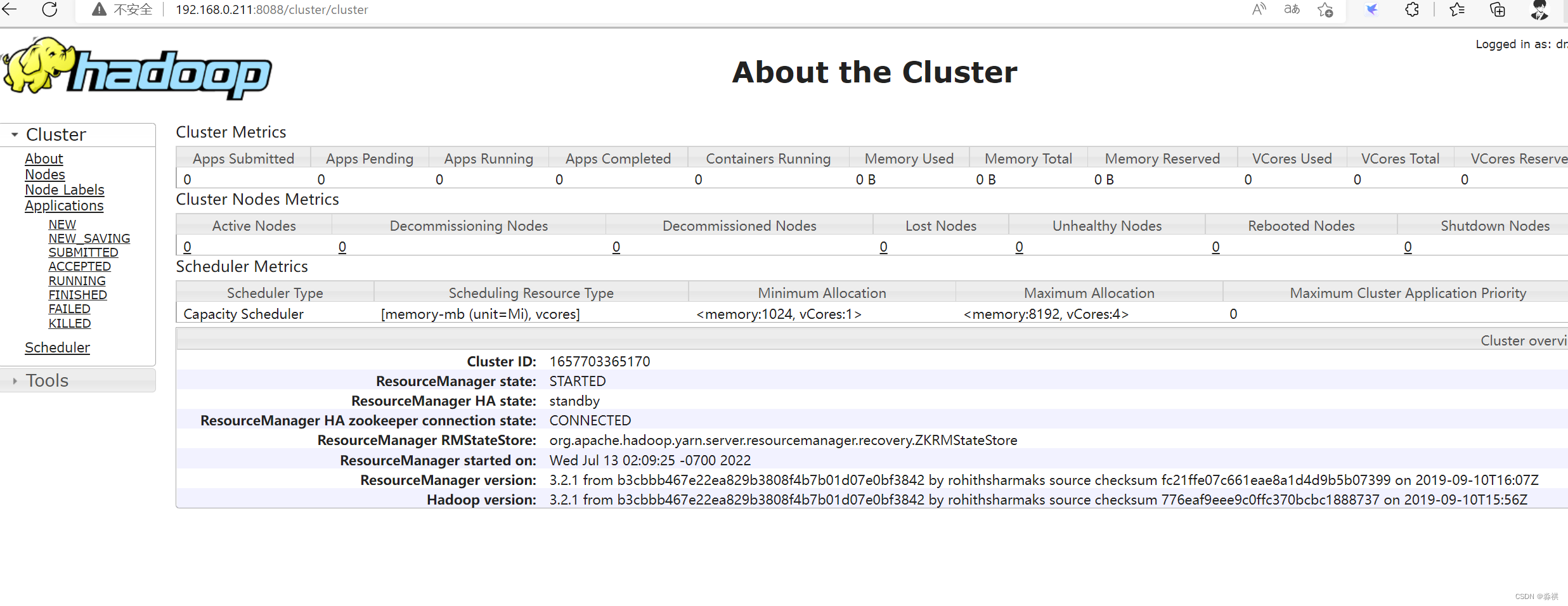
**网页可以访问 测试高可用 **关闭后 立即切换
重新启动 进入 standby模式
hbase分布部署
安装解压
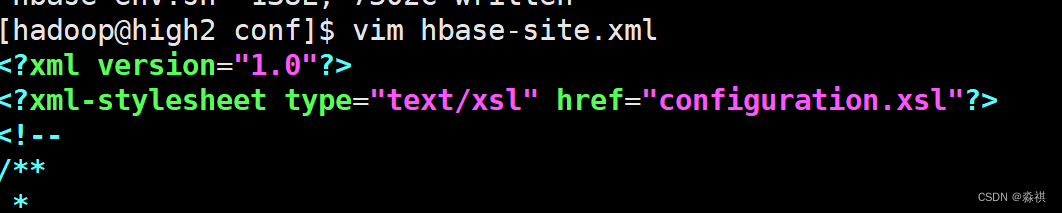
修改配置文件修改vim hbase-site.xml
vim regionservers
启动hbase 成功
另一个主机需要脚本启动
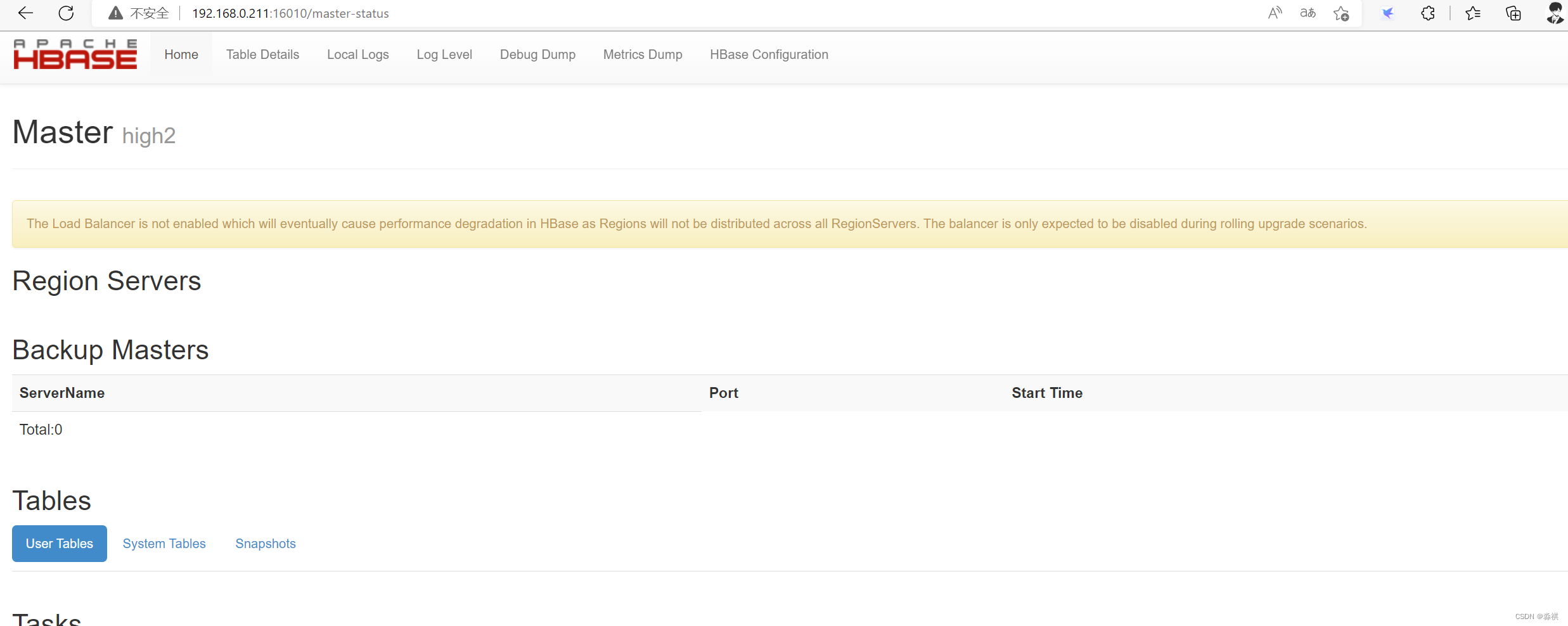
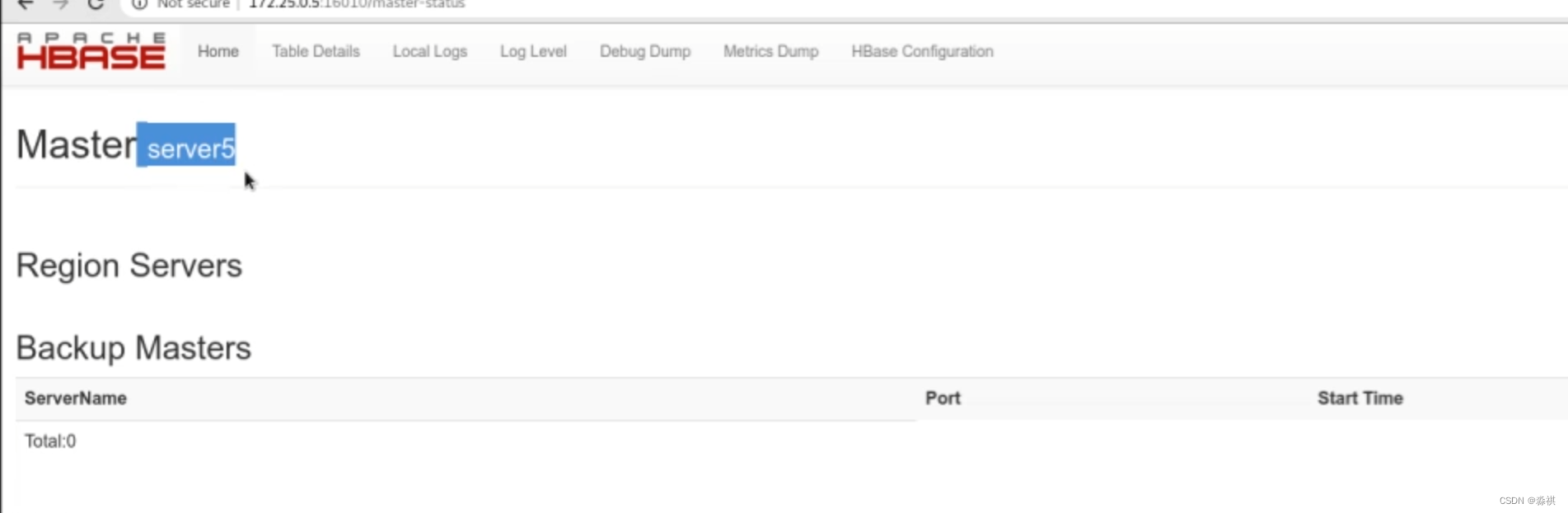
可以从默认端口 16010网页访问
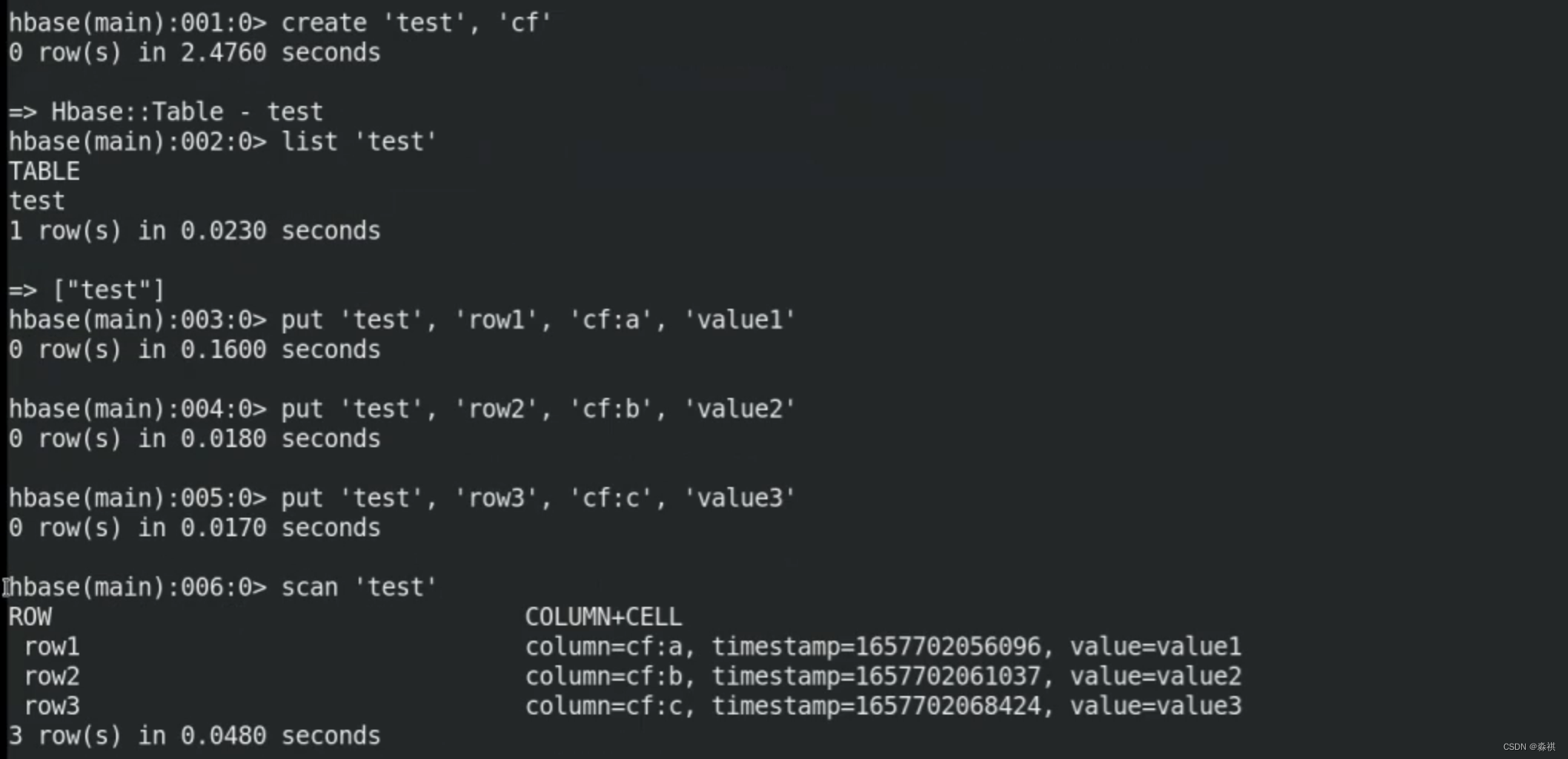
添加表格做实验
出现问题后 立马切换
命令重启数据切换完成