目录
1 Python基础
1.1 列表推导式
- append()函数:
- 作用:在列表结尾追加数据(追加的单个数据)
- 语法:
变量名.append(数据)
注意:不能一次追加多个数据,增加多个数据是将整个序列追加到序列。
- 列表推导式:也就是简化代码的。
- 形式:
列表名=[变量名 for 变量名 in range(start,end,step)],第一个变量名表示映射函数,它的输入值为后面一个变量名所指代的内容,第二个变量名表示迭代对象。
【例子】遍历0到10之间的偶数
# 方法1:带步长 a=[i for i in range(0,11,2)] # 方法2 :带if条件语句 b=[i for i in range(0,11) if i%2==0]- 多层嵌套:第一个for语句是外层循环,第二个for语句是内层循环。
【例子】多层嵌套
c=[i+'$'+j for i in ['A','B'] for j in ['a','b']] # ['A&a', 'A&b', 'B&a', 'B&b'] - 形式:
- 语法糖:Syntactic sugar,也称糖衣语法,指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员理解使用。
- 条件赋值语法糖:也是条件语句的三目运算, 形式为:
【例子】截断列表中超过 7的元素条件成立执行的表达式 if 条件 else 条件不成立执行的表达式L=[0,12,3,14,5,6,7] d=[i if i<=7 else 7 for i in L] # [0, 7, 3, 7, 5, 6, 7]
1.2 匿名函数与map方法
- lambda表达式:
- 匿名函数:不关心函数名字,只关心映射关系。Python使用lambda来创建匿名函数。
- 使用情景:当函数只有一个返回值,且只有一句代码时,可以用lambda简写。
- 语法:
Lambda 形参:表达式 - 注意:
1.形参可以省略;
2.lambda可以接收任何数量的参数,但是返回值只有一个。
【例子】
# 没有参数 a=lambda :100 print(a()) # 这里要注意a是函数,要带() #匿名函数 (lambda :100)() #100 # 两个参数,有实参 (lambda a,b:a+b)(7,13) # 20 # 带条件语句 (lambda a,b:a if a>b else b)(1,2) # 2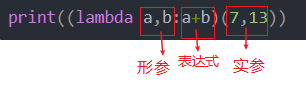
- map函数:
- 作用:将可迭代对象的每一个元素作为函数的参数进行运算加工,直到可迭代序列的每个运算都加工完毕。
- 语法:
map(函数名,迭代对象)
【例子】输出偶数列表
【例子】多个输入值的函数映射# 匿名函数 [(lambda i:i*2)(x)for x in range(5)] # map函数 list(map(lambda i:i*2,range(5)))list(map(lambda x,y:str(x)+'_'+y,range(5),list('abcde'))) # ['0_a', '1_b', '2_c', '3_d', '4_e']
1.3 zip对象与enumerate方法
- zip函数:
- 作用:用于将可迭代的对象中对应的元素打包成一个个元组,然后返回一个zip对象。通过 tuple, list可以得到相应的打包结果。
- 注意:如果迭代对象的元素个数不一致,则返回列表长度与最短的相同。
【例子】打包列表
【例子】循环迭代a=[1,2,3] b=[1,2,3,4,5] zipped=list(zip(a,b)) print(zipped) # [(1, 1), (2, 2), (3, 3)]
【例子】列表建立字典映射for i,j in zip(a,b): print(i,j) """ 1 1 2 2 3 3 """dict(zip(a,b)) {1: 1, 2: 2, 3: 3} - enumerate函数:
- 作用:enumerate()用于将一个可遍历的数据对象(列表,元组或字符串等)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环中 。
- 语法:
enumerate(可遍历的对象,start=0) - 注意: start参数用来设置遍历数据的下标的起始值,默认为0。不是从下标为几开始遍历,只是改变了下标的起始值。
【例子】打包遍历序号和数据
''' 1.形式1 for 变量名 in enumerate(列表名): print(变量名) ''' # 示例 x=['a','b','c','d'] for i in enumerate(x,1): print(i) """ 结果: (1, 'a') (2, 'b') (3, 'c') (4, 'd') """ ''' 2.形式2 for 下标,数据 in enumerate(列表名): print(下标,数据) ''' # 示例 for index,value in enumerate(x): print(index,value) for index,value in zip(range(len(x)),x): print(index,value) """ 结果: 0 a 1 b 2 c 3 d """ - 解压:
*和zip函数联合来进行解压操作- 语法:
zip(*解压对象)
【例子】解压
a=list('abcd') b=list('efghj') zipped=list(zip(a,b)) print(zipped) print(list(zip(*zipped))) ''' [('a', 'e'), ('b', 'f'), ('c', 'g'), ('d', 'h')] [('a', 'b', 'c', 'd'), ('e', 'f', 'g', 'h')] ''' - 语法:
2 Numpy基础
2.1 数组的构造
- 数组的构建方法:通过
np.array或者np.arange。import numpy as np # 方法1 通过array a=np.array([1,2,3,4]) #[1 2 3 4] # 方法2 通过arange b=np.arange(1,5) #[1 2 3 4]- array:将输入的数据(列表、元组、数组及其他序列)转换为ndarray(Numpy数组)。
- array的属性:
shape:表示数组的维度[形状,几行几列] - arange:Python内建函数range的数组版,返回一个数组。
- 等差序列:通过
np.linspace,np.arange- np.linspace:创建等差数列的函数,
np.linspace(开始值,结束值,x)x是样本个数,结果数组默认包括终值。
【例子】
np.linspace(1,10,5)#起始、终止(包含),样本个数 #[ 1. 3.25 5.5 7.75 10. ] np.arange(1,10,5)#起始、终止(不含),步长 #[1 6] - np.linspace:创建等差数列的函数,
- 特殊矩阵:
- 全0矩阵:
np.zeros(shape) - 单位矩阵:
np.eye(shape,k)k设置相对主对角线的偏移单位,正值往右偏移。 - 创建指定值的数组:
np.full(shape,fill_value)fill_value是指定值。
【例子】
np.zeros((2,4)) ''' [[0. 0. 0. 0.] [0. 0. 0. 0.]] ''' np.eye((3,1)) ''' [[0. 1. 0.] [0. 0. 1.] [0. 0. 0.]] ''' np.full((2,3),[1,2,3]) ''' [[1 2 3] [1 2 3]] ''' - 全0矩阵:
- 随机矩阵:
使用random模块- rand:返回0-1间均匀分布的随机数组.rand(维度)。
np.random.rand(2) # [0.23880738 0.62155061] a = np.random.rand(2,2) ''' [[0.96465804 0.39139561] [0.33776915 0.48402092]] '''- randn:返回N(0,1)标准正态分布随机数,平均数0,方差1.
- randint:返回随机整数,
randint(最小值,最大值,几行几列) - choice:从一维数组中生成随机数,以一定概率和方式抽取结果。第一个参数是1维数组,如果只有一个数字则看成range(数字);第二个参数是数组维度。
- permutation:把一个数组随机排列或者数字全排列。
np.random.permutation(5) # range(5) # [1 2 4 3 0] x=['a','b','c','d'] np.random.permutation(x) # ['d' 'a' 'c' 'b'] - 随机种子:random.seed(数值),只要seed里的数值一样,随机出来的结果就一样。
2.2 数组的变形与合并
- 转置:
.T,顺时针旋转,原来的行变成列,列变成行。date=np.arange(1,7).reshape((3,2)) print(date) print(date.T) ''' [[1 2] [3 4] [5 6]] [[1 3 5] [2 4 6]] ''' - 维度转换:
reshape,不改值只修改形状,按照新的维度重新排列。有两种读取填充模式,分别是C模式(逐行)和F模式(逐列)。(逐行/列读取并逐行/列填充)a=np.arange(8).reshape(2,4) print(a) b=a.reshape((4,2),order='C') # 按行读取填充 print(b) c=a.reshape((4,2),order='F') # 按列读取填充 print(c) ''' [[0 1 2 3] [4 5 6 7]] [[0 1] [2 3] [4 5] [6 7]] [[0 2] [4 6] [1 3] [5 7]] '''- 由于被调用的数组大小是确定的,所以reshape允许有一个维度存在空缺,用-1填充即可。
# 面将 n*1 大小的数组转为 1 维数组 a=np.ones((3,1)) print(a) b=a.reshape(-1) print(b) ''' [[1.] [1.] [1.]] [1. 1. 1.] ''' - 合并操作:对二维数组而言,
r_(上下合并)c_(左右合并)。当一维数组和二维数组合并时,把一维数组视为列向量,在长度匹配的情况只能使用c_操作。a=np.r_[np.array([0,0]),np.zeros(2)] b= np.c_[np.array([0,0]),np.zeros((2,3))] print(a) print(np.zeros(2)) print(b) ''' [0. 0. 0. 0.] [0. 0.] [[0. 0. 0. 0.] [0. 0. 0. 0.]] '''
2.3 数组的切片和索引
- 切片:类似Python里的slice
start:end:step切片,还可以直接传入列表指定某个维度的索引进行切片。a=np.arange(9).reshape(3,3) print(a) b=a[:-1,[0,2]] # 除去最后一行的所有行,第一列和第三列。 print(b) ''' [[0 1 2] [3 4 5] [6 7 8]] [[0 2] [3 5]] ''' - 布尔索引:
np.ix_在对应的维度上使用,但此时不能用slice切片c=a[np.ix_(([True, False, True], [True, False, True])] # 前面的是行,后面是列 print(c) ''' [[0 2] [6 8]] '''
2.4 常用函数
以下数组都是一维数组
- where:条件函数,可以指定满足条件与不满足条件位置的对应填充值
a=np.array([-2,4,0,-1]) np.where(a>0,a,2) # 对应位置为Ture时,填充a对应的原始,否则填充2. # [2 4 2 2] ``` - 返回索引的函数:
np.nonzero(数组)返回非零数的索引,数组.argmax()返回最大值的索引,数组.argmin()返回最小值的索引。 - 判断非零元素:
数组.any()序列至少存在一个 True 或非零元素时返回 True ,否则返回 False;数组.all()全为 True 或全是非零元素时返回 True ,否则返回 False。 - 累加和累乘函数:
数组.cumprod()累乘和数组.cumsum()累加,(当前列之前的和放到当前列上)返回同长度的数组。diff表示和前一个元素做差,因为第一个元素为缺失值,所以返回长度是原数组长度-1.a = np.array([1,2,3]) a.cumprod() # 累乘 # [1, 2, 6] a.cumsum() # 累加 # [1, 3, 6] - 统计函数:待
2.5 广播机制
- 广播机制:制用于处理两个不同维度数组之间的操作
- 标量和数组:当一个标量和数组进行运算时**,标量会自动把大小扩充为数组大小**,之后进行逐元素操作
a = 3 * np.ones((2,2)) + 1 print(a) ''' [[4., 4.], [4., 4.]] ''' - 二维数组之间:当两个数组维度完全一致时,使用对应元素的操作,否则会报错,除非其中的某个数组的维度是 m x 1 或者1 x n ,那么会扩充其具有 1 的维度为另一个数组对应维度的大小。
a=np,ones((3,2)) b=res*np.array([2,3]) # 将1*2的1扩展成3行。 print(b) ''' [[2., 3.], [2., 3.], [2., 3.]] ''' - 一维数组和二维数组:当一维数组A k A_{k}Ak与二维数组B m , n B_{m,n}Bm,n操作时,等价于把一维数组视作 A 1 , k A_{1,k}A1,k的二维数组。然后按照二维数组之间的操作方法。
2.6 向量与矩阵计算
- 向量内积:
向量1.dot(向量2)a ⋅ b = ∑ i a i b i \mathbf{a} \cdot \mathbf{b}=\sum_{i} a_{i} b_{i}a⋅b=∑iaibi。(积的和) - 矩阵乘法:
矩阵1@矩阵2[ A m × p B p × n ] i j = ∑ k = 1 p A i k B k j \left[\mathbf{A}_{\mathrm{m} \times \mathrm{p}} \mathbf{B}_{\mathrm{p} \times \mathrm{n}}\right]_{\mathrm{ij}}=\sum_{\mathrm{k}=1}^{\mathrm{p}} \mathbf{A}_{\mathrm{ik}} \mathbf{B}_{\mathrm{kj}}[Am×pBp×n]ij=∑k=1pAikBkj
矩阵乘法中第一个矩阵的列要等于第二个矩阵的行,一个m∗n的的A矩阵,和一个n∗p的B矩阵相乘,将得到一个m∗p的矩阵C 。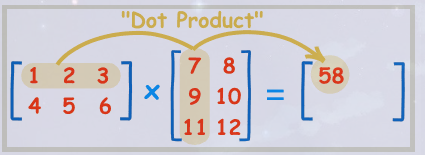
- 向量范数和矩阵范数:待
3 练习题
1.:利用列表推导式写矩阵乘法
改写为列表推导式
答案:
# 分析
In [138]: M1 = np.random.rand(2,3) # 两行三列
In [139]: M2 = np.random.rand(3,4) # 三行四列
In [140]: res = np.empty((M1.shape[0],M2.shape[1]))
# empty创建一个全部元素为空的数组,
# shape读取矩阵的长度,shape[0]就是读取矩阵第一维度的长度
In [141]: for i in range(M1.shape[0]): # M1.shape[0]为2
.....: for j in range(M2.shape[1]): # # M2.shape[1]为4
.....: item = 0
.....: for k in range(M1.shape[1]): # M1.shape[1]为3
.....: item += M1[i][k] * M2[k][j]
.....: res[i][j] = item
.....:
In [142]: ((M1@M2 - res) < 1e-15).all() # 排除数值误差
Out[142]: True
res = [[sum([M1[i][k] * M2[k][j] for k in range(M1.shape[1])])
for j in range(M2.shape[1])] for i in range(M1.shape[0])]
# 大循环在最外侧,
2.更新矩阵
答案:
A=np.arange(1,10).reshape(3,3)
B = A*(1/A).sum(1).reshape(-1,1)
print(B)
'''
[[1.83333333 3.66666667 5.5 ]
[2.46666667 3.08333333 3.7 ]
[2.65277778 3.03174603 3.41071429]]
'''
3.待
4.待
5.待
4 学习总结
Python部分之前在DW的学习小组里学过,但是之后就没有用了,这次又相当重过了一遍。但是万万没想到还有Numpy,我大意了,之前一点没学过,报pandas的时候看准备也只有python基础,没说要有numpy基础,而且还涉及了好多数学知识。截至时间之前无法全部完成了,在下次打卡前把numpy和必要的数学知识补上。
版权声明:本文为OohMuYi原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。