1.使用bs4爬取软科大排名,首先我们要使用到三个库文件,requests库、bs4和pymysql;
2.获取网页
#获取网页
def getHTMLText(url):#获取URL信息,输出内容
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return""3.解析网页,在开发者模式中我们发现所有需要的信息都在tbody下面,所以我们先遍历tobody子节点,获取到我们想要的a、tr和td,再通过string方式找到想要的元素。
#解析网页
def parser(html):
soup = BeautifulSoup(html,"lxml")#将页面中的元素获取为一个soup对象
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):#如果tr标签的类型不是bs4库中定义的tag类型,则过滤掉
a = tr('a')#将所有的tr标签存为一个列表类型
tds = tr('td')#将所有的td标签存为一个列表类型
ulist.append([
a[0].string.strip(),
tds[2].text.strip(),
tds[3].text.strip(),
tds[4].text.strip(),
])4.存储到数据库,首先我们要在数据中建立一个表,我这里为名称、省市、类型、总分设置了字段,开始的ID我设置的是自增,这样就不用在爬取排名这个数字了。
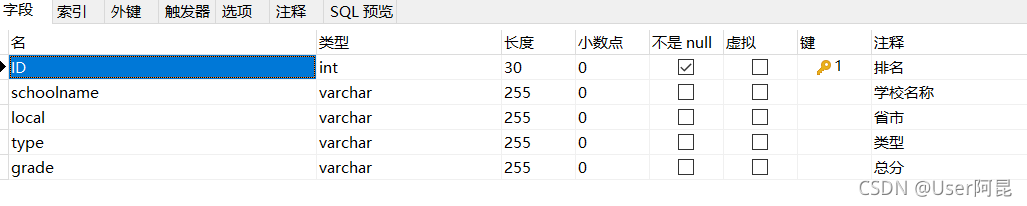
然后就是将我们网页中的数据存储到数据库中
#存储到数据库
def save_SQL(sql,**path):
try:
msql = pymysql.connect(**path)
my = msql.cursor()
for i in ulist:
values = tuple(i)
print(values)
my.execute(sql,values)
msql.commit()
except Exception as err:
msql.rollback()
print(err)
finally:
my.close()
msql.close()
path = {
"host":"127.0.0.1",
"user":"root",
"password":"123456",#数据库密码
"port":3306,
"db":"sys",#数据库名字
"charset":"utf8"
}
sql_jia = "insert into school(schoolname,local,type,grade) values (%s,%s,%s,%s)"#在python中设置的插入语句这样就可以完成 我们的爬取数据以及存储数据了,下面就是存储后数据库的显示
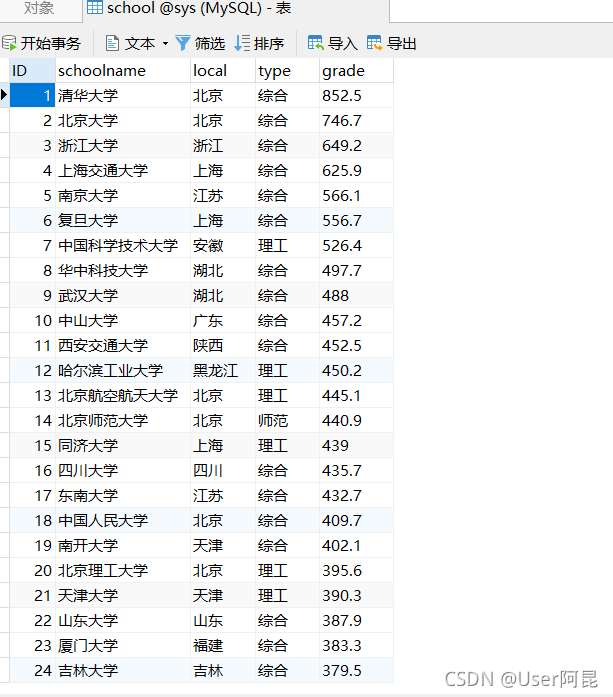
下面是完整代码:
import requests
from bs4 import BeautifulSoup
import bs4
import pymysql
ulist=[]
#获取网页
def getHTMLText(url):#获取URL信息,输出内容
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return""
#解析网页
def parser(html):
soup = BeautifulSoup(html,"lxml")#将页面中的元素获取为一个soup对象
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):#如果tr标签的类型不是bs4库中定义的tag类型,则过滤掉
a = tr('a')#将所有的tr标签存为一个列表类型
tds = tr('td')#将所有的td标签存为一个列表类型
ulist.append([
a[0].string.strip(),
tds[2].text.strip(),
tds[3].text.strip(),
tds[4].text.strip(),
])
#存储到数据库
def save_SQL(sql,**path):
try:
msql = pymysql.connect(**path)
my = msql.cursor()
for i in ulist:
values = tuple(i)
print(values)
my.execute(sql,values)
msql.commit()
except Exception as err:
msql.rollback()
print(err)
finally:
my.close()
msql.close()
path = {
"host":"127.0.0.1",
"user":"root",
"password":"123456",#数据库密码
"port":3306,
"db":"sys",#数据库名字
"charset":"utf8"
}
sql_jia = "insert into school(schoolname,local,type,grade) values (%s,%s,%s,%s)"#在python中设置的插入语句
if __name__=="__main__":
url="https://www.shanghairanking.cn/rankings/bcur/2020"
html = getHTMLText(url) #获取网页数据
out_list = parser(html) #解析网页,输出列表数据
save_SQL(sql_jia,**path)
#print(ulist)以上就是爬取软科大排名以及存储到数据的方法,供大家参考。
版权声明:本文为user__s原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。