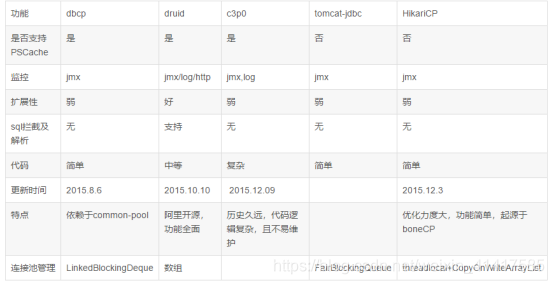
先了解什么是druid
Druid是阿里开源的数据库连接池,作为后起之秀,性能比dbcp、c3p0更高,使用也越来越广泛。
当然Druid不仅仅是一个连接池,还有很多其他的功能。它还包含一个ProxyDriver,一系列内置的JDBC组件库,一个 SQL Parser。支持所有JDBC兼容的数据库,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等等。Druid针对Oracle和MySql做了特别优化,比如Oracle的PS Cache内存占用优化,MySql的ping检测优化。Druid提供了MySql、Oracle、Postgresql、SQL-92的SQL的完整支持,这是一个手写的高性能SQL Parser,支持Visitor模式,使得分析SQL的抽象语法树很方便。简单SQL语句用时10微秒以内,复杂SQL用时30微秒。通过Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。Druid防御SQL注入攻击的WallFilter就是通过Druid的SQL Parser分析语义实现的
Druid的优点
- 替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
- 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
- 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
- SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况
- 扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter机制,很方便编写JDBC层的扩展插件。
配置Druid基于springboot
maven的pom文件引入依赖
只引入这个starter即可
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.9</version>
</dependency>
基础连接池配置,主要是配置数据库的账户密码,还有连接池的参数
spring.datasource.url=jdbc:mysql://数据库的IP:3306/数据库名?characterEncoding=utf-8&useSSL=false&useUnicode=true
spring.datasource.username=账户
spring.datasource.password=密码
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
# 连接池指定 springboot2.02版本默认使用HikariCP 此处要替换成Druid
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
## 初始化连接池的连接数量 大小,最小,最大
spring.datasource.druid.initialSize=5
spring.datasource.druid.minIdle=5
spring.datasource.druid.maxActive=20
## 配置获取连接等待超时的时间
spring.datasource.druid.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.druid.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.druid.minEvictableIdleTimeMillis=300000
spring.datasource.druid.validationQuery=SELECT 1 FROM DUAL
spring.datasource.druid.testWhileIdle=true
spring.datasource.druid.testOnBorrow=false
spring.datasource.druid.testOnReturn=false
# 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开
spring.datasource.druid.poolPreparedStatements=true
spring.datasource.druid.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
spring.datasource.druid.filters=stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.druid.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# !!!请勿配置timeBetweenLogStatsMillis 会定时输出日志 并导致统计的sql清零
#spring.datasource.druid.timeBetweenLogStatsMillis=20000
基础监控配置(主要是配置监控的身份验证信息)
# WebStatFilter配置,说明请参考Druid Wiki,配置_配置WebStatFilter
#是否启用StatFilter默认值true
spring.datasource.druid.web-stat-filter.enabled=true
##spring.datasource.druid.web-stat-filter.url-pattern=
spring.datasource.druid.web-stat-filter.exclusions=*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*
# StatViewServlet配置,说明请参考Druid Wiki,配置_StatViewServlet配置
#是否启用StatViewServlet默认值true
spring.datasource.druid.stat-view-servlet.enabled=true
spring.datasource.druid.stat-view-servlet.url-pattern=/druid/*
spring.datasource.druid.stat-view-servlet.reset-enable=false
spring.datasource.druid.stat-view-servlet.login-username=admin
spring.datasource.druid.stat-view-servlet.login-password=123456
监控配置
# Spring监控,对内部各接口调用的监控
spring.datasource.druid.aop-patterns=com.company.project.service.*,com.company.project.dao.*,com.company.project.controller.*,com.company.project.mapper.*
#禁止手动重置监控数据
spring.datasource.druid.stat-view-servlet.reset-enable=false
#设置监控页面的登录名和密码
spring.datasource.druid.stat-view-servlet.login-username=admin
spring.datasource.druid.stat-view-servlet.login-password=123456
#设置不统计哪些URL
spring.datasource.druid.web-stat-filter.exclusions=*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*
#设置使用哪些插件 stat是统计,wall是SQL防火墙,防SQL注入的,log4j是用来输出统计数据的(我觉得这个没啥用,输出日志我又重写了个工具类)
spring.datasource.druid.filters=stat,wall,log4j
Druid注意事项
由于连接池指定springboot2.02版本默认使用HikariCP 此处要替换成Druid
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
#初始化大小,最小,最大
spring.datasource.druid.initialSize=5
spring.datasource.druid.minIdle=5
spring.datasource.druid.maxActive=20
#配置获取连接等待超时的时间
spring.datasource.druid.maxWait=60000
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.druid.timeBetweenEvictionRunsMillis=60000
#配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.druid.minEvictableIdleTimeMillis=300000
spring.datasource.druid.validationQuery=SELECT 1 FROM DUAL
spring.datasource.druid.testWhileIdle=true
spring.datasource.druid.testOnBorrow=false
spring.datasource.druid.testOnReturn=false
#是否缓存preparedStatement,也就是PSCache MySQL下建议关闭
spring.datasource.druid.poolPreparedStatements=true
spring.datasource.druid.maxPoolPreparedStatementPerConnectionSize=20
#配置监控统计拦截的filters,去掉后监控界面sql无法统计,’wall’用于防火墙
spring.datasource.druid.filters=stat,wall,log4j
#通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.druid.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
#特别注意请勿配置timeBetweenLogStatsMillis 会定时输出日志 并导致统计的sql清零
spring.datasource.druid.timeBetweenLogStatsMillis=20000
#配置Druid的日志输出
spring.datasource.druid.filter.slf4j.enabled=true
spring.datasource.druid.filter.slf4j.statement-create-after-log-enabled=false
spring.datasource.druid.filter.slf4j.statement-close-after-log-enabled=false
spring.datasource.druid.filter.slf4j.result-set-open-after-log-enabled=false
spring.datasource.druid.filter.slf4j.result-set-close-after-log-enabled=false
#WebStatFilter配置,说明请参考Druid Wiki,配置_配置WebStatFilter是否启用StatFilter默认值true
spring.datasource.druid.web-stat-filter.enabled=true
spring.datasource.druid.web-stat-filter.url-pattern=
spring.datasource.druid.web-stat-filter.exclusions=.js,.gif,.jpg,.png,.css,.ico,/druid/*
spring.datasource.druid.web-stat-filter.session-stat-enable=true
spring.datasource.druid.web-stat-filter.session-stat-max-count=100
#身份标识 从session中获取
spring.datasource.druid.web-stat-filter.principal-session-name=
#身份标识 从cookie中获取 例如cookie中存gk=xiaoming 设置属性为gk即可user信息保存在cookie中,你可以配置principalCookieName,使得druid知道当前的user是谁
spring.datasource.druid.web-stat-filter.principal-cookie-name=
#配置profileEnable能够监控单个url调用的sql列表。
spring.datasource.druid.web-stat-filter.profile-enable=true
druid内置监控页面
配置好上面的参数启动项目后,访问页面http://127.0.0.1:8769/druid/sql.html,就可以访问监控页面了,其中ip和端口号为项目的ip和端口号
如图: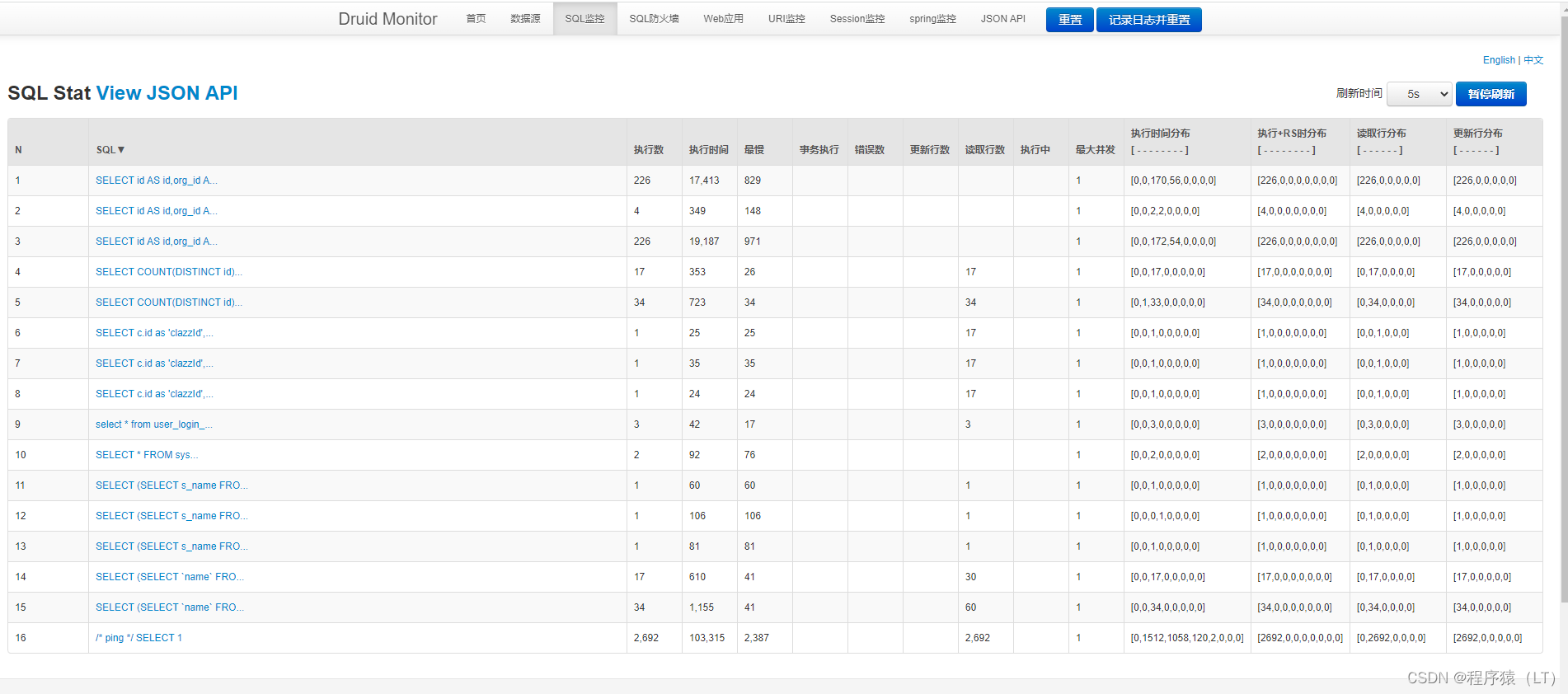
Spring Boot配置多数据源并实现Druid自动切换
由于小编使用的是MyBatis-Plus(是一个 MyBatis 的增强工具)所以介绍在使用MyBatis-Plus情况下的数据源切换
1.首先引入依赖
<!-- MyBatis Plus 依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
<scope>compile</scope>
</dependency>
2.修改yml配置文件
spring:
datasource:
druid:
db1:
# mysql默认数据库的配置
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/backend_dev?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: 123456
initialSize: 5
minIdle: 5
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
db2:
# mysql第二个库的配置
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/backend_log_dev?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
password: 123456
initialSize: 5
minIdle: 5
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
3.数据源枚举
/**
* @author
* @description 数据源枚举
*/
public enum DBTypeEnum {
DB1("db1"), DB2("db2");
private String value;
DBTypeEnum(String value) {
this.value = value;
}
public String getValue() {
return value;
}
}
- 标记数据源的注解
/**
* @author
* @description 数据源注解
*/
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MyDataSource {
DBTypeEnum value() default DBTypeEnum.DB1;
}
- 动态数据源管理器
/**
* @author:
* @description: 设置、获取数据源
* @date:
**/
public class DataSourceContextHolder {
private static final ThreadLocal contextHolder = new ThreadLocal<>(); //开启多个线程,每个线程初始化一个数据源
/**
* 设置数据源
* @param dbTypeEnum
*/
public static void setDbType(DBTypeEnum dbTypeEnum) {
contextHolder.set(dbTypeEnum.getValue());
}
/**
* 取得当前数据源
* @return
*/
public static String getDbType() {
return (String) contextHolder.get();
}
/**
* 清除上下文数据
*/
public static void clearDbType() {
contextHolder.remove();
}
}
6.动态数据源决策
/**
* @author:
* @description: 动态数据源实现
* @date: 2020/9/14 17:22
**/
@Slf4j
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
String datasource = DataSourceContextHolder.getDbType();
log.debug("当前使用数据源:{}", datasource);
return datasource;
}
}
- Mybatis Plus 的配置类 MybatisPlusConfig
mapper 的目录结构修改如下:
如果使用了 xml 文件进行多表查询,则还需要修改对应的 xml 文件中的路径 namespace:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 此处与接口类地址对应 -->
<mapper namespace="com.system.domain.mapper.db1.DataMapper">
<select id="pageDatas" resultType="map">
...
<!-- 对应的pageDatas查询sql -->
</select>
</mapper>
mapper 所在目录为 com.system.domain.mapper,因此 @MapperScan 需要扫描的路径为mapper下的 db1 和 db2,配置如下:
com.system.domain.mapper.db*
MybatisPlusConfig 配置类
/**
* @author
* @description mybatis plus配置
*/
@EnableTransactionManagement //开启事务
@Configuration
@MapperScan("com.system.domain.mapper.db*")
public class MybatisPlusConfig {
/**
* 分页插件
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
@Bean(name = "db1")
@ConfigurationProperties(prefix = "spring.datasource.druid.db1")
public DataSource db1() {
return DruidDataSourceBuilder.create().build();
}
@Bean(name = "db2")
@ConfigurationProperties(prefix = "spring.datasource.druid.db2")
public DataSource db2() {
return DruidDataSourceBuilder.create().build();
}
/**
* 动态数据源配置
*
* @return
*/
@Bean(name = "multipleDataSource")
@Primary
public DataSource multipleDataSource(@Qualifier("db1") DataSource db1,
@Qualifier("db2") DataSource db2) {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DBTypeEnum.DB1.getValue(), db1);
targetDataSources.put(DBTypeEnum.DB2.getValue(), db2);
dynamicDataSource.setTargetDataSources(targetDataSources);
// 程序默认数据源,根据程序调用数据源频次,把常调用的数据源作为默认
dynamicDataSource.setDefaultTargetDataSource(db1);
return dynamicDataSource;
}
@Bean("sqlSessionFactory")
public SqlSessionFactory sqlSessionFactory() throws Exception {
MybatisSqlSessionFactoryBean sqlSessionFactory = new MybatisSqlSessionFactoryBean();
sqlSessionFactory.setDataSource(multipleDataSource(db1(), db2()));
// 设置默认需要扫描的 xml 文件
sqlSessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*.xml"));
//其他配置项
MybatisConfiguration configuration = new MybatisConfiguration();
configuration.setJdbcTypeForNull(JdbcType.NULL);
// 驼峰和下划线转换
configuration.setMapUnderscoreToCamelCase(true);
configuration.setCacheEnabled(false);
configuration.setCallSettersOnNulls(true);
sqlSessionFactory.setConfiguration(configuration);
sqlSessionFactory.setTypeAliasesPackage("com.intyt.jcyy.system.domain");
// 数据库查询结果驼峰式返回
sqlSessionFactory.setObjectWrapperFactory(new MybatisMapWrapperFactory());
// 添加分页功能
sqlSessionFactory.setPlugins(new Interceptor[]{
paginationInterceptor()
});
// 实现自动填充功能
sqlSessionFactory.setGlobalConfig(globalConfiguration());
return sqlSessionFactory.getObject();
}
@Bean(name = "multipleTransactionManager")
@Primary
public DataSourceTransactionManager multipleTransactionManager(@Qualifier("multipleDataSource") DataSource dataSource) {
// 动态事务配置
return new DataSourceTransactionManager(dataSource);
}
@Bean
public GlobalConfig globalConfiguration() {
// 自动填充创建时间和更新时间(MyMetaObjectHandler的实现参考 “MyBatis Plus 的自动填充功能” 博客)
GlobalConfig conf = new GlobalConfig();
conf.setMetaObjectHandler(new MyMetaObjectHandler());
return conf;
}
- 使用AOP实现数据源的动态设置
/**
* @author:
* @description: aop实现数据源切换
* @date: 2020/9/14 17:29
**/
@Component
@Order(value = -100)
@Slf4j
@Aspect
public class DataSourceAspect {
@Before("execution(* com.system.service.impl.*.*(..)) && @annotation(com.common.annotation.MyDataSource)")
public void before(JoinPoint joinPoint) {
// execution 中配置的是服务实现类 & MyDataSource的包路径
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
MyDataSource myDataSource = null;
// 判断方法上的注解
if (method.isAnnotationPresent(MyDataSource.class)) {
myDataSource = method.getAnnotation(MyDataSource.class);
DataSourceContextHolder.setDbType(myDataSource.value());
} else if (method.getDeclaringClass().isAnnotationPresent(MyDataSource.class)) {
//其次判断类上的注解
myDataSource = method.getDeclaringClass().getAnnotation(MyDataSource.class);
DataSourceContextHolder.setDbType(myDataSource.value());
}
if (myDataSource != null) {
log.info("注解方式选择数据源---" + myDataSource.value().getValue());
}
}
/**
* 服务类的方法结束后,会清除数据源,此时会变更为默认的数据源
**/
@After("execution(* com.system.service.impl.*.*(..)) && @annotation(com.common.annotation.MyDataSource)")
public void after(JoinPoint point){
// execution 中配置的是服务实现类 & MyDataSource的包路径
DataSourceContextHolder.clearDbType();
}
}
9.实际使用:在ServiceImpl 类中使用注解进行标识

即所有被标识了以下事务注解 @Transactional 和数据源注解 @MyDataSource 的service实现类都可以实现动态数据源和事务的切换:
@MyDataSource(DBTypeEnum.DB1)
@Transactional
如果在按照以上步骤配置后,发现数据源切换不生效,可检查是否是 @Transactional 注解失效,
可参考:Spring的声明式事务@Transactional注解的6种失效场景