一文详解,分类和回归树算法背后原理。码字不易,喜欢请点赞,谢谢!!!
机器学习包括有监督和无监督两种,而无监督中主要是聚类和降维算法。
对于聚类算法来说,最常用的是K-means算法和层次聚类方法,本文对这两种算法进行简答的介绍。
一、聚类算法的思想
聚类算法是将N个点聚到K个簇里面,聚类之后,类之间具有异质性,而同一类里面具有同质性。
二、K-means算法
K-means算法是聚类算法中最经典的算法,其思路如下:
- 确定聚类个数k
- 随机选取k个点作为初始中心点
- 将每个点分配到距离最近的中心点
- 对每个类中的数据使用均值更新中心点
- 重复操作3和4直到达到迭代次数或者损失函数不再减小
三、距离计算方法
最常用的欧氏距离:
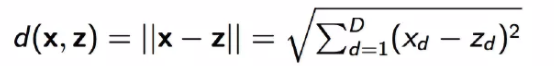
对于平面可分,一般采用欧氏距离来聚类
曼哈顿距离:
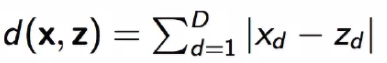
核函数映射距离:
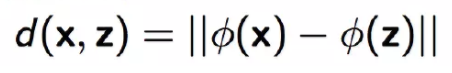
对于平面无法切割,需要使用核函数映射之后的距离
还有其他很多计算距离的方法这里就不展示了。
四、K值得选择
K-means聚类算法一个最大的问题就是k值得选择,如下数据,最好的是k值为2,而怎么找到这个k值却比较难。
现在比较好的一种方法,是采用“肘部法”,即计算一个区间内的k值和对应的损失函数,找到损失函数随k值变化而变化的肘部点,这个点的k值是相对来说比较好的选择。
五、K-means算法的局限性
- k-means算法属于硬聚类,每个样本只能属于一个类(软聚类:GMM和模糊K-means)
- k-means算法对异常点很敏感,可以采用样本中距离均值点最近的样本点代替均值点,即k-medoids算法
- k-means算法对凸状数据区分好,而对非凸状数据处理可能不是十分理想
- k-means的初始聚类中心的缺点对结果的影响很大
- k-means算法的聚类个数k的确定
六、层次聚类
k-means算法的一个难点就是k的确定,而层次聚类则不需要给定k。
层次聚类首先将每个点作为一个簇,然后选择最近的两个样本作为一个簇,然后选择两个最相近的簇作为一类,知道最后只有一类。
七、K-means VS 层次聚类
- k-means需要给定k,而层次聚类不需要
- k-means聚类速度比层次聚类快
版权声明:本文为Asher117原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。