文章目录
缘起
目前大部分公司都是分布式服务,对于生产日志的分析需要构建一个日志收集系统便于开发和运维去分析和监控生产问题。本篇博文采用filebeat+kafka+logstash+elasticsearch+kibana 来构架一个分布式日志收集系统。
本次实践基于 filebeat :6.0.1 logstash: 6.0.1 elasticsearch 6.0.1 kibana 6.0.1 kafak 2.11 所在的日志收集架构,因版本不同配置变动过大 此处建议读者使用笔者该版本搭建。
架构
框架架构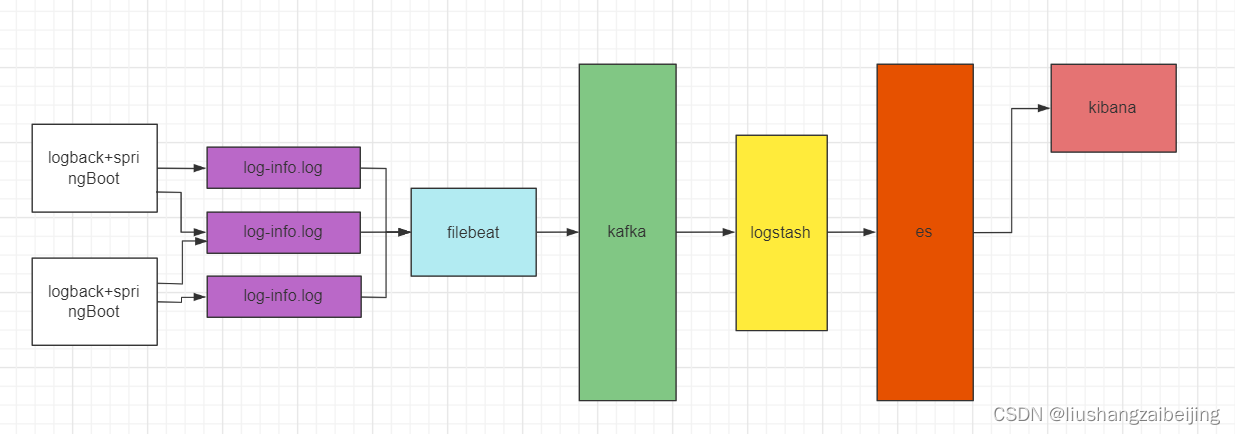
- Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读)
- Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据
- Logstash是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景
- ElasticSearch它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
- Kibana是ElasticSearch的用户界面
在实际应用场景下,为了满足大数据实时检索的场景,利用Filebeat去监控日志文件,将Kafka作为Filebeat的输出端,Kafka实时接收到Filebeat后以Logstash作为输出端输出,到Logstash的数据也许还不是我们想要的格式化或者特定业务的数据,这时可以通过Logstash的一些过了插件对数据进行过滤最后达到想要的数据格式以ElasticSearch作为输出端输出,数据到ElasticSearch就可以进行丰富的分布式检索了。
1 项目创建
本文使用logback作为日志输出框架,采用springBoot架构,springBoot项目很简单,这里只贴出logback日志配置(配置中的分级和每行日志格式对于后面日志采集和kafka分发很重要)
1.1 logback配置
此处不使用默认logback.xml 自动引入(自动引入没有感觉配置怎么起作用)设置名字为logback-spring.xml手动配置到springboot项目中
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds">
<contextName>logback</contextName>
<!--属性变量 下面直接使用 后面可以通过${app.name}使用 -->
<property name="LOG_PATH" value="logs" />
<property name="FILE_NAME" value="collector" />
<property name="PATTERN_LAYOUT" value="[%d{yyyy-MM-dd'T'HH:mm:ss.SSSZZ}] [%level{length=5}] [%thread] [%logger] [%hostName] [%ip] [%applicationName] [%F,%L,%C,%M] %m ## '%ex'%n" />
<!-- 彩色日志 -->
<!-- 配置自定义获取的日志格式参数 比如如下的ip、主机名 应用名 -->
<!--<conversionRule conversionWord="tid" converterClass="com.xiu.distributed.logcollection.config.LogBackIpConfig" />-->
<conversionRule conversionWord="ip" converterClass="com.xiu.distributed.logcollection.config.LogBackIpConfig" />
<conversionRule conversionWord="hostName" converterClass="com.xiu.distributed.logcollection.config.LogBackHostNameConfig" />
<conversionRule conversionWord="applicationName" converterClass="com.xiu.distributed.logcollection.config.LogBackAppNameConfig" />
<!--输出到控制台-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--定义了一个过滤器,在LEVEL之下的日志输出不会被打印出来-->
<!--这里定义了DEBUG,也就是控制台不会输出比ERROR级别小的日志-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>info</level>
</filter>
<encoder>
<!--定义控制台输出格式-->
<Pattern>${PATTERN_LAYOUT}</Pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<!--输出到文件-->
<!-- 时间滚动输出 level为 DEBUG 日志 -->
<appender name="DEBUG_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/log_debug.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${PATTERN_LAYOUT}</pattern>
<charset>UTF-8</charset> <!-- 设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 日志归档 -->
<fileNamePattern>${LOG_PATH}/log_debug_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>7</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录debug级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>debug</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 INFO 日志 -->
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/log_info.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${PATTERN_LAYOUT}</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 每天日志归档路径以及格式 -->
<fileNamePattern>${LOG_PATH}/log_info_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>7</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>info</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 WARN 日志 -->
<appender name="WARN_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/log_warn.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${PATTERN_LAYOUT}</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/log_warn_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>7</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录warn级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>warn</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 ERROR 日志 -->
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/log_error.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${PATTERN_LAYOUT}</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/log_error_%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>7</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录ERROR级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!--对于类路径以 xxxx 开头的Logger,输出级别设置为info,并且只输出到控制台-->
<!--这个logger没有指定appender,它会继承root节点中定义的那些appender-->
<!--additivity表示要不要使用rootLogger配置的appender进行输出-->
<logger name="org.apache.ibatis" level="INFO" additivity="false" />
<logger name="org.mybatis.spring" level="INFO" additivity="false" />
<logger name="com.github.miemiedev.mybatis.paginator" level="INFO" additivity="false" />
<!-- root 是一个默认的logger-->
<root level="info">
<appender-ref ref="CONSOLE" />
<appender-ref ref="DEBUG_FILE" />
<appender-ref ref="INFO_FILE" />
<appender-ref ref="WARN_FILE" />
<appender-ref ref="ERROR_FILE" />
<!--<appender-ref ref="METRICS_LOG" />-->
</root>
<!--生产环境:输出到文件-->
<!--<springProfile name="pro">-->
<!--<root level="info">-->
<!--<appender-ref ref="CONSOLE" />-->
<!--<appender-ref ref="DEBUG_FILE" />-->
<!--<appender-ref ref="INFO_FILE" />-->
<!--<appender-ref ref="ERROR_FILE" />-->
<!--<appender-ref ref="WARN_FILE" />-->
<!--</root>-->
<!--</springProfile>-->
</configuration>
上面我们关注两点
日志格式 pattern :
[2021-12-30T22:05:01.025+0800] [ERROR] [http-nio-8099-exec-1] [com.xiu.distributed.logcollection.web.IndexController] [PC-LR0940RK] [xx.xx.x.xx] [log-collection] [IndexController.java,31,com.xiu.distributed.logcollection.web.IndexController,err] 算术异常 ## 'java.lang.ArithmeticException: / by zero
[%d{yyyy-MM-dd’T’HH:mm:ss.SSSZZ}] : 时间戳 [2021-12-30T22:05:01.025+0800]
[%level{length=5}] 日志等级 info、warn、error、debug [ERROR]
[%thread] 线程名称 [http-nio-8099-exec-1]
[%logger] 当前类 [com.xiu.distributed.logcollection.web.IndexController]
[%hostName] 主机名 [PC-LR0940RK]
[%ip] 主机ip [xxx.xxxx.xx]
[%applicationName] 应用名 [log-collection]
[%F,%L,%C,%M] F 类名简写 L调用行数 C类名全称 M 调用方法名 [IndexController.java,31,com.xiu.distributed.logcollection.web.IndexController,err]
%m 日志打印信息 算术异常
##’%ex’ 如果有异常则抛出异常信息 ## 'java.lang.ArithmeticException: / by zero
%n 换行符
日志自定义数据设置
上述的ip、hostname、applicationName需要针对不同的项目需要动态配置获取 继承ClassicConverter
/**
* @author xieqx
* @className LogBackAppNameConfig
* @desc 获取当前应用名称放入logback中
* @date 2021/12/27 17:09
**/
@Component
public class LogBackAppNameConfig extends ClassicConverter implements EnvironmentAware {
private static Environment environment;
private static String appName = "unKnownAppName";
@Override
public String convert(ILoggingEvent event) {
try{
appName = environment.getProperty("spring.application.name");
}catch (Exception e){
}
return appName;
}
@Override
public void setEnvironment(Environment environment) {
LogBackAppNameConfig.environment = environment;
}
}
1.2 springBoot整合logback
spring:
application:
name: log-collection
# tomcat 服务配置
server:
port: 8099
tomcat:
accept-count: 1000
max-connections: 10000
max-threads: 800
min-spare-threads: 100
# logback 日志配置
logging:
config: classpath:logback-spring.xml
2 fileBeat安装
### 2.1 filebeat概念
Filebeat是本地文件的日志数据轻量级采集器。通过监视指定的日志文件或位置,收集日志事件,并将它们转发到es、Logstash、kafka等进行后续处理。
2.2 工作原理
开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测指定的日志目录或文件,对于每一个日志文件filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
- prospector: 负责管理harvester并找到所有要读取的文件来源。
- harvester : 负责读取单个文件的内容。读取每个文件,并将内容发送到 the output。
2.3 安装启动
#下载filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.1-linux-x86_64.tar.gz
#解压
tar -zxvf filebeat-6.2.1-linux-x86_64.tar.gz -C /usr/local/filebeat
#设置相关配置 (修改filebeat.yml) 后面单独给出
#检查filebeat配置是否正确
./filebeat -c filebeat.yml -configtest
Config OK #正常
#启动filebeat
./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
2.4 filebeat配置
配置直接从log_info.log、log_warn.log、log_error.log 分别输出到kafka的log-info-topic、log-warn-topic、log-error-topic上。
##################### Filebeat Configuration Example#########################
# For more available modules and options, please see the filebeat.reference.yml sample
#======================== Filebeat prospectors=======================
filebeat.prospectors
- input-type: log
### Multiline options
paths: '/home/coreapp/app/logs/log_info.log'
#定义写入kafka的type值
document_type: log-info-topic
multiline:
#正则表达式 匹配日志
pattern: '^\['
# 是否匹配到
negate: true
#合并到上一行的末尾
match: after
#最大的行数
max_lines: 2000
#超时时间
timeout: 2s
fields:
# kafka服务
logbiz: log-collection
# 服务对应的kafka-topic
logtopic: log-info-topic
evn: dev
- input-type: log
paths: '/home/coreapp/app/logs/log_warn.log'
#定义写入es的type值
document_type: log-warn-topic
multiline:
#正则表达式 匹配日志
pattern: '^\['
# 是否匹配到
negate: true
#合并到上一行的末尾
match: after
#最大的行数
max_lines: 2000
#超时时间
timeout: 2s
fields:
# kafka服务
logbiz: log-collection
# 服务对应的kafka-topic
logtopic: log-warn-topic
evn: dev
- input-type: log
paths: '/home/coreapp/app/logs/log_error.log'
#定义写入kafka的type值
document_type: log-error-topic
multiline:
#正则表达式 匹配日志
pattern: '^\['
# 是否匹配到
negate: true
#合并到上一行的末尾
match: after
#最大的行数
max_lines: 2000
#超时时间
timeout: 2s
fields:
# kafka服务
logbiz: log-collection
# 服务对应的kafka-topic
logtopic: log-error-topic
evn: dev
#============================= Filebeat modules ===============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# Period on which files under path should be checked for changes
#reload.period: 10s
#==================== Elasticsearch template setting==========================
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
#================================输出配置=====================================
#-------------------------- 输出到kafka------------------------------
# 输出日志到kafka
output.kafka:
# kafka 服务节点
hosts: ["xxx.xx.x.xxx:9092","xxx.xx.x.xxx:9093","xxx.xx.x.xxx:9094"]
# 动态引用上述三种不同级别的(info、warn、error)引入的fields的topic
topic: '%{[fields.logtopic]}'
partition.round_robin:
reachable_only: true
# 是否压缩文件
compression: gzip
max_message_bytes: 1000000
#集群收到消息ack确认个数
required_acks: 1
logging.to_files: true
3 logstash安装
3.1 logstash概念
Logstash 是一个实时数据收集引擎,可收集各类型数据并对其进行分析,过滤和归纳。按照自己条件分析过滤出符合数据导入到可视化界面。
3.2 logstash工作原理
3.3 安装启动
# 下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.0.1.tar.gz
# 解压
tar -zxvf logstash-6.0.1.tar.gz -C /usr/local/logstash/
# 配置详见3.4 配置详解
#启动logstash服务
./bin/logstash -f script/logstash-script.conf &
3.4 配置详解
logstash配置结构
#主要分成如下三大模块
input {
...#读取数据,logstash已提供非常多的插件,比如可以从file、redis、syslog等读取数据
}
filter {
...#想要从不规则的日志中提取关注的数据,就需要在这里处理。常用的有grok、mutate等
}
output {
...#输出数据,在上面处理后的数据输出到file、elasticsearch等
}
logstash详细配置
## 设置输入到logstash 这里配置kafka
input {
kafka {
#正则匹配kafka topic
topics => ["log-info-topic","log-warn-topic","log-error-topic"]
# kafka服务节点配置
bootstrap_servers => "xxx.xx.x.xxx:9092,xxx.xx.x.xxx:9093,xxx.xx.x.xxx:9094"
#用于处理json数据
codec => json
#设置consumer的并行消费线程数
consumer_threads => 2
decorate_events => true
#消费kafka 从message的哪个offset
auto_offset_reset => "latest"
#消费分组
group_id => "log-topic-group"
}
}
# 输出过滤
filter {
## 时区转换
ruby {
code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%M.%d'))"
}
if "log-info-topic" in [fields][logtopic]{
grok {
## 表达式 批次成功才会输出到es中
#格式基于我们上面logback配置的日志输出格式
match => ["message", "\[%{NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%{NOTSPACE:thread-id}\] \[%{NOTSPACE:class}\] \[%{DATA:hostName}\] \[%{DATA:ip}\] \[%{DATA:applicationName}\] \[%{DATA:location}\] \[%{DATA:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
if "log-warn-topic" in [fields][logtopic]{
grok {
## 表达式
match => ["message","\[%{NOTSPACE:currentDateTime}]\[%{NOTSPACE:level}]\[%{NOTSPACE:thread-id}]\[%{NOTSPACE:class}]\[%{DATA:hostName}]\[%{DATA:ip}]\[%{DATA:applicationName}]\[%{DATA:location}]\[%{DATA:messageInfo}]## (\'\'|%{QUOTEDSTRING:throwable}"]
}
}
if "log-error-topic" in [fields][logtopic]{
grok {
## 表达式
match => ["message","\[%{NOTSPACE:currentDateTime}]\[%{NOTSPACE:level}]\[%{NOTSPACE:thread-id}]\[%{NOTSPACE:class}]\[%{DATA:hostName}]\[%{DATA:ip}]\[%{DATA:applicationName}]\[%{DATA:location}]\[%{DATA:messageInfo}]## (\'\'|%{QUOTEDSTRING:throwable}"]
}
}
}
#设置多个输入流
#设置logstash的输出流 输出控制台 (方便调试查看)
output {
stdout { codec => rubydebug }
}
#设置logstash的输出流 这里配置是es
output {
if "log-info-topic" in [fields][logtopic]{
## es插件
elasticsearch {
# es服务地址
hosts => ["xxx.xx.x.xxx:9200"]
#用户名 密码
#user => "elastic"
#password => "123456"
## 设置索引前缀
index => "log-topic-%{[fields][logbiz]}-%{index_time}"
# 通过嗅探机制进行es集群负载均衡发送日志信息
sniffing => true
# logstash默认自带一个mapping模板 进行模板覆盖
template_overwrite => true
}
}
if "log-warn-topic" in [fields][logtopic]{
## es插件
elasticsearch {
# es服务地址
hosts => ["xxx.xx.x.xxx:9200"]
#用户名 密码
#user => "elastic"
#password => "123456"
## 设置索引前缀
index => "log-topic-%{[fields][logbiz]}-%{index_time}"
# 通过嗅探机制进行es集群负载均衡发送日志信息
sniffing => true
# logstash默认自带一个mapping模板 进行模板覆盖
template_overwrite => true
}
}
if "log-error-topic" in [fields][logtopic]{
## es插件
elasticsearch {
# es服务地址
hosts => ["xxx.xx.x.xxx:9200"]
#用户名 密码
#user => "elastic"
#password => "123456"
## 设置索引前缀
index => "log-topic-%{[fields][logbiz]}-%{index_time}"
# 通过嗅探机制进行es集群负载均衡发送日志信息
sniffing => true
# logstash默认自带一个mapping模板 进行模板覆盖
template_overwrite => true
}
}
}
4 es安装
4.1 es框架概念
Elasticsearch 是一个兼有搜索引擎和NoSQL数据库功能的开源系统,基于Java/Lucene构建,可以用于全文搜索,结构化搜索以及近实时分析
4.2 安装启动
#下载es
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.1-linux-x86_64.tar.gz
#解压项目
tar -zxvf elasticsearch-6.0.1.tar.gz -C /usr/local/elasticSearch/
#因为es服务不能直接使用root用户启动
#所以这里需要新建用户es 并为该用户赋予es使用权限
adduser es
chown -R es /usr/local/elasticSearch/elasticsearch-6.0.1
#启动es 切换到es用户
su es
./bin/elasticsearch &
#设置远程访问
#修改config中的elasticsearch.yml
#配置ip
network.host: xxx.xx.x.xxx
#配置端口
http.port: 9200
#重新启动es
# 启动可能报错
#max virtual memory areas vm.max_map_count [65530] is too low, increase to at #least [262144]
vi /etc/sysctl.conf
vm.max_map_count=655360
sysctl -p
#再进行重启
浏览器访问 成功显示如下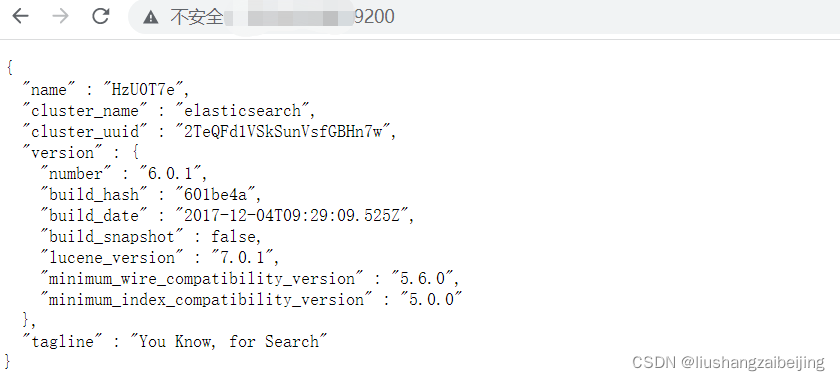
5、kbnana
5.1 kibana框架介绍
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。
5.2 安装启动
#下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.0.1-linux-x86_64.tar.gz
#进入目录 解压
tar -zxvf kibana-6.0.1-linux-x86_64.tar.gz
#修改配置
#配置本机ip
server.port:9201
server.host: "xxx.xxx.xxx.xxx"
#配置es集群url
elasticsearch.url: "http://xxx.xxx.xxx.xxx:9200"
# 启动es服务
./bin/kibnana &
验证
启动成功访问 ip端口
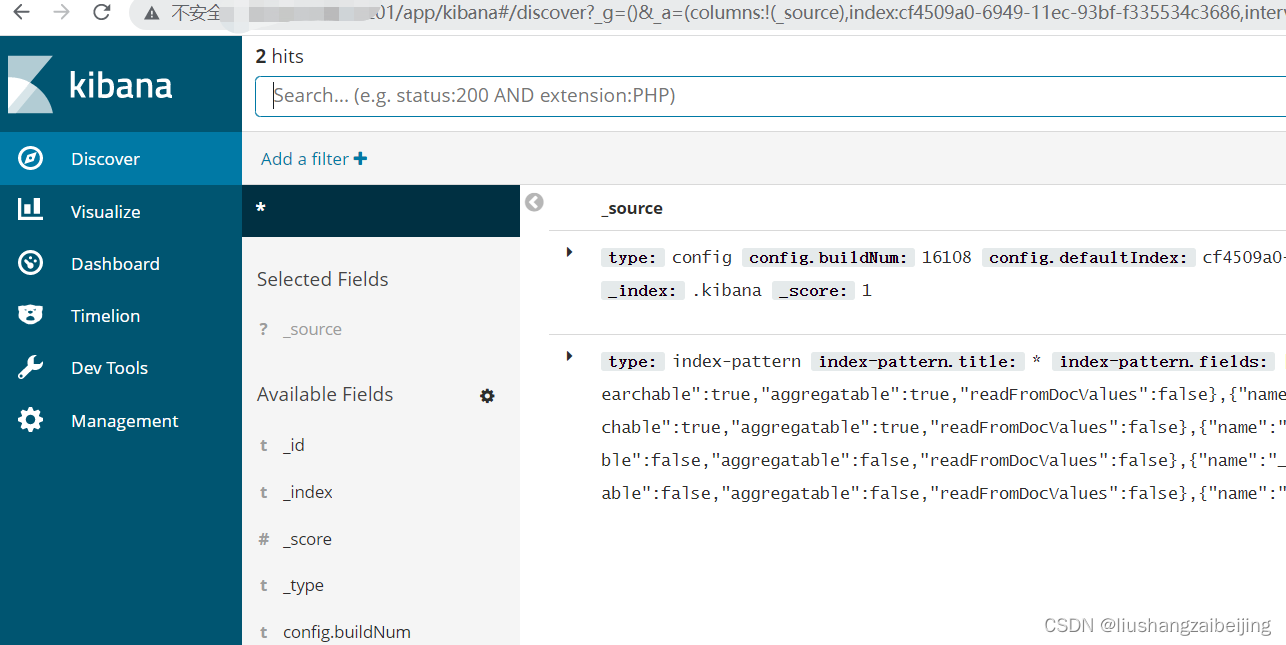
6 日志收集验证
添加http接口触发日志收集
@Slf4j
@RestController
public class IndexController {
@RequestMapping(value = "/index")
public String index() {
log.info("我是一条info日志");
log.warn("我是一条warn日志");
log.error("我是一条error日志");
return "idx";
}
@RequestMapping(value = "/err")
public String err() {
try {
int a = 1/0;
} catch (Exception e) {
log.error("算术异常", e);
log.info("算术异常", e);
log.warn("算术异常", e);
}
return "err";
}
}
通过页面请求url地址从而触发日志输出 最终通过kibana查看是否收集到日志 从kibana成功看到日志