01. 引言
R的recommenderlab包可以实现协同过滤算法。这个包中有许多关于推荐算法建立、处理及可视化的函数。 本文任务:选用recommenderlab包中内置的MovieLense数据集进行分析,该数据集收集了网站MovieLens(movielens.umn.edu)从1997年9月19日到1998年4月22日的数据,包括943名用户对1664部电影的评分。library(recommenderlab)library(ggplot2)02. 数据处理与探索性分析
data(MovieLense)image(MovieLense)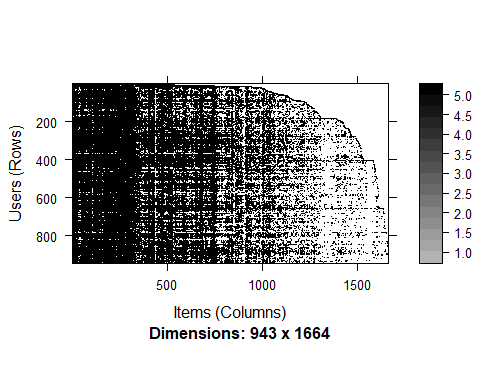
# 获取评分ratings.movie summary(ratings.movie$ratings)ggplot(ratings.movie, aes(x = ratings)) + geom_histogram(fill = "beige", color = "black", binwidth = 1, alpha = 0.7) + xlab("rating") + ylab("count")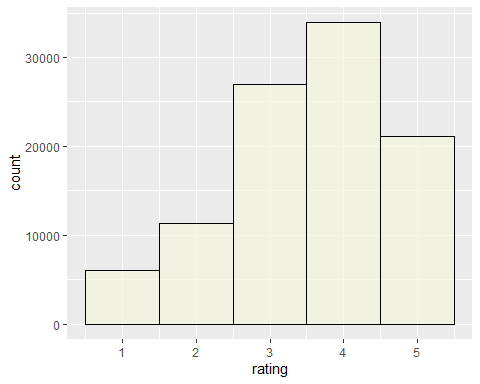
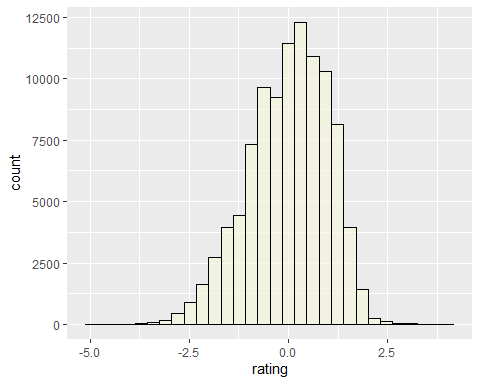
atings.movie1 getRatings(normalize(MovieLense, method = "Z-score")))summary(ratings.movie1$ratings)## Min. 1st Qu. Median Mean 3rd Qu. Max.## -4.852 -0.647 0.108 0.000 0.751 4.128ggplot(ratings.movie1, aes(x = ratings)) + geom_histogram(fill = "beige", color = "black", alpha = 0.7) + xlab("rating") + ylab("count")movie.count count = rowCounts(ggplot(movie.count, aes(x = count)) + geom_histogram(fill = "beige", color = "black", alpha = 0.7) + xlab("counts of users") + ylab("counts of movies rated")
rating.mean <- data.frame(rating = colMeans(MovieLense))ggplot(rating.mean, aes(x = rating)) + geom_histogram(fill = "beige", color = "black", alpha = 0.7) + xlab("rating") + ylab("counts of movies ")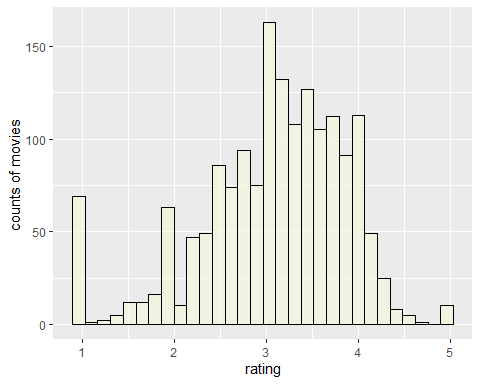
03. 建立推荐模型与模型评估
对于realRatingMatrix有六种方法:IBCF(基于物品的推荐)、UBCF(基于用户的推荐)、SVD(矩阵因子化)、PCA(主成分分析)、 RANDOM(随机推荐)、POPULAR(基于流行度的推荐)。模型评估主要使用:recommenderlab包中自带的评估方案,对应的函数是evaluationScheme,能够设置采用n-fold交叉验证还是简单的training/train分开验证,本文采用后一种方法,即将数据集简单分为training和test,在training训练模型,然后在test上评估。接下来我们使用三种不同技术进行构建推荐系统,并利用评估方案比较三种技术的好坏。library(recommenderlab)data(MovieLense)scheme "split", train = 0.9, k = 1, given = 10, goodRating = 4)algorithms list(popular = param = list(normalize = "Z-score")), ubcf = list(name = "UBCF", param = list(normalize = "Z-score", method = "Cosine",nn = 25, minRating = 3)), ibcf = list(name = "IBCF", param = list(normalize = "Z-score")))results 1, plot(results, annotate = 1:3, legend = "topleft") #ROC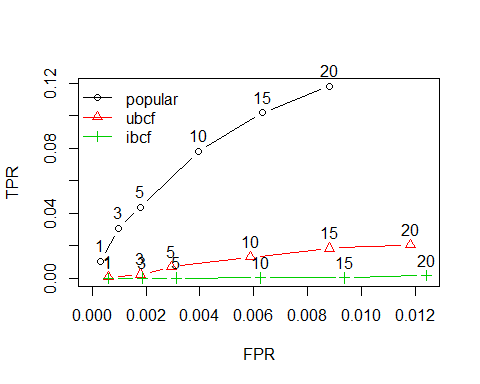
plot(results, "prec/rec", annotate = 3)#precision-recall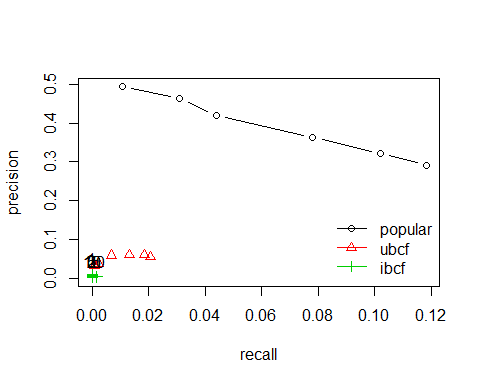
按照评价方案建立推荐模型
model.popular "train"), method = model.ibcf "train"), method = model.ubcf "train"), method = # 对推荐模型进行预测predict.popular "known"), predict.ibcf "known"), predict.ubcf "known"), # 做误差的计算predict.err getData(scheme, "unknown")),calcPredictionAccuracy(predict.ubcf, getData(scheme, "unknown")), calcPredictionAccuracy(predict.ibcf,getData(scheme, "unknown")))rownames(predict.err) "POPULAR", predict.err| RMSE | MSE | MAE | |
| POPULAR | 1.046 | 1.095 | 0.8315 |
| UBCF | 1.217 | 1.481 | 0.9662 |
| IBCF | 1.693 | 2.866 | 1.2397 |
通过结果我们可以看到:基于流行度推荐系统对于本案例数据的效果最好,RMSE,MSE,MAE都是三者中的最小值。其次是基于用户的推荐,最后是基于项目协同过滤。
04. 参考资料
1. Recommenderlab包实现电影评分预测(R语言)
2. R语言:recommenderlab包的总结与应用案例
3. recommender system handbook
4. Item-Based Collaborative Filtering Recommendation Algorithms
5. recommenderlab: A Framework for Developing and Testing Recommendation Algorithms
代码,数据与相关资料已放在我的github上了,见文末阅读原文。
欢迎批评指正,可文末留言,也可qq:641292753交流。欢迎关注闪闪的学习公众号,来和我一起学习吧!
