Linux中安装RabbitMq
- 关闭防火墙
这里主要是为了后面做RabbitMq集群和主机访问管理页面做的准备
#关闭防火墙
systemctl stop firewalld.service
#禁止开机自启
systemctl disable firewalld.service
- 安装erlang
都知道RabbitMq是erlang语言编写的,自然要先安装erlang的环境
下载erlang
wget http://www.rabbitmq.com/releases/erlang/erlang-18.2-1.el6.x8664.rpm
安装erlang
erlang rpm -ihv http://www.rabbitmq.com/releases/erlang/erlang-18.2-1.el6.x8664.rpm
- 安装rabbitmq
装Rabbitmq之前先装一个公钥
rpm --import https://dl.bintray.com/rabbitmq/Keys/rabbitmq-release-signing-key.asc
下载rabbitmq
wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.6/rabbitmq-server-3.6.6-1.el7.noarch.rpm
安装
rpm -ihv rabbitmq-server-3.6.6-1.el7.noarch.rpm
安装中途可能会提示你需要一个叫socat的插件,如果提示了就先安装socat再装rabbitmq,下面是安装socat
yum install socat
- 启动rabbitmq
至此就装好了rabbitmq,可以执行以下命令启动rabbitmq
service rabbitmq-server start
和windows环境下一样,rabbitmq对于linux也提供了他的管理插件,安装rabbitmq管理插件
rabbitmq-plugins enable rabbitmq_management
安装完管理插件之后,如果有装了浏览器的话,比如火狐,可以和windows一样 访问一下localhost:15672,可以看到一个熟悉的页面
如果是在虚拟机上安装的,那么也可以直接在主机上访问
rabbitmq集群搭建
概述
rabbbitmq由于是由erlang语言开发的,erlang天生就支持分布式,自然rabbbitmq也十分支持集群模式运行。
rabbitmq 的集群分两种模式,一种是默认模式,一种是镜像模式。当然,所谓的镜像模式是基于默认模式加上一定的配置来的。
在rabbitmq集群当中,所有的节点(一个rabbitmq服务器),会被归为两类,一类是磁盘节点,一类是内存节点。
- 磁盘节点会把集群的所有信息(比如交换机,队列等信息)持久化到磁盘当中。
- 内存节点只会将这些信息保存到内存当中,讲白了,重启一遍就没了。
为了可用性考虑 rabbitmq官方强调集群环境至少需要有一个磁盘节点, 而且为了高可用的话, 必须至少要有2个磁盘节点, 因为如果只有一个磁盘节点 而刚好这唯一的磁盘节点宕机了的话, 集群虽然还是可以运作, 但是不能对集群进行任何的修改操作(比如队列添加,交换机添加,增加/移除新的节点等)。
集群的搭建
- 修改系统的hostname
具体想让rabbitmq实现集群,我们首先需要改一下系统的hostname(因为rabbitmq集群节点名称是读取hostname的)。
这里我们搭建一个有三个节点的集群,所以需要3个hostname,为了方便记录,将各自节点的系统的hostname改为下面的名字
rabbitmq1
rabbitmq2
rabbitmq3
在linux中修改hostname的命令如下
hostnamectl set-hostname [name]
记得在修改完成后需要将服务器重启这样rabbitmq才能获取节点的名字
在最后修改完所有节点的hostname后可以将所有节点的hostname和对应的IP地址写在每个节点的ho’s’t
2. 关闭防火墙
同样需要关闭防火墙,因为集群内每个节点之间是需要通信的
#关闭防火墙
systemctl stop firewalld.service
#禁止开机自启
systemctl disable firewalld.service
- 修改
.erlang.cookie文件
这个文件中存着的是erlang对这个机器的一个标识,所以为了让erlang将这些节点做集群,必须让这个文件保持一致。
这个文件的路径是/var/lib/rabbitmq/.erlang.cookie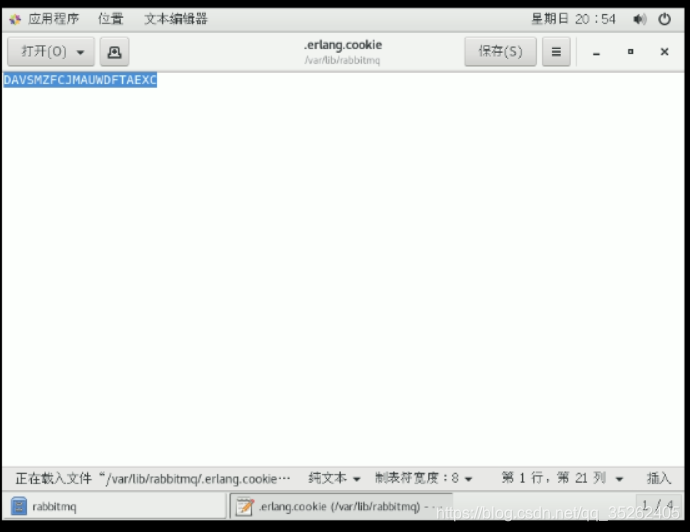
- 启动节点
首先需要将节点的RabbitMq服务启动起来
service rabbit-server start
不过需要将app应用关闭,在将集群搭建好后在启动,关闭应用
rabbitmqctl stop_app
- 搭建集群
只需要将其中其他的节点加入到一个节点形成集群。
下面是让rabbitmq2加入rabbitmq1形成一个集群,这时在rabbitmq2端的操作
# 最后面的参数-ram是使该节点成为一个内存结点
# -disk是磁盘节点
rabbitmqctl joincluster rabbit@rabbitmq1 --ram
# 启动应用
rabbitmqctl start_app
在加入节点后就可以启动应用了,后面再让rabbitmq3也加入到集群中,还是同样的命令。
rabbitmqctl joincluster rabbit@rabbitmq1 --disk
rabbitmqctl start_app
这样三个节点组成的rabbitmq集群就搭建好了
- 访问管理页面
现在不论是访问哪一个节点的管理页面都是一样的,显示的内容也是同步的,也可以查看各个节点的状态。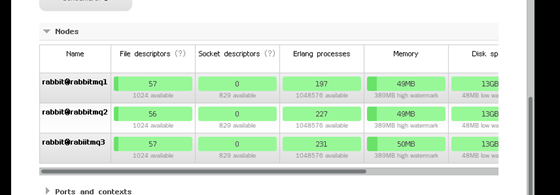
集群相关的命令
启动RabbitMQ节点
rabbitmq-server -detached
启动RabbitMQ应用,而不是节点
rabbitmqctl startapp
停止应用
rabbitmqctl stopapp
查看状态
rabbitmqctl status
新增账户
rabbitmqctl adduser mq 123456 rabbitmqctl setusertags mq administrator
启用RabbitMQManagement
rabbitmq-plugins enable rabbitmqmanagement
集群状态
rabbitmqctl clusterstatus
节点摘除
rabbitmqctl forgetclusternode rabbit@[nodeName]
重置
rabbitmqctl reset application
镜像模式
再介绍镜像模式之前,我们先说说默认普通模式的特点。
在普通模式下的rabbitmq集群,会把所有节点的交换机信息和队列的元数据(队列数据分为两种,一种为队列里面的消息, 另外一种是队列本身的信息,比如队列的最大容量,队列的名称,等等配置信息, 后者称之为元数据) 进行复制,确保所有节点都有一份。
而镜像模式,则是把所有的队列数据完全同步(元数据和队列中的消息,当然对性能肯定会有一定影响),当对数据可靠性要求高时,可以使用镜像模式。
- 镜像模式的搭建
实现镜像模式也非常简单,有2种方式,一种是直接在管理台控制,另外一种是在声明队列的时候控制。
- 声明队列控制
声明队列的时候可以加入镜像队列参数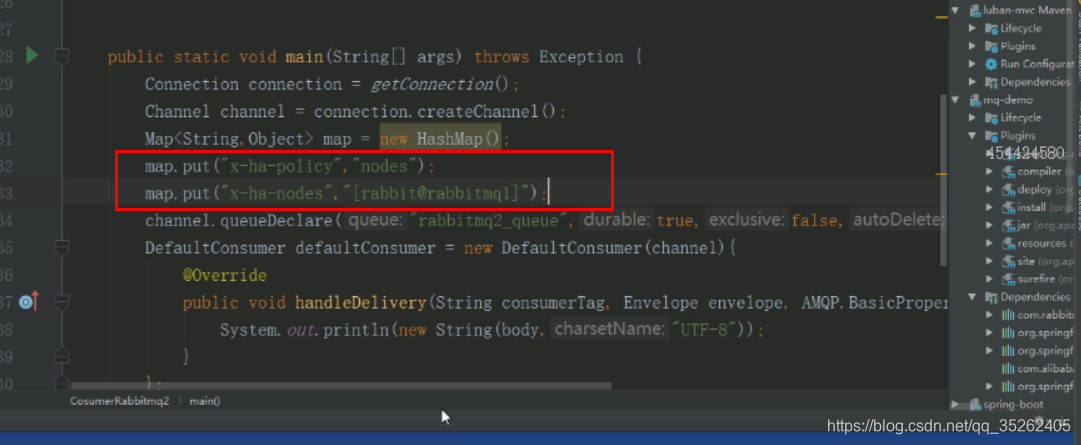
| 参数名 | 配置作用 |
|---|---|
| x-ha-policy | 创建HA队列 |
| x-ha-nodes | HA队列的分布节点 |
- 管理台控制
只需要在节点端上输入下面的命令即可
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
下面是对这些配置的解释
- -p Vhost:可选参数,针对指定vhost下的queue进行设置
- Name:policy的名称
- Pattern:queue的匹配模式(正则表达式)
- Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
- ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
- all:表示在集群中所有的节点上进行镜像
- exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
- nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
- ha-params:ha-mode模式需要用到的参数
- ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
- ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
假如想配置所有名字开头为policy的队列进行镜像,镜像数量为1那么命令如下
rabbitmqctl setpolicy hapolicy "^policy_" '{"ha-mode":"exactly","ha-params":1,"ha-sync-mode":"automatic"}'
所有节都有一份队列和交换机的信息
不过队列的信息有两种
队列的元数据(队列的配置)
队列中的消息
对于所有节点都有一份队列的元数据,但队列的中的消息只存在一个节点中
但某一节点接收到某个队列的消息,它非根据队列的元数据将消息发送到真正存有队列的消息的节点
扩展
HAProxy是RabbitMq做负载均衡的插件