在抖音上关注“按键精灵”(抖音号:anjian07),我们将不定期发布各类办公中、生活里会用到的脚本小技巧,本篇教程小视频,已发布于抖音,欢迎观看!
平常办公中经常需要从网页上摘取信息,填入excel,如果采集的信息多的话,还真是费时费力。那么这项工作如何让按键精灵来帮你搞定呢?往下看……
(本教程以按键论坛会员专区帖子信息录入为例子)
一、脚本思路
脚本大致分为两个部分:获取网页上的信息,把信息填入EXCEL表格
1、打开浏览器,进入目标网站
2、提取网页的信息,解析出需要的标题、链接、作者、时间等信息
3、打开EXCEL表格,填入对应的信息
二、插件命令
这次需要用到两个插件:【神梦填表】【懒人Office】(插件可到原文中下载)
1、【神梦填表】插件是用来对IE、Chrome浏览器进行操作的命令库,先来看下这次会用到的命令
命令名称:谷歌_启动命令功能:启动谷歌浏览器,并且将命令库内核切换为谷歌内核,可以使用的命令:以{方法_}和{网页_}开头的,还有{接码_}开头的命令参数:参数1【必选】:字符串,浏览器路径返回值:字符串,返回浏览器所有标识符,标识符用"||"分隔 |
命令名称:方法_网页打开命令功能:在当前标签页打开Url指定的网页命令参数:参数1【必选】:字符串,打开链接返回值:无 |
命令名称:方法_取状态命令功能:获得当前网页的状态命令参数:无返回值:整数型,返回网页状态:0=未初始化;1=正在载入;2=载入完成;3=解析交互;4=全部完成 |
命令名称:网页_执行JS命令功能:在当前网页中执行一段JS脚本,支持获取返回值命令参数:参数1【必选】:整数型,执行类型;类型:0表示执行JS不带返回值,1表示执行JS并返回返回值,需要JS中有 return 语句参数2【必选】:字符串,JS脚本语句返回值:字符串型,返回特征字符串 |
命令名称:网页_取元素信息命令功能:获取网页元素指定属性的信息命令参数:参数1【必选】:字符串,网页元素属性类型:参数2【必选】:字符串,元素特征返回值:字符串,获取到的网页元素的值 |
插件中的方法有很多,详细的命令使用方法和范例可以下载插件后在帮助文件里查看。2、【懒人Office】插件中用到了读写EXCEL命令的,相关命令可以看看上一篇的教程:如何用脚本进行EXCEL数据对比?详解来了!【附按键源码】
三、脚本实现
先获取下界面上的一些配置信息。
// 初始化配置
Dim ChromePath, ExcelPath
// 这里需要换成自己本机上的谷歌浏览器路径
ChromePath = "C:\Program Files\Google\Chrome\Application\chrome.exe"
ExcelPath = Form1.BrowseBox1.Path
通过插件来打开浏览器并且等待网页的加载完成。
// 打开谷歌浏览器
ret = 神梦_网页填表.谷歌_启动(ChromePath)
If ret = "" Then
TracePrint "启动失败,请先彻底关闭谷歌浏览器,再启动脚本!"
ExitScript
Else
TracePrint "启动成功!"
End If
// 等待网页的加载完成
Call 神梦_网页填表.方法_网页打开("http://bbs.anjian.com/showforum-219-1.aspx")
Do
Delay 500
Loop Until 神梦_网页填表.方法_取状态() = 4
接下来就开始获取网页里帖子的信息了,需要先来获取一下帖子的数量,这里是用执行JS的方法来获取的。
// 通过执行JS来获取当页帖子的数量
Dim PostCount
PostCount = Cint(神梦_网页填表.网页_执行JS(1, "return document.getElementsByClassName('ordinarytheme').length"))
TracePrint PostCount
通过分析网页的结构,可以发现每条帖子所需要的信息都是在一个tbody标签里的,所以我们可以获取每个tbody里的内容,然后用正则表达式来解析获取出想要的信息。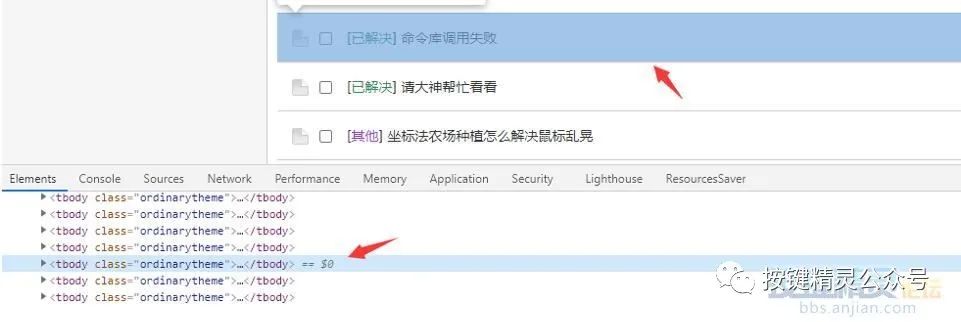 先来编写一个正则解析的函数,因为按键精灵本身没有相关的命令,所以我们需要借助VBS的功能来实现(按键精灵和VBS有比较高的兼容性,可以运行大部分的VBS代码)。
先来编写一个正则解析的函数,因为按键精灵本身没有相关的命令,所以我们需要借助VBS的功能来实现(按键精灵和VBS有比较高的兼容性,可以运行大部分的VBS代码)。
Function RegexFindM(FindExp, FindText)
Dim RegEx, Matches, Match
Set RegEx = New RegExp
RegEx.IgnoreCase = true
RegEx.Pattern = FindExp
Set Matches = regEx.Execute(FindText)
If Matches.Count > 0 Then
If Matches(0).SubMatches.Count > 0 Then
RegexFindM = Matches(0).SubMatches(0)
End If
End If
Set Matches = Nothing
Set RegEx = Nothing
End Function
现在就可以通过遍历每个帖子的元素内容解析出想要的信息了。
// 遍历每个帖子
Dim HTML
For i = 13 To PostCount + 12
HTML = 神梦_网页填表.网页_取元素信息("html", "//*[@id='threadlist']/tbody[" & i & "]")
PostTitle = RegexFindM("([^", HTML)
PostUrl = RegexFindM("[^", HTML)
PostUser = RegexFindM("([^", HTML)
PostDate = RegexFindM("(\d\d\d\d-\d\d-\d\d \d\d:\d\d)", HTML)
PostUrl = "http://bbs.anjian.com" & PostUrl
TracePrint PostTitle & ", " & PostUrl & ", " & PostUser & ", " & PostDate
Delay 500
Next
信息获取到了,那我们还得写到EXCEL表格里呢,所以得小小的改动下这个代码,加上写入表格的功能,这样全部功能就实现了。
有兴趣的小伙伴请点左下角“”即可下载完整源码用于学习,希望这篇教程对你有帮助哦!
❤抖音扫码关注我们❤