系列文章目录
近红外光谱分析技术属于交叉领域,需要化学、计算机科学、生物科学等多领域的合作。为此,在(北京邮电大学杨辉华老师团队)指导下,近期准备开源传统的PLS,SVM,ANN,RF等经典算和SG,MSC,一阶导,二阶导等预处理以及GA等波长选择算法以及CNN、AE等最新深度学习算法,以帮助其他专业的更容易建立具有良好预测能力和鲁棒性的近红外光谱模型。
文章目录
前言
NIRS是介于可见光和中红外光之间的电磁波,其波长范围为(1100∼2526 nm。 由于近红外光谱区与有机分子中含氢基团(OH、NH、CH、SH)振动的合频和 各级倍频的吸收区一致,通过扫描样品的近红外光谱,可以得到样品中有机分子含氢 基团的特征信息,常被作为获取样本信息的一种有效的载体。 基于NIRS的检测方法具有方便、高效、准确、成本低、可现场检测、不 破坏样品等优势,被广泛应用于各类检测领域。但 近红外光谱存在谱带宽、重叠较严重、吸收信号弱、信息解析复杂等问题,与常用的 化学分析方法不同,仅能作为一种间接测量方法,无法直接分析出被测样本的含量或 类别,它依赖于化学计量学方法,在样品待测属性值与近红外光谱数据之间建立一个 关联模型(或称校正模型,Calibration Model) ,再通过模型对未知样品的近红外光谱 进行预测来得到各性质成分的预测值。现有近红外建模方法主要为经典建模 (预处理+波长筛选进行特征降维和突出,再通过pls、svm算法进行建模)以及深度学习方法(端到端的建模,对预处理、波长选择等依赖性很低)本篇主要讲述CNN的的近红外光谱定性分析建模方法
一、数据来源
使用药品数据,共310个样本,每条样本404个变量,根据活性成分,分成4类
图片如下:
:
# global data_x
data_path = './/Data//table.csv'
Rawdata = np.loadtxt(open(data_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
table_random_state = seed
if tp =='raw':
data_x = Rawdata[0:, start:end]
if tp =='SG':
SGdata_path = './/Data//TableSG.csv'
data = np.loadtxt(open(SGdata_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
data_x = data[0:, start:end]
if tp =='SNV':
SNVata_path = './/Data//TableSNV.csv'
data = np.loadtxt(open(SNVata_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
data_x = data[0:, start:end]
if tp == 'MSC':
MSCdata_path = './/Data//TableMSC.csv'
data = np.loadtxt(open(MSCdata_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
data_x = data[0:, start:end]
data_y = Rawdata[0:, -1]
x_col = np.linspace(7400, 10507, 404)
plotspc(x_col, data_x[:, :], tp=0)
x_data = np.array(data_x)
y_data = np.array(data_y)
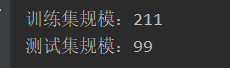
print('训练集规模:{}'.format(len(X_train[:,0])))
print('测试集规模:{}'.format(len(X_test[:,0])))
2 .2 划分数据集
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data, test_size=test_ratio,random_state=table_random_state)
2 .3 返回训练集和测试集并绘制光谱图片
data_train, data_test = ZspPocess(X_train, X_test,y_train,y_test,need=True) #for cnn :false only used in proseesing comparsion
return data_train, data_test

:
def __init__(self, nls):
super(CNN3Lyaers, self).__init__()
self.CONV1 = nn.Sequential(
nn.Conv1d(1, 64, 21, 1),
nn.BatchNorm1d(64), # 对输出做均一化
nn.ReLU(),
nn.MaxPool1d(3, 3)
)
self.CONV2 = nn.Sequential(
nn.Conv1d(64, 64, 19, 1),
nn.BatchNorm1d(64), # 对输出做均一化
nn.ReLU(),
nn.MaxPool1d(3, 3)
)
self.CONV3 = nn.Sequential(
nn.Conv1d(64, 64, 17, 1),
nn.BatchNorm1d(64), # 对输出做均一化
nn.ReLU(),
nn.MaxPool1d(3, 3),
)
self.fc = nn.Sequential(
# nn.Linear(4224, nls)
nn.Linear(384, nls)
)
def forward(self, x):
x = self.CONV1(x)
x = self.CONV2(x)
x = self.CONV3(x)
x = x.view(x.size(0), -1)
# print(x.size())
out = self.fc(x)
out = F.softmax(out,dim=1)
return out
2.5 训练1-D CNN模型
def CNNTrain(tp, test_ratio, BATCH_SIZE, n_epochs, nls):
# data_train, data_test = DataLoad(tp, test_ratio, 0, 404)
data_train, data_test = TableDataLoad(tp, test_ratio, 0, 404, seed=80)
train_loader = torch.utils.data.DataLoader(data_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(data_test, batch_size=BATCH_SIZE, shuffle=True)
store_path = ".//model//all//CNN18"
model = CNN3Lyaers(nls=nls).to(device)
optimizer = optim.Adam(model.parameters(),
lr=0.0001,weight_decay=0.0001)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.5, verbose=1, eps=1e-06,
patience=10)
criterion = nn.CrossEntropyLoss().to(device) # 损失函数为焦损函数,多用于类别不平衡的多分类问题
early_stopping = EarlyStopping(patience=30, delta=1e-4, path=store_path, verbose=False)
for epoch in range(n_epochs):
train_acc = []
for i, data in enumerate(train_loader): # gives batch data, normalize x when iterate train_loader
model.train() # 不训练
inputs, labels = data # 输入和标签都等于data
inputs = Variable(inputs).type(torch.FloatTensor).to(device) # batch x
labels = Variable(labels).type(torch.LongTensor).to(device) # batch y
output = model(inputs) # cnn output
trian_loss = criterion(output, labels) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
trian_loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
_, predicted = torch.max(output.data, 1)
y_predicted = predicted.detach().cpu().numpy()
y_label = labels.detach().cpu().numpy()
acc = accuracy_score(y_label, y_predicted)
train_acc.append(acc)
with torch.no_grad(): # 无梯度
test_acc = []
testloss = []
for i, data in enumerate(test_loader):
model.eval() # 不训练
inputs, labels = data # 输入和标签都等于data
inputs = Variable(inputs).type(torch.FloatTensor).to(device) # batch x
labels = Variable(labels).type(torch.LongTensor).to(device) # batch y
outputs = model(inputs) # 输出等于进入网络后的输入
test_loss = criterion(outputs, labels) # cross entropy loss
_, predicted = torch.max(outputs.data,1)
predicted = predicted.cpu().numpy()
labels = labels.cpu().numpy()
acc = accuracy_score(labels, predicted)
test_acc.append(acc)
testloss.append(test_loss.item())
avg_loss = np.mean(testloss)
scheduler.step(avg_loss)
early_stopping(avg_loss, model)
if early_stopping.early_stop:
print(f'Early stopping! Best validation loss: {early_stopping.get_best_score()}')
break
2.6 测试1-D CNN模型
def CNNtest(tp, test_ratio, BATCH_SIZE, nls):
# data_train, data_test = DataLoad(tp, test_ratio, 0, 404)
data_train, data_test = TableDataLoad(tp, test_ratio, 0, 404, seed=80)
test_loader = torch.utils.data.DataLoader(data_test, batch_size=BATCH_SIZE, shuffle=True)
store_path = ".//model//all//CNN18"
model = CNN3Lyaers(nls=nls).to(device)
model.load_state_dict(torch.load(store_path))
test_acc = []
for i, data in enumerate(test_loader):
model.eval() # 不训练
inputs, labels = data # 输入和标签都等于data
inputs = Variable(inputs).type(torch.FloatTensor).to(device) # batch x
labels = Variable(labels).type(torch.LongTensor).to(device) # batch y
outputs = model(inputs) # 输出等于进入网络后的输入
_, predicted = torch.max(outputs.data, 1)
predicted = predicted.cpu().numpy()
labels = labels.cpu().numpy()
acc = accuracy_score(labels, predicted)
test_acc.append(acc)
return np.mean(test_acc)
2.7 运行CNN模型,并用查看结果
得到模型精度
为了更仔细看模型错误原因,使用混淆矩阵进一步看,结果如下: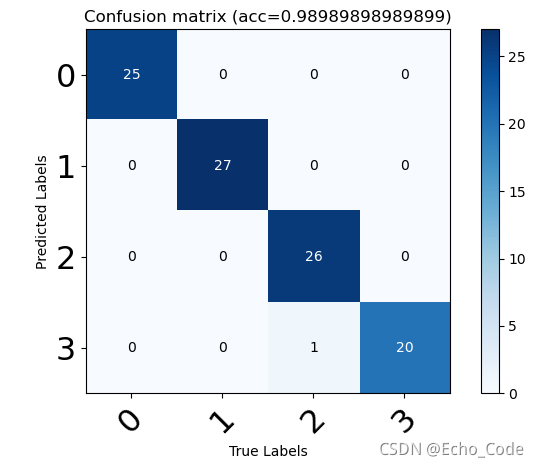
若有问题,可以相互学习探讨
总结
完整代码可从获得GitHub仓库 如果对您有用,请点赞!
代码仅供学术使用,如有问题,联系方式:QQ:1427950662,微信:Fu_siry