切分原则
垂直切分:按照表的分类来进行表的切分,那么水平切分是按照表中的行记录来进行的切分,将表中的行记录按照特定的规则,拆分到某些特定的数据库,实现同一个表的数据分散存储。如下示意图所示:
水平切分:按照表中的行记录来进行的切分,将表中的行记录按照特定的规则,拆分到某些特定的数据库,实现同一个表的数据分散存储。如下示意图所示: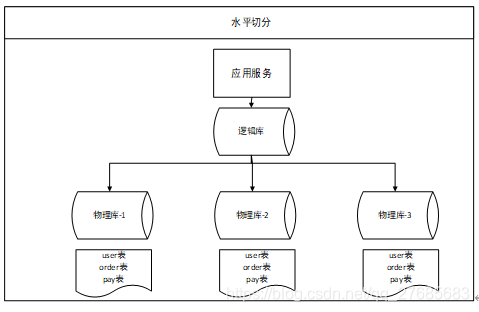
配置文件
- schema.xml:
schema标签
定义的是Mycat实例中的逻辑库,Mycat可以有多个逻辑库,每个逻辑库都有自己 的配置,shema可以区别不同的逻辑库。
checkSQLschema的作用:
当该值设置为 true 时,如果我们执行语句select * from TESTDB.travelrecord;MyCat会把语句修改为select * from travelrecord;即把表示schema的字符TESTDB去掉,避免发送到后端数据库执行时报(ERROR 1146 (42S02): Table ‘testdb.travelrecord’ doesn’t exist)。建议设置为true,避免加逻辑库的名字。
sqlMaxLimit的作用:
当该值设置为某个数值时。每条执行的SQL语句,如果没有加上limit语句,MyCat也会自动的加上所对应的值。例如设置值为100,执行select * from TESTDB.travelrecord;的效果为和执行select * from TESTDB.travelrecord limit 100;相同。不设置该值的话,MyCat默认会把查询到的信息全部都展示出来,造成过多的输出。
特别注意:这个属性要小心使用,在hap项目加载时,会读取数据库表中数至redis缓存,如果该值设置过小了,会导致redis的缓存值加载不完全的情况,所以要根据项目的实际调整该值的实际大小。
table标签
name的作用:
逻辑表的表名,这个表名是唯一的,在schema中不可重复定义。
dataNode的作用:
定义逻辑表所属的数据节点,该属性的值需要和dataNode标签中name属性的值相互对应。
rule的作用:
该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml中定义,必须与tableRule标签中name属性值一一对应。
primaryKey的作用:
逻辑表所对应的真实表的主键值。
autoIncrement的作用:
使用autoIncrement=”true” 指定这个表有使用自增长主键,这样mycat才会不抛出分片键找不到的异常。
使用autoIncrement=”false” 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。
dataNode标签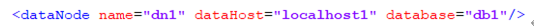
Name的作用:
定义数据节点的名字,这个名字是唯一的,在table标签上使用该名字。
dataHost的作用:
定义该分片属于那一个数据库实例,引用的是dataHost标签定义的名字。
database的作用:
定义该节点主机上具体的数据库实例名字,便于确定该分片表具体落在哪一个数据节点上。
dataHost标签
maxCon作用:
指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的writeHost、readHost标签都会使用这个属性的值来实例化出连接池的最大连接数。
minCon作用:
指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance作用:
负载均衡类型,目前的取值有3种:
- balance=“0”, 所有读操作都发送到当前可用的writeHost上。
- balance=“1”,所有读操作都随机的发送到readHost 与 stand by writeHost 参与 select 语句的负载均衡。 适用双主双从
- balance=“2”,所有读操作都随机的在writeHost、readhost上分发。
- balance=”3“,所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力 适用一主一从
writeType作用:
负载均衡类型,目前的取值有3种:
5. writeType=“0”, 所有写操作都发送到可用的writeHost上。
6. writeType=“1”,所有写操作都随机的发送到readHost。
7. writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。
dyType作用:
指定后端的数据库连接类型
dbDriver作用:
指定后端数据库采用的数据驱动类型
hearbeat的作用:
这个标签内指明用于和后端数据库进行心跳检查的语句。例如,MYSQL可以使用select user(),Oracle可以使用select 1 from dual等。
在readHost和writeHost中指定实际的数据库连接地址Url和用户名、密码等信息。
2.server.xml
server.xml标签保存的是mycat的系统配置信息,包括全局SQL防火墙设置、系统用户设置以及全局序列设置。
指定了mycat的root用户的密码为123456,其可操作的数据库为TESTDB。
Sql防火墙和黑名单设置:
在system标签中有个配置属性为sequnceHandlerType,该属性指定了全局序列的设置方式,配置为0代表使用本地文件方式;配置为1代表使用数据库的方式;配置为2 使用本地时间戳方式。
3.rule.xml
rule.xml里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同。这个文件里面主要有tableRule和function这两个标签。在具体使用过程中可以按照需求添加tableRule
和function。
TableRule表规则: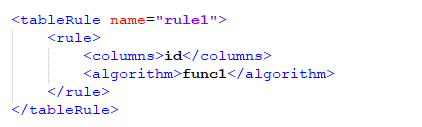
表的规则的名称为rule1,这个rule1就会在schema.xml文件中的rule属性中所使用。所采用的分片算法为fun1,fun1的定义如下所示:
分片原则
1. 分片枚举
申明规则:
accounting_date
hash-int
规则对应的算法:
partition-hash-int.txt
1
在partition-hash-int.txt中申明枚举映射关系:
2018-01-01=0
2018-02-01=1
2018-03-01=2
在这里意味着:
accounting_date的值为”2018-01-01”的记录会插入到第一个数据节点;accounting_date的值为”2018-02-01”的记录会插入到第二个数据节点;accounting_date的值为”2018-03-01”的记录会插入到第三个数据节点;(物理节点从0开始排序)
2. 固定分片hash算法
申明规则:
id
func1
规则对应的算法:
8
128
其中该算法,mycat要求partitionCount* partitionLength恒等于1024
固定分片hash算法即对分片列id取hash值,然后划分到具体的数据节点上。
3. 求模算法
申明规则:
id
mod-long
规则对应的算法:
3
该算法对分片列id进行取模运算,除数为设定的数据节点的数量,根据取余数的结果对数据记录进行拆分到不同的物理库中。
4. 自然月分片
申明规则:
ACCOUNTING_DATE
partbymonth
规则对应的算法:
yyyy-MM-dd
2018-01-01
dateFormat指定了日期的格式、sBeginDate指定了日期开始时间。该分片规则会按照月份列进行分区,每个月需要单独的一个数据库。
5. 如何客户化开发分片规则
在mycat源码(io.mycat.route.function)上去新建类继承AbstractPartitionAlgorithm该抽象类并实现RuleAlgorithm这个接口即可,重点实现其中的init方法和calculate方法。
/**
@author jiaqing.xu@hand-china.com
@version 1.0
@name
@description
@date 2018/7/2
*/
public class PartitionBySelf extends AbstractPartitionAlgorithm implements RuleAlgorithm {
private int count;
@Override
public void init() {
//初始化工作 变量赋值等操作
}public void setCount(int count) {
this.count = count;
}@Override
public Integer calculate(String columnValue) {
//根据逻辑计算需要返回的物理节点dataNode的索引值
return 0;
}@Override
public int getPartitionNum() {
int nPartition = this.count;
return nPartition;}}
在rule.xml文件中引用该制定的客户化分片规则,在class中指定全路径名。