1. GROUPING SETS
在一个GROUP BY 查询中,根据不同的维度组合进行聚合。GROUPING SETS就是一种将多个GROUP BY逻辑UNION在一起。GROUPING SETS会把在单个GROUP BY逻辑中没有参与GROUP BY的那一列置为NULL值。空分组集意味着所有行都聚合到一个组中
SELECT supplier_id, rating, COUNT(*) AS total
FROM (VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4))
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ())
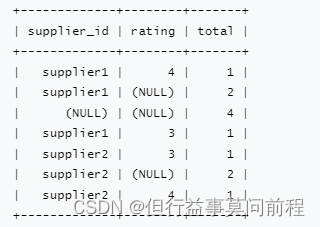
代码实例:
public class TableExample {
public static void main(String[] args) throws Exception {
// 获取流执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
//获取表执行环境
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);
Table eventTable = tableEnvironment.fromDataStream(eventStream, $("url"), $("user"), $("timestamp").as("times"));
//eventTable.printSchema();
tableEnvironment.createTemporaryView("myTable", eventTable);
Table resultTable = tableEnvironment.sqlQuery("select url,user,count(times) from myTable group by GROUPING SETS ((url,user),(url),(user))");
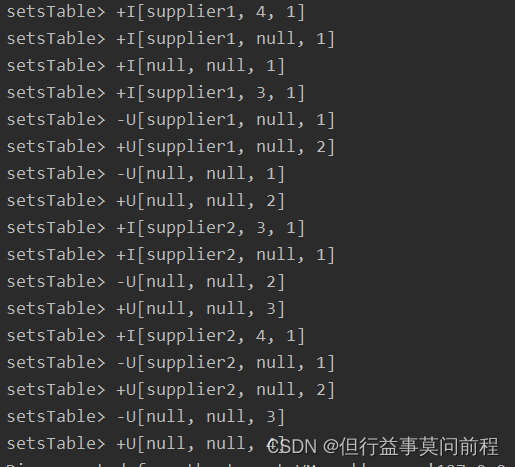
Table setsTable = tableEnvironment.sqlQuery("SELECT supplier_id, rating, COUNT(*) AS total\n" +
"FROM (VALUES\n" +
" ('supplier1', 'product1', 4),\n" +
" ('supplier1', 'product2', 3),\n" +
" ('supplier2', 'product3', 3),\n" +
" ('supplier2', 'product4', 4))\n" +
"AS Products(supplier_id, product_id, rating)\n" +
"GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ())");
tableEnvironment.toChangelogStream(setsTable).print("setsTable");
// TableResult tableResult = tableEnvironment.executeSql(" explain plan for select url,user,sum(times) from myTable group by GROUPING SETS ((url,user),(url),(user))");
Table rowNumTable = tableEnvironment.sqlQuery("SELECT user, url, times, row_num\n" +
"FROM (\n" +
" SELECT *,\n" +
" ROW_NUMBER() OVER (\n" +
"PARTITION BY user\n" +
" ORDER BY CHAR_LENGTH(url) desc \n" +
") AS row_num\n" +
" FROM myTable)\n" +
"WHERE row_num <= 2");
// tableResult.print();
// Table resultTable = eventTable.select($("url"));
// tableEnvironment.toDataStream(resultTable).print();
// tableEnvironment.toChangelogStream(resultTable).print();
// tableEnvironment.toChangelogStream(rowNumTable).print();
env.execute();
}
}
2. TTL
在持续查询的过程中,由于用于分组的 key 可能会不断增加,因此计算结果所需要维护的状态也会持续增长。为了防止状态无限增长耗尽资源,Flink Table API 和 SQL 可以在表环境中配置状态的生存时间(TTL):
TableEnvironment tableEnv = ...
// 获取表环境的配置
TableConfig tableConfig = tableEnv.getConfig();
// 配置状态保持时间
tableConfig.setIdleStateRetention(Duration.ofMinutes(60));
或
TableEnvironment tableEnv = ...
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setString("table.exec.state.ttl", "60 min");
配置 TTL 有可能会导致统计结果不准确,这其实是以牺牲正确性为代价换取了资源的释放
版权声明:本文为javahelpyou原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。