案例一
现有三个文件,分别放置五个学生三门学科成绩
如下图所示,需要通过mapreduce程序,找出每一个学生的最高分和平均分
最高分
map函数
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
StringTokenizer st = new StringTokenizer(value.toString());
while(st.hasMoreTokens()){
Text sid = new Text(st.nextToken());
IntWritable score = new IntWritable(Integer.parseInt(st.nextToken()));
context.write(sid, score);
}
}
}
reduce函数
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
int maxscore = 0;
for(IntWritable value:values){
maxscore=Math.max(maxscore, value.get());
}
context.write(key, new IntWritable(maxscore));
}
}
驱动类
public class MyDriver {
public static void main(String[] args) throws Exception {
// 创建配置信息
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path("E:/data/score/maxoutput");
if(fs.exists(path)){
fs.delete(path);
}
Job job = Job.getInstance(conf,"maxscore");
//设置主类
job.setJarByClass(MyDriver.class);
//设置map函数的类型
job.setMapperClass(MyMapper.class);
//设置reduce函数的类型
job.setReducerClass(MyReducer.class);
//设置输出键值对的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出路径
FileInputFormat.addInputPath(job, new Path("E:/data/score/input/*"));
FileOutputFormat.setOutputPath(job, new Path("E:/data/score/maxoutput"));
//查看状态,退出程序
System.exit(job.waitForCompletion(true)?0:1);
}
}
运行结果
平均分(使用KeyValueTextInputFormat)
KeyValueTextInputFormat:
如果行中有分隔符,那么分隔符前面的作为key,后面的作为value 如果行中没有分隔符,那么整行作为key,value为空 默认分隔符为 \t
map函数
public class MyMapper extends Mapper<Text, Text, Text, IntWritable>{
@Override
protected void map(Text key, Text value,Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
int a=Integer.parseInt(value.toString());
context.write(new Text(key.toString()),new IntWritable(a));
}
}
reduce函数
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> value,Context context)
throws IOException, InterruptedException {
int sum = 0;
int count = 0;
for(IntWritable score : value){
sum+=score.get();
count++;
}
int avgcore = sum/count;
context.write(key, new IntWritable(avgcore));
}
}
驱动类
public class MyDriver {
public static void main(String[] args) throws Exception {
// 创建配置信息
Configuration conf = new Configuration();
//设置行的分隔符,这里是制表符,第一个制表符前面的是Key,第一个制表符后面的内容都是value
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");
FileSystem fs = FileSystem.get(conf);
Path path = new Path("E:/data/score/avgoutput1");
if(fs.exists(path)){
fs.delete(path);
}
Job job = Job.getInstance(conf,"avgscore");
//指定输入格式
job.setInputFormatClass(KeyValueTextInputFormat.class);
//设置主类
job.setJarByClass(MyDriver.class);
//设置map函数的类型
job.setMapperClass(MyMapper.class);
//设置reduce函数的类型
job.setReducerClass(MyReducer.class);
//设置输出键值对的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出路径
FileInputFormat.addInputPath(job, new Path("E:/data/score/input/*"));
FileOutputFormat.setOutputPath(job, new Path("E:/data/score/avgoutput1"));
//查看状态,退出程序
System.exit(job.waitForCompletion(true)?0:1);
}
}
运行结果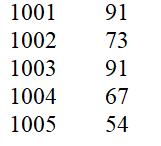
版权声明:本文为WQY992原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。