Python爬虫框架
Scrapy是一个为了爬取网站数据、提取数据而编写的应用型框架,一个非常强大的爬虫框架。今天我们就来用scrapy框架爬取网站上的基本信息,我们要爬取的网站是西刺网,目的是爬取西刺网上的ip地址、端口号以及服务器地址
使用scrapy框架的步骤:
(1)下载scrapy
(2)创建项目
(3)创建爬虫文件
我们要爬取的页面: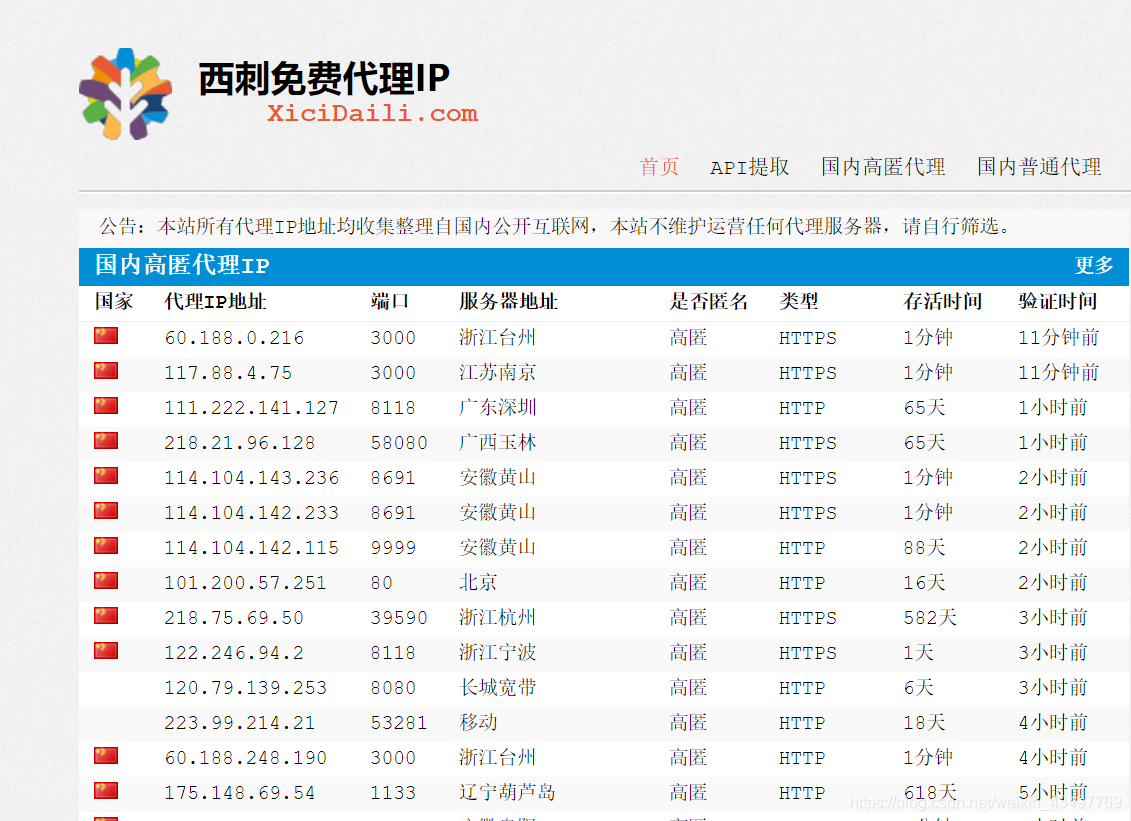
- 下载scrapy框架(pip install scrapy),这里我已经下载了scrapy,下载scrapy会引入一些需要的模块,要花一些时间,要耐心等待
- 创建一个项目,命令为scrapy startproject xxx(项目名)

- 创建爬虫文件,命令为scrapy genspider xxx(爬虫名) xxx(域名)

- 将文件导入python环境中,这里我们用的是pycharm
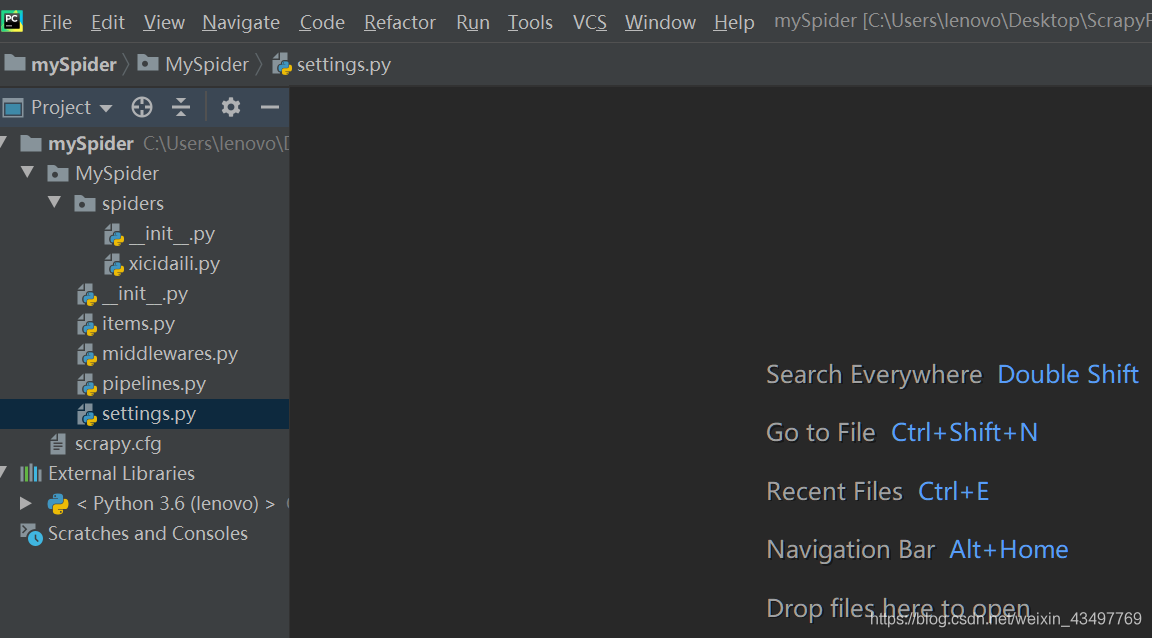
- 我们在爬取信息之前要关闭robot协议
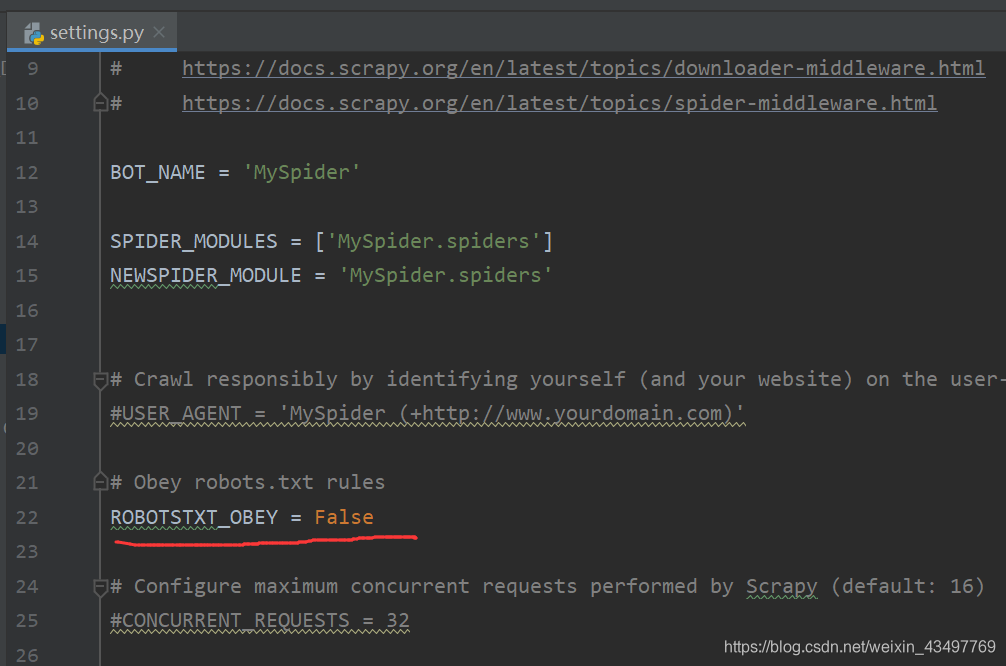
- 添加请求头
- 在我们创建的爬虫文件中写程序
# -*- coding: utf-8 -*-
import scrapy
class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains = ['xicidaili.com']
start_urls = ['http://www.xicidaili.com/'] #采集的网址
def parse(self, response):
selectors=response.xpath('//tr') #选择所有的tr标签
#循环遍历tr标签下的td标签
for selector in selectors:
ip=selector.xpath('./td[2]/text()').get() #获取ip
port=selector.xpath('./td[3]/text()').get() #获取端口号
address=selector.xpath('./td[4]/text()').get() #获取服务器地址
print('ip地址:',ip,'端口号:',port,'服务器地址:',address)- 在控制台运行,命令为scrapy crawl xicidaili(爬虫名)
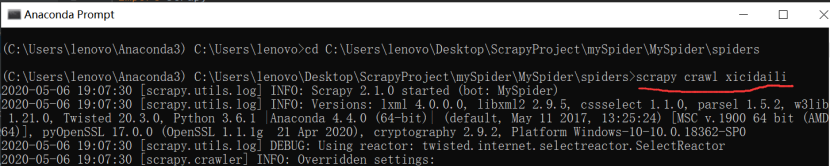
 这样,简单的入门实例就运行完成了!!
这样,简单的入门实例就运行完成了!!
版权声明:本文为weixin_43497769原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。