一,问题描述:
在导入数据时,出现了非默认数据库无法导入数据到不存在但需要新建的数据表。
BUG 复现操作过程:
- 右键选中新建的数据库中某 schema。
- 在出现的菜单中左键点击 Import Data。
- 在 information 选项的文件项中上传数据文件;在表项中输入不存在的表名(右下角有提示);数据追加默认选中。
- 点击 列 选项的表头项,映射数据列。
- 点击对话框右下角“确定”(本会创建不存在的数据表并导入数据,并提示任务完成)。
- 报错:ERROR: relation “schemaname.tablename” does not exist
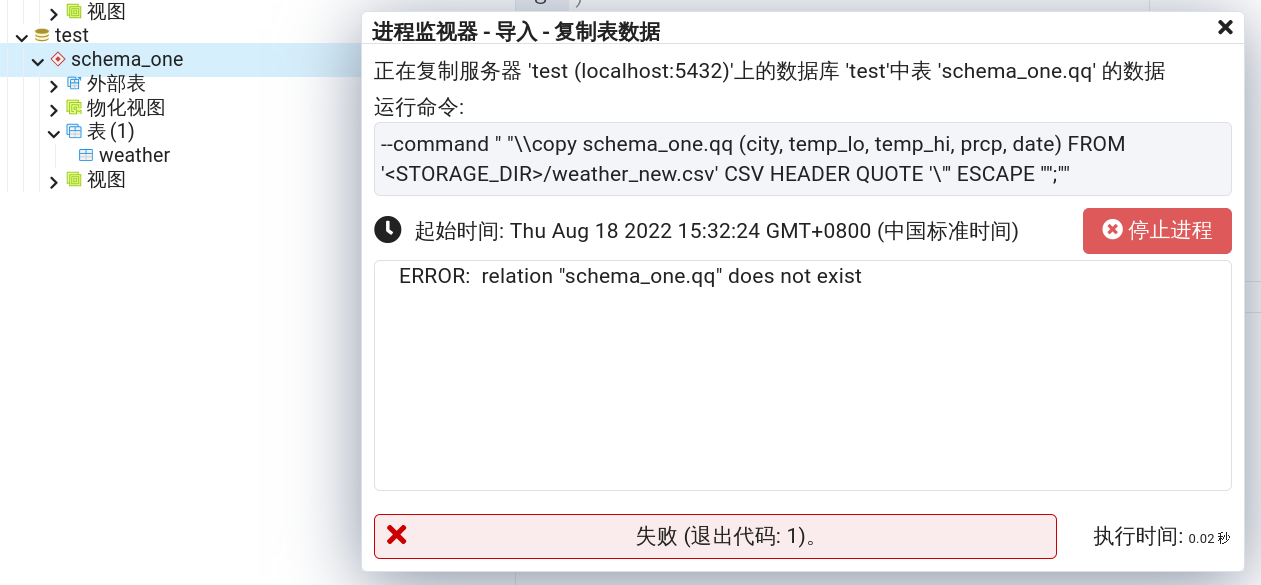
但是本 BUG 在默认的 postgres 数据库中不会出现!
二,DEBUG 过程:
1,代码回顾
前端代码:
文件 web/pgadmin/tools/import_database/static/js/import_database.js
define([
...
], function(
gettext, url_for, pgAdmin, pgBrowser, supportedNodes) {
...
pgTools.import_database = {
...
/*
Open the dialog for the import functionality
*/
callback_import: function(args, item) {
...
var t = pgBrowser.tree;
i = item || t.selected();
...
const baseUrlUtilitCheck = url_for('import_database.utility_exists', {
'sid': server_data._id,
});
// Check psql utility exists or not.
let that = this;
api({
url: baseUrlUtilitCheck,
type:'GET',
})
.then(function(res) {
if (!res.data.success) {
...
}else{
...
let urlShortcut = 'import_database.create_job',
baseUrl = url_for(urlShortcut, {
'sid': treeInfo.server._id,
});
extraData = that.setExtraParameters(treeInfo);
...
getUtilityView(schema, treeInfo, 'select', 'dialog', j[0], panel, that.importDatabaseCallBack, extraData, 'OK', baseUrl, sqlHelpUrl, helpUrl, true, that.onDataChange, that.getColumns);
}
})
.catch(function() {
...
});
},
};
return pgAdmin.Tools.import_database;
});
后端代码:
@blueprint.route('/job/<int:sid>', methods=['POST'], endpoint="create_job")
@login_required
def create_import_job(sid):
""" Creates a new job for import table data functionality
:param sid: Server ID
:return: status and(or) job id
"""
if request.form:
data = json.loads(request.form['data'], encoding='utf-8')
else:
data = json.loads(request.data, encoding='utf-8')
# Fetch the server details like hostname, port, roles etc
server = Server.query.filter_by(
id=sid
).first()
if server is None:
return bad_request(errormsg=_("Could not find the given server"))
# To fetch MetaData for the server
from pgadmin.utils.driver import get_driver
driver = get_driver(PG_DEFAULT_DRIVER)
manager = driver.connection_manager(server.id)
conn = manager.connection()
connected = conn.connected()
if not connected:
return bad_request(errormsg=_("Please connect to the server first..."))
try:
# 检查是否存在同名表
...
# 如果存在同名表,且不追加数据,则先删除同名表
...
# 如果不存在同名表,或已经删除同名表,则根据选中的数据列创建数据表
...
except Exception as e:
return bad_request(
errormsg=_("Please enter necessary and correct information..."))
# Get the utility path from the connection manager
utility = manager.utility('sql')
ret_val = does_utility_exist(utility)
if ret_val:
return make_json_response(
success=0,
errormsg=ret_val
)
# Get the storage path from preference
storage_dir = get_storage_directory()
if 'filename' in data:
try:
_file = filename_with_file_manager_path(
data['filename'], data['is_import'])
except Exception as e:
return bad_request(errormsg=str(e))
if not _file:
return bad_request(errormsg=_('Please specify a valid file'))
elif IS_WIN:
_file = _file.replace('\\', '/')
data['filename'] = _file
else:
return bad_request(errormsg=_('Please specify a valid file'))
...
# 设置映射关系并修改列名
mapToCols = []
newCols = []
for c in data['columnSetting']:
newCols.append(c['column'])
mapToCols.append(c['map_to'])
df = df[mapToCols]
df.columns = newCols
if 'quote' in data.keys() and data['quote'] is not None:
df.to_csv(data['filename'], sep=delimiter, encoding=encoding,
escapechar=escapechar, quotechar=data['quote'],
na_rep=na_values, header=header, index=False)
else:
df.to_csv(data['filename'], sep=delimiter, encoding=encoding,
escapechar=escapechar,
na_rep=na_values, index=False)
# Create the COPY FROM/TO from template
query = render_template(
'import_database/sql/cmd.sql',
conn=conn,
data=data,
columns=cols,
ignore_column_list=icols
)
args = ['--command', query]
try:
# 开启数据导入进程
...
except Exception as e:
current_app.logger.exception(e)
return bad_request(errormsg=str(e))
# Return response
return make_json_response(
data={'job_id': jid, 'success': 1}
2,代码调试
前端部分断点:
========================================================================
var t = pgBrowser.tree;
i = item || t.selected();
------------------------------------------------------------------------
flattenedBranch: null
handleWatchEvent: async (event) => {…}
hardReloadPResolver: null
hardReloadPromise: null
isExpanded: true
resolvedPathCache: "/browser/server_group_1/server_1/database_16384/schema_25045"
watchTerminator: ƒ ()
_branchSize: 5
_children: Array(4)
0: Directory {_uid: 16, _root: Root, _parent: Directory, _superv: {…}, _disposed: false, …}
1: Directory {_uid: 19, _root: Root, _parent: Directory, _superv: {…}, _disposed: false, …}
2: Directory
flattenedBranch: null
handleWatchEvent: async (event) => {…}
hardReloadPResolver: null
hardReloadPromise: null
isExpanded: true
resolvedPathCache: "/browser/server_group_1/server_1/database_16384/schema_25045/coll-table_25045"
watchTerminator: ƒ ()
_branchSize: 1
_children: Array(1)
0: FileEntry
resolvedPathCache: "/browser/server_group_1/server_1/database_16384/schema_25045/coll-table_25045/table_25046"
_depth: 6
_disposed: false
_fileName: "weather"
_loaded: true
_metadata: {parent: '/browser/server_group_1/server_1/database_16384/schema_25045/coll-table_25045', children: Array(0), data: {…}}
_parent: Directory {_uid: 17, _root: Root, _parent: Directory, _superv: {…}, _disposed: false, …}
_root: Root {_uid: 0, _root: Root, _parent: null, _superv: {…}, _disposed: false, …}
_superv: {notifyWillProcessWatchEvent: ƒ, notifyDidProcessWatchEvent: ƒ, notifyDidChangeMetadata: ƒ, notifyDidChangePath: ƒ, notifyWillChangeParent: ƒ, …}
_uid: 23
depth: (...)
disposed: (...)
fileName: (...)
id: (...)
parent: (...)
path: (...)
root: (...)
type: (...)
[[Prototype]]: Object
length: 1
[[Prototype]]: Array(0)
_depth: 5
_disposed: false
_fileName: "表"
_loaded: true
_metadata: {parent: '/browser/server_group_1/server_1/database_16384/schema_25045', children: Array(0), data: {…}}
_parent: Directory {_uid: 7, _root: Root, _parent: Directory, _superv: {…}, _disposed: false, …}
_root: Root {_uid: 0, _root: Root, _parent: null, _superv: {…}, _disposed: false, …}
_superv: {notifyWillProcessWatchEvent: ƒ, notifyDidProcessWatchEvent: ƒ, notifyDidChangeMetadata: ƒ, notifyDidChangePath: ƒ, notifyWillChangeParent: ƒ, …}
_uid: 17
branchSize: (...)
children: (...)
depth: (...)
disposed: (...)
expanded: (...)
fileName: (...)
id: (...)
parent: (...)
path: (...)
root: (...)
type: (...)
[[Prototype]]: FileEntry
3: Directory {_uid: 18, _root: Root, _parent: Directory, _superv: {…}, _disposed: false, …}
length: 4
[[Prototype]]: Array(0)
_depth: 4
_disposed: false
_fileName: "schema_one"
_loaded: true
_metadata: {parent: '/browser/server_group_1/server_1/database_16384', children: Array(0), data: {…}}
_parent: Directory {_uid: 4, _root: Root, _parent: Directory, _superv: {…}, _disposed: false, …}
_root: Root {_uid: 0, _root: Root, _parent: null, _superv: {…}, _disposed: false, …}
_superv: {notifyWillProcessWatchEvent: ƒ, notifyDidProcessWatchEvent: ƒ, notifyDidChangeMetadata: ƒ, notifyDidChangePath: ƒ, notifyWillChangeParent: ƒ, …}
_uid: 7
后端部分断点:
=================================================================================
data = json.loads(request.form['data'], encoding='utf-8') # 获取请求数据
------------------------------------------------------------
{
"is_import": true, # 处于数据导入模式
"icolumns": [],
"header": true,
"quote": "\"",
"escape": "\u0027",
"format": "json",
"table": "qq", # 新数据表名
"append": true, # 追加数据
"columnSetting": [ # 数据文件内容
{
"column": "city",
"type": "text",
"not_null": "no",
"map_to": "city"
},
{
"column": "temp_lo",
"type": "int",
"not_null": "no",
"map_to": "temp_lo"
},
{
"column": "temp_hi",
"type": "int",
"not_null": "no",
"map_to": "temp_hi"
},
{
"column": "prcp",
"type": "real",
"not_null": "no",
"map_to": "prcp"
},
{
"column": "date",
"type": "text",
"not_null": "no",
"map_to": "date"
}
],
"filename": "weather.json", # 数据文件名
"database": "test", # 数据库名
"schema": "schema_one", # 模式名
"save_btn_icon": "done"
}
上传的关键参数:
===================================================================================
server = Server.query.filter_by(id=sid).first() # 获取请求数据
------------------------------------------------------------
host: "localhost"
port: 5432
id: 1
name: "test"
========================================================================================
conn = manager.connection() # 默认建立的连接
-------------------------------------------------------------------------------
conn_id: 'DB:postgres'
db: 'postgres'
========================================================================================
# 检查是否存在同名表
status, res = conn.execute_scalar( # 如果表存在,则 res=1
"select 1 from pg_tables where schemaname = '" + str(
data['schema']) + "' AND tablename = '" + str(
data['table']) + "'")
-------------------------------------------------------------------------------
ststus: true
res: none
========================================================================================
# 如果已经删除同名表,则根据选中的数据列创建数据表
if (res == 1 and data['append'] is False) or res != 0:
sql_columns = ''
for col in data['columnSetting']:
sql_columns += str(col['column']) + ' ' + str(col['type']) + ','
sql = 'create table "' + str(data['schema']) + '".' + str(
data['table']) + ' (' + sql_columns[:-1] + ')'
conn.execute_void(sql) # 在这里报错
-------------------------------------------------------------------------------
sql_columns: 'city text,temp_lo int,temp_hi int,prcp real,date text,'
# 正常运行时会报错,具体报错如下:
2022-08-18 16:27:58,463: SQL pgadmin: Execute (void) by a@163.com on postgres@localhost/postgres #1 - DB:postgres (Query-id: 3672782):
create table "schema_one".qq (city text,temp_lo int,temp_hi int,prcp real,date text)
2022-08-18 16:27:58,468: ERROR pgadmin: Failed to execute query (execute_void) for the server #1 - DB:postgres(Query-id: 3672782):
Error Message:ERROR: schema "schema_one" does not exist
LINE 1: create table "schema_one".qq (city text,temp_lo int,temp_hi ...
^
从后端的调试结果可以看出:
- 前端传入的参数 data 是对的:数据库是目标数据库,schema 也是目标 schema,数据表也是目标数据表。
- 后端建立的数据库连接 conn 有误:数据库是目标数据库而是默认选中的 postgres 数据库。
正是后端数据库连接中的数据库选择错误,使得无法在建表时选择正确的 schema,导致报错 schema "schema_one" does not exist。
三,解决问题
1,解决方法
既然是数据库连接中的数据库选择错误,那么就需要在建立连接的同时指定要使用的目标数据库。
通过查看web/pgadmin/browser/server_groups/servers/databases/schemas/__init__.py 中 SchemaModule(CollectionNodeModule).get_nodes() 等数据库下级对象的操作源码可知,首先要在建立数据库连接时传入目标数据库 ID ,才能切换数据库,进而才能实现对数据库本身及其下级对象的操作:
manager = get_driver(PG_DEFAULT_DRIVER).connection_manager(sid)
curr_conn = manager.connection(did=did) # 在建立数据库连接时传入目标数据库 ID
# 获取具体的数据库信息
database = Database.query.filter_by(id=did, server=sid).first()
2,总结
首先要在建立数据库连接时传入目标数据库 ID ,才能切换数据库,进而才能实现对数据库本身及其下级对象的操作。
版权声明:本文为dangfulin原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。