- YOLOv2理论篇
- YOLOv2实践篇
背景介绍:
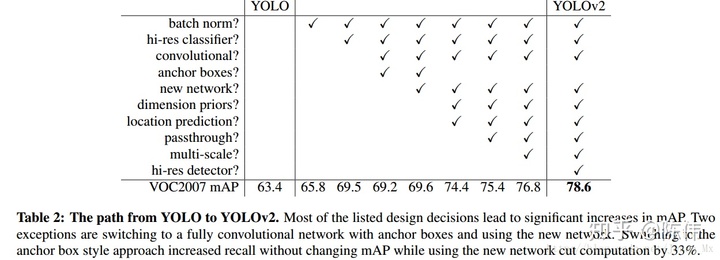
YOLOv1和同时期的SSD属于两个单阶段检测模型,以速度快著称。但是YOLOv1的诸多缺陷导致精准度较差、召回率低。估计YOLOv2参考了SSD或者Faster RCNN引入了anchor机制,同时加入Batch Normalization层,多尺度融合等手段提升了性能,改进方法如下:
网络模型:
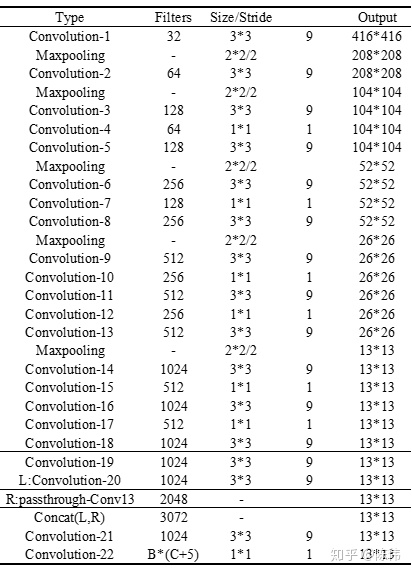
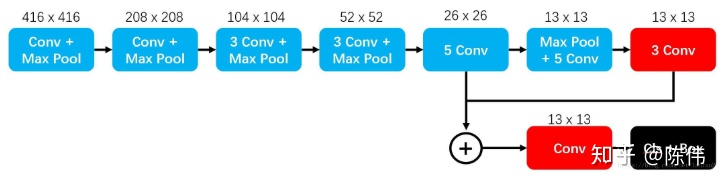
YOLOv2采用Darknet19进行特征提取,类似于VGG,使用了较多的3 * 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,网络使用了全局平均池化,把1 * 1的卷积核置于3 * 3的卷积核之间,用来压缩特征。也用了batch normalization稳定模型训练。如下图,其包含19个卷积层、5个最大值池化层、以及新增的passthrough层,融入更精细的特征图:
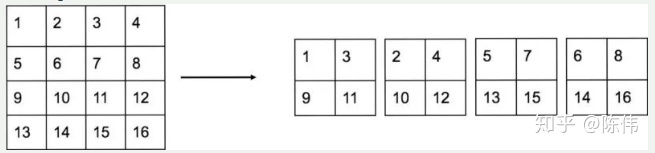
YOLOv2版本引入passthrough层类似于隔行隔列获取数据,将高低分辨率的特征图做连结,叠加相邻特征到不同通道:
网络中将26 * 26 * 512的特征图通过passthrough层采样到13*13*256与原本卷积得到的13*13*1024的特征图做concat,输出13 * 13 * (256+1024)的特征图,最后经过3*3卷积输出13 * 13 * 1024的特征图,如下图所示:
YOLOv2版本去掉了dropout层,使用Batch normalization。如果每批训练数据的分布各不相同,那么网络就要在每次迭代都去学习适应不同的分布,这样会大大降低网络的训练速度。而batch normalization的作用就是将每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,极大的改善收敛速度同时减少了对其它正则化方法的依赖。

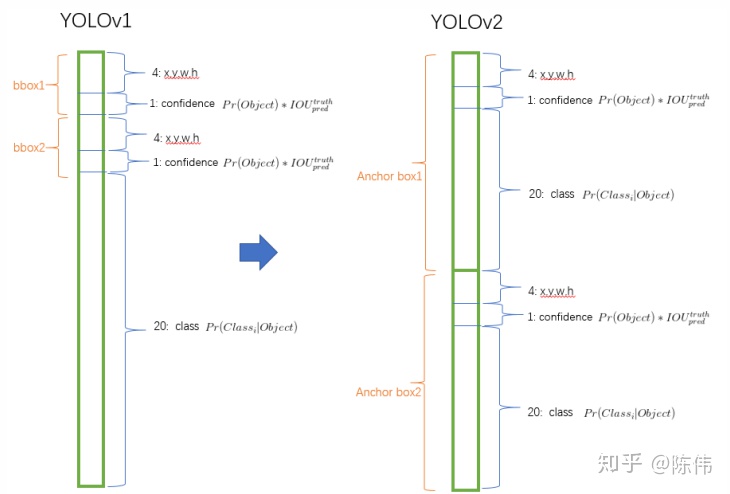
YOLOv2版本取消了全连接层,保留了空间信息并且极大降低了参数量(全连接层把1470*1的向量reshape为7*7*30的特征图,会丢失较多的空间信息导致定位不准)。引入anchor机制,为卷积特征图上进行滑窗采样,每个中心包含5种不同大小和比例的建议框,每个建议框预测4个位置属性和1个置信度。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个cell相对应;用预测相对偏移(offset)取代直接预测坐标。与v1的差别如下图所示:
网络中的anchors通过聚类的方式获取,如果采用传统的欧式距离聚类方式,我们发现相同偏差的情况下,大boxes比小boxes产生更多error,所以我们采用IOU作为聚类的度量标准:
损失函数:
先验框匹配策略:
- 对5个anchor进行IOU判断,大于设定值的称为匹配上;
- 计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与GT的中心点都偏移到同一位置(原点),然后计算出对应的IOU值;
- 在匹配上的先验框中选中IOU最大的一个负责该cell中物体的预测;
- 未匹配上的先验框中IOU小于设定阈值0.6的当作背景处理,对于IOU大于设定值,但是不是最大IOU的直接忽略不做任何处理;
损失计算方法:
YOLOv2版本在特征图(13 *13 )的每个cell上预测5个边界框,每一个边界框预测5个坐标值:tx,ty,tw,th,to。如果这个cell距离图像左上角的边距为(cx,cy)以及该cell对应的box维度的长和宽分别为(pw,ph),那么对应的box为:
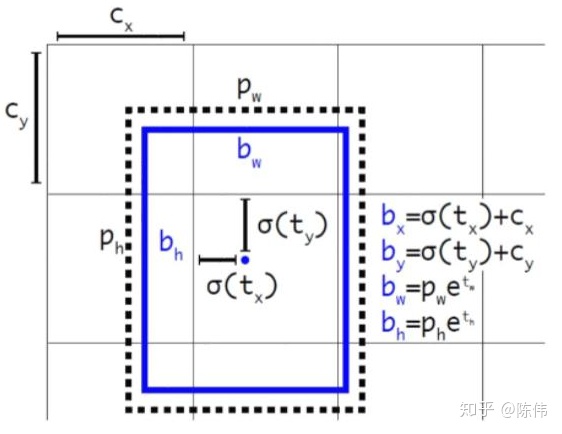
如上图所示对中心点x,y的回归加入sigmoid函数约束到每个网格(0,1)之间的偏移,使得预测框的中心坐标总位于格子内部;长宽w,h的表示成对数形式相对于anchor的偏移;从而减少模型的不稳定性。同时针对大目标和小目标对损失的贡献不同,采用面积差的方式,即box_scale = (2 - w * h),即对于尺度较小的预测框其权重系数会更大一些,起到和v1版本计算平方根相似的效果。
训练流程:
官方的训练对预训练分类模型采用了更高分辨率的图片,使用Darknet-19在标准1000类的ImageNet的224 * 224尺寸上训练了160次,用的随机梯度下降法,初始学习率为0.1,采用分段学习率衰减的方式,weight decay为0.0005 ,momentum 为0.9。在训练的过程中加入了random crops, rotations, and hue, saturation, and exposure shifts等数据增广。然后的10个epoch将ImageNet数据集的尺寸放大为448x448的输入来finetune分类网络这一中间过程,此时学习率调整成1e-3,这一方法使得模型在检测数据集上finetune之前已经适用高分辨率输入。
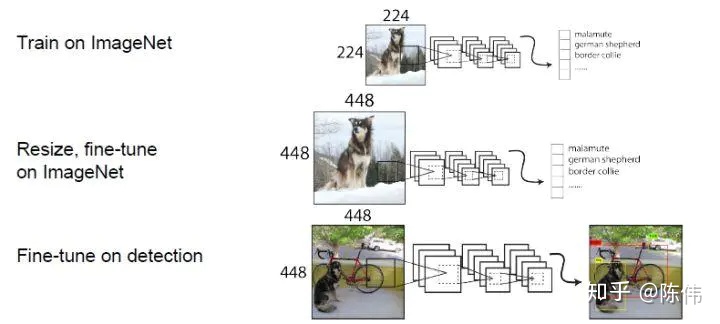
之后在检测网络训练阶段采用多种不同尺寸进行训练,增加模型的鲁棒性。在训练过程中每间隔一定的iterations之后改变模型的输入图片大小。由于YOLOv2的下采样总步长为32,输入图片大小选择一系列为32倍数的值:{320,352,384,...,608}。在训练过程,每隔10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。
模型缺点:
其一:YOLOv2的Darknet19还是基于VGG的串行堆叠模式,但是此类模型在反向传播存在梯度弥散、特征提取上存在信息确实等问题,新增的passthrough层虽然融合了两个尺度特征但是对上下文描述任不足。所以后续模型大多在特征提取阶段集成残差模块及注意力机制,在neck阶段采用FPN或者PAN等形式综合各个尺度的特征。
其二:YOLOv2的损失函数依然把中心点和长宽分开计算,但是位置信息应该作为整体看待,所以后续模型大多采用iou及其变体更替,类别和置信度损失也建议使用交叉熵损失而不是平方差损失。
相关问题:
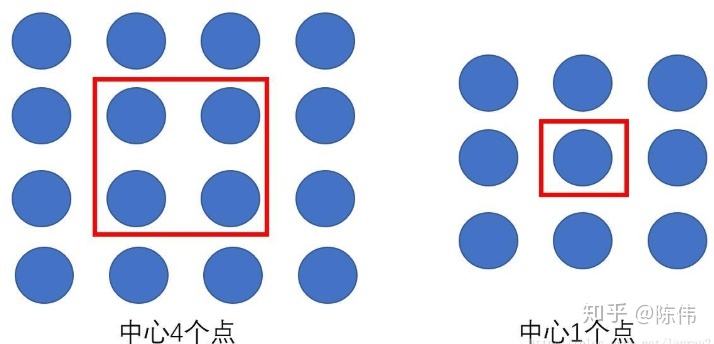
关于多尺度检测这块感觉存在一点点小问题,因为YOLOv2会进行5次下采样,所以如果训练图片是320*320,最后生成的特征图为10*10,这样一来图像中心点是4个点,就会导致在图像中心的物体的中心点落在4个Grid Cell中,不方便分配。