一:介绍
该案例来自《利用Python进行数据分析·第2版》,主要对三个电影数据集文本进行分析。
二:分析流程
1:读取数据
import pandas as pd
unames = ['user_id', 'gender', 'age', 'occupation', 'zip']
users = pd.read_table('C:/Users/17322/Desktop/datasets/movielens/users.dat', sep='::', header=None, names=unames)
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('C:/Users/17322/Desktop/datasets/movielens/ratings.dat', sep = '::', header=None, names=rnames)
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table('C:/Users/17322/Desktop/datasets/movielens/movies.dat',sep='::',header=None, names=mnames)
查看是否正确读入:
users[:5]

ratings[:5]

movies[:5]

2:将三张表联合
data = pd.merge(pd.merge(ratings,users),movies)
data.iloc[0:10]

分析
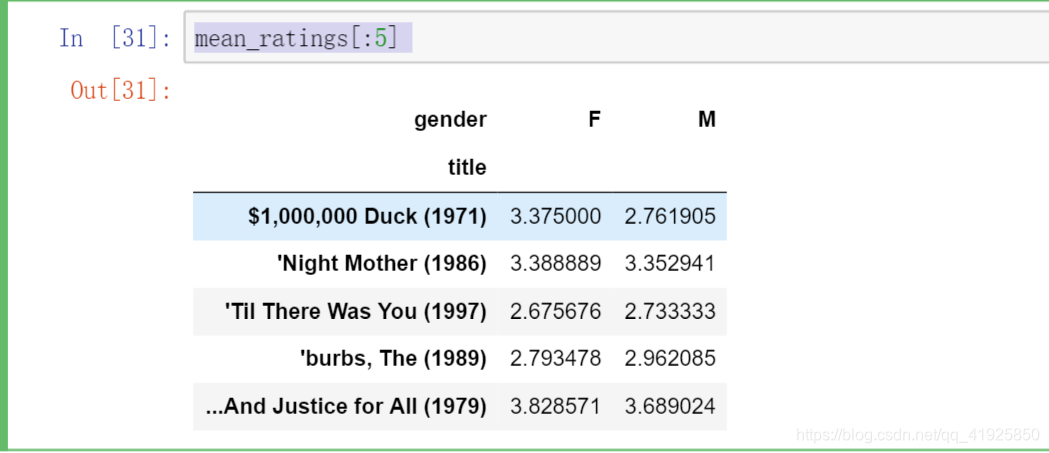
3:利用pivot_table()求男/女群体给每部电影所打的平均分;
此处透视表为难点:此处学pivot_table()详解
mean_ratings = data.pivot_table('rating',index = 'title',columns='gender',aggfunc='mean')
mean_ratings[:5]
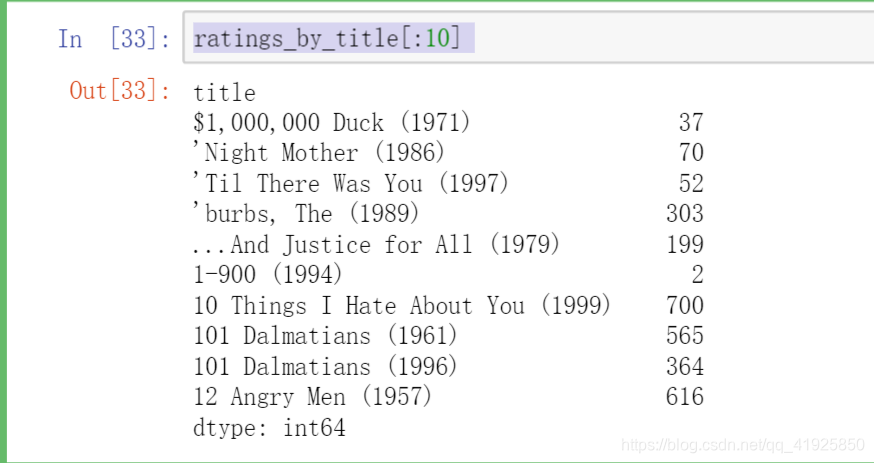
4:过滤评分人数少于400的电影
ratings_by_title = data.groupby('title').size()
ratings_by_title[:10]
得到大于400人评分的电影的索引列表
sig_titles = ratings_by_title.index[ratings_by_title >=400]
并可以根据索引列表选取前面均分表的对应的行
mean_ratings = mean_ratings.loc[sig_titles]
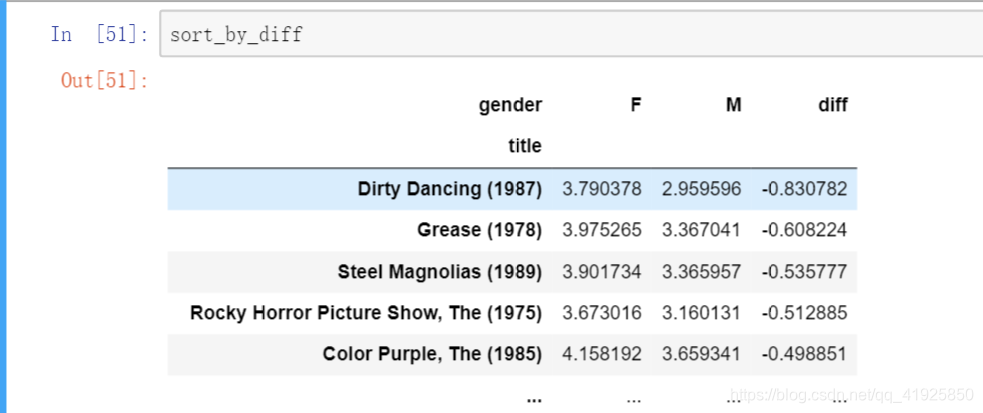
4:找出男性和女性观众分歧最大的电影
创建男女评分的分差列,并按之排序,得出女性更喜欢且男女差异大的电影
mean_ratings['diff'] = mean_ratings['M'] - mean_ratings['F']
sort_by_diff = mean_ratings.sort_values(by='diff')
反序则是男士更喜欢的电影
若要得出所有人中分歧最大的电影,则对每部电影评分求方差
rating_std_by_title = data.groupby('title')['rating'].std()
过滤评分数<400的电影
rating_std_by_title = rating_std_by_title.loc[sig_titles]
统计并排序
rating_std_by_title.sort_values(ascending=False)[:10]

版权声明:本文为qq_41925850原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。