想要每天获取网站表格的数据又懒得每天复制做表统计
使用pandas 的 read_html(),简单好用。
可以应用的场景为数据为表格,打开网站,使用开发者工具,点开element,然后搜索表格里的一个名词,就可找到表格数据所在位置。会有一个明显的table,数据格式非常整齐。

记录一下read_html()的参数,
1.io,io=url就可以了
2.header,header可以是int,也可以是list,header默认是等于None的,读取出来的table的columns name就是0,1,2,3这样的。
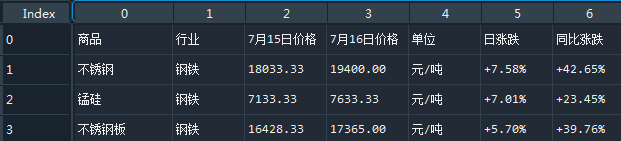
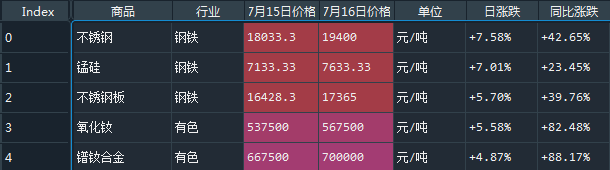
想使用第一行作为columns name,header=0,
df = pd.read_html(io=url,header=0)效果:
reference:https://www.cnblogs.com/litufu/articles/8721207.html
版权声明:本文为weixin_39405468原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。