目录
Spark SQL API
项目中需要导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
读取json数据,并使用SQL & DSL风格输出数据
package com.xcu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @Desc : 读取json数据,并使用SQL & DSL风格输出数据
*/
object SparkSQL01_Create {
def main(args: Array[String]): Unit = {
// 创建配置文件
val conf: SparkConf = new SparkConf().setAppName("").setMaster("local[*]")
// 创建SparkSQL执行的入口
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 读取json文件创建DataFrame
val df: DataFrame = spark.read.json("D:\\input\\test.json")
// 创建临时视图
df.createOrReplaceTempView("user")
// 输出数据
// DSL风格
df.select("name", "age").show()
// SQL风格
spark.sql("select * from user").show()
// 释放资源
spark.stop()
}
}
输出数据:
±-------±–+
| name|age|
±-------±–+
|zhangsan| 18|
| lisi| 20|
| ww| 19|
±-------±–+
±–±-------+
|age| name|
±–±-------+
| 18|zhangsan|
| 20| lisi|
| 19| ww|
±–±-------+
RDD DF DS 三者之间的转换
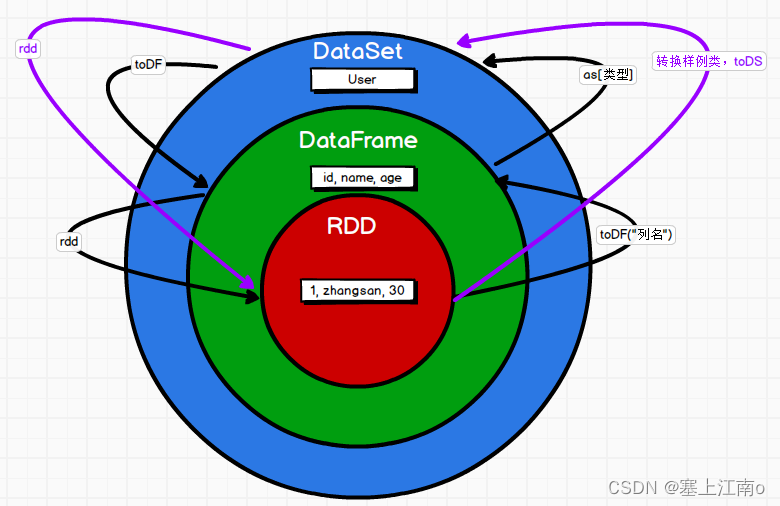
package com.xcu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* @Desc : RDD DF DS 三者之间的转换
*/
object SparkSQL02_Convert {
def main(args: Array[String]): Unit = {
import org.apache.spark
// 创建配置文件
val conf: SparkConf = new SparkConf().setAppName("SparkSQL02_Convert").setMaster("local[*]")
// 创建SparkSQL执行的入口,SparkSession
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// RDD--->DataFrame--->DataSet 之间的转换需要引入隐式转换规则,否则无法转换
// spark不是包名,是上下文环境对象名(变量名)
import spark.implicits._
// 创建RDD
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List((1, "x", 20), (2, "y", 10), (3, "z", 30)))
// RDD--->DF
val df1: DataFrame = rdd.toDF("id", "name", "age")
// DF--->DS
val ds: Dataset[User] = df1.as[User]
// DS--->DF
val df2: DataFrame = ds.toDF()
// DF--->RDD
val rdd1: RDD[Row] = df2.rdd // 返回RDD的类型为ROW,里面提供的getxxx方法可以获取字段值,类似jdbc处理结果集,索引从0开始
// 获取name
rdd1.foreach(a => print(a.getString(1))) // 输出 xyz
// RDD--->DS
rdd.map {
case (id, name, age) => User(id, name, age)
}.toDS()
// DS--->RDD
ds.rdd
// 释放资源
spark.stop()
}
}
case class User(id: Int, name: String, age: Int)
用户自定义函数
UDF
功能:输入一行,返回一个结果
需求:现有一张表如下,现需要对每个人进行打招呼。eg:hello: zhangsan
±–±-------+
|age| name|
±–±-------+
| 18|zhangsan|
| 20| lisi|
| 19| ww|
±–±-------+
package com.xcu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSQL03_UDF {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("").setMaster("local[*]")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 读取数据
val df: DataFrame = spark.read.json("D:\\input\\test.json")
// 注册自定义函数
spark.udf.register("SayHello", (name: String) => {
"hello:" + name
})
// 创建临时视图
df.createOrReplaceTempView("user")
// 输出数据
spark.sql("select SayHello(name) as newname from user").show()
// 释放资源
spark.stop()
}
}
输出:
±-------------+
| newname|
±-------------+
|hello:zhangsan|
| hello:lisi|
| hello:ww|
±-------------+
UDAF
功能:输入多行,返回一行。
强类型的Dataset和弱类型的DataFrame都提供了相关的聚合函数,eg: count(),avg(),max(),min()等,除此之外,用户可以设定自己的自定义聚合函数,通过继承UserDefinedAggregateFunction来实现自定义聚合函数
需求:有3个用户x,y,z ,年龄分别为20,40,30,现需要求他们的平均年龄
用普通算子求平均数
package com.xcu.bigdata.spark.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkSQL04_RDD_Avg {
def main(args: Array[String]): Unit = {
// 创建配置文件对象
val conf: SparkConf = new SparkConf().setAppName("SparkSQL04_RDD_Avg").setMaster("local[*]")
val sc = new SparkContext(conf)
// 创建RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("x", 20), ("y", 40), ("z", 30)))
// 结构转换
val mapRDD: RDD[(Int, Int)] = rdd.map {
case (name, age) => {
(age, 1)
}
}
// 聚合
val res: (Int, Int) = mapRDD.reduce {
(t1: (Int, Int), t2: (Int, Int)) => { // reduce(f:(T, T)=>T
(t1._1 + t2._1, t1._2 + t2._2)
}
}
// 求平均值
println(res._1 / res._2)
// 释放资源
sc.stop()
}
}
利用累加器求平均数
(减少Shuffle)提高效率
package com.xcu.bigdata.spark.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
object SparkSQL05_Accumulator {
def main(args: Array[String]): Unit = {
// 创建配置文件对象
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL05_Accumulator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("x", 20), ("y", 30), ("z", 40)))
// 创建累加器对象
val myAcc = new MyAccumulator
}
}
// AccumulatorV2[IN, OUT] AccumulatorV2[输入数据类型,输出数据类型]
class MyAccumulator extends AccumulatorV2[Int, Double] {
var ageSum: Int = 0
var countSum: Int = 0
// 初始化
override def isZero: Boolean = {
ageSum == 0 && countSum == 0
}
override def copy(): AccumulatorV2[Int, Double] = {
val newMyAcc = new MyAccumulator
newMyAcc.ageSum = this.ageSum
newMyAcc.countSum = this.countSum
newMyAcc
}
// 重置
override def reset(): Unit = {
ageSum = 0
countSum = 0
}
//分区内累加
override def add(v: Int): Unit = {
ageSum += v
countSum += 1
}
// 分区间合并
override def merge(other: AccumulatorV2[Int, Double]): Unit = {
other match {
case mc: MyAccumulator => {
this.ageSum += mc.ageSum
this.countSum += mc.countSum
}
case _ =>
}
}
// 结果
override def value: Double = {
ageSum / countSum
}
}
自定义UDAF求平均数(弱类型)
user.json
{“name”:“x”,“age”:20}
{“name”:“y”,“age”:30}
{“name”:“z”,“age”:40}
package com.xcu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, LongType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* @Desc : 自定义UDAF求平均数
*/
object SparkSQL06_UDAF {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL06_UDAF")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// 读取数据
val df: DataFrame = spark.read.json("input/user.json")
// 创建自定义函数对象
val myAvg = new MyAvg
// 注册自定义函数
spark.udf.register("myAvg", myAvg)
// 创建临时视图
df.createOrReplaceTempView("user")
// 输出结果
spark.sql("select myAvg(age) from user").show()
// 释放资源
spark.stop()
}
}
// 自定义UDAF函数(弱类型)
class MyAvg extends UserDefinedAggregateFunction {
// 聚合函数输入数据类型
override def inputSchema: StructType = {
StructType(Array(StructField("age", IntegerType)))
}
// 缓存数据的类型
override def bufferSchema: StructType = {
StructType(Array(StructField("sum", LongType), StructField("count", LongType)))
}
// 聚合函数返回的数据类型
override def dataType: DataType = DoubleType
// 稳定性,Boolean =ture 表示相同的输入是否会得到相同的输出
override def deterministic: Boolean = true
// 初始化,缓存设置到最初始状态
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 让缓存中年龄总和归0
buffer(0) = 0L
// 让缓存中总人数归0
buffer(1) = 0L
}
// 更新缓存数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!buffer.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getInt(0)
buffer(1) = buffer.getLong(1) + 1L
}
}
// 分区间的合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 计算逻辑
override def evaluate(buffer: Row): Any = {
buffer.getLong(0).toDouble / buffer.getLong(1)
}
}
自定义UDAF求平均数(强类型)
自定义聚合函数实现-强类型(应用于DataSet的DSL更方便)
package com.xcu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.Aggregator
/**
* @Package : com.xcu.bigdata.spark.sql
* @Author :
* @Date : 2020 11月 星期日
* @Desc : 自定义UDAF求平均数
*/
object SparkSQL07_UDAF_Strong {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL07_UDAF_Strong")
//创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val df: DataFrame = spark.read.json("input/test.json")
//将df转换为ds
val ds: Dataset[User06] = df.as[User06]
//创建自定义函数对象
val myAvgNew = new myAvgNew
//将自定义函数对象转换为查询列
val column: TypedColumn[User06, Double] = myAvgNew.toColumn
ds.select(column).show()
//释放资源
spark.stop()
}
}
//输入类型的样例类
case class User06(name: String, age: Long)
//缓存类型
case class AgeBuffer(var sum: Long, var count: Long)
//自定义UDAF函数(强类型) Aggregator[-IN, BUF, OUT]()
class myAvgNew extends Aggregator[User06, AgeBuffer, Double] {
//对缓存数据进行初始化
override def zero: AgeBuffer = {
AgeBuffer(0L, 0L)
}
//对当前分区内数据进行聚合
override def reduce(b: AgeBuffer, a: User06): AgeBuffer = {
b.sum += a.age
b.count += 1
b
}
//分区间合并
override def merge(b1: AgeBuffer, b2: AgeBuffer): AgeBuffer = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
//返回计算结果
override def finish(reduction: AgeBuffer): Double = {
reduction.sum.toDouble / reduction.count
}
//DataSet的编码以及解码器 用于进行序列化
//用户自定义Ref类型
override def bufferEncoder: Encoder[AgeBuffer] = {
Encoders.product //product系统值类型,根据具体类型进行选择
}
override def outputEncoder: Encoder[Double] = {
Encoders.scalaDouble
}
}
版权声明:本文为qq_43192537原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。