图灵TOPIA
作者:Laurent Montier
编译:刘静
图灵联邦编辑部出品
如果你是一名计算机视觉领域的数据科学家,你可能也意识到自己需要一个快速而简单的标记工具,原因至少有以下两个:为PoC或R&d实验创建数据集
确保你的数据质量,这样它就不会影响你的深度学习算法的性能
 分割数据(蓝色)和检测数据(紫色)之间的差异 您也可能已经意识到,AI项目成功的最重要因素之一是您可以使用的“质量数据”的数量。我对计算机视觉应用的“ 质量数据 ”的意思是:
分割数据(蓝色)和检测数据(紫色)之间的差异 您也可能已经意识到,AI项目成功的最重要因素之一是您可以使用的“质量数据”的数量。我对计算机视觉应用的“ 质量数据 ”的意思是:每张图片/注释都有一个合适的标签
每个边界框或多边形准确地围绕实体进行训练
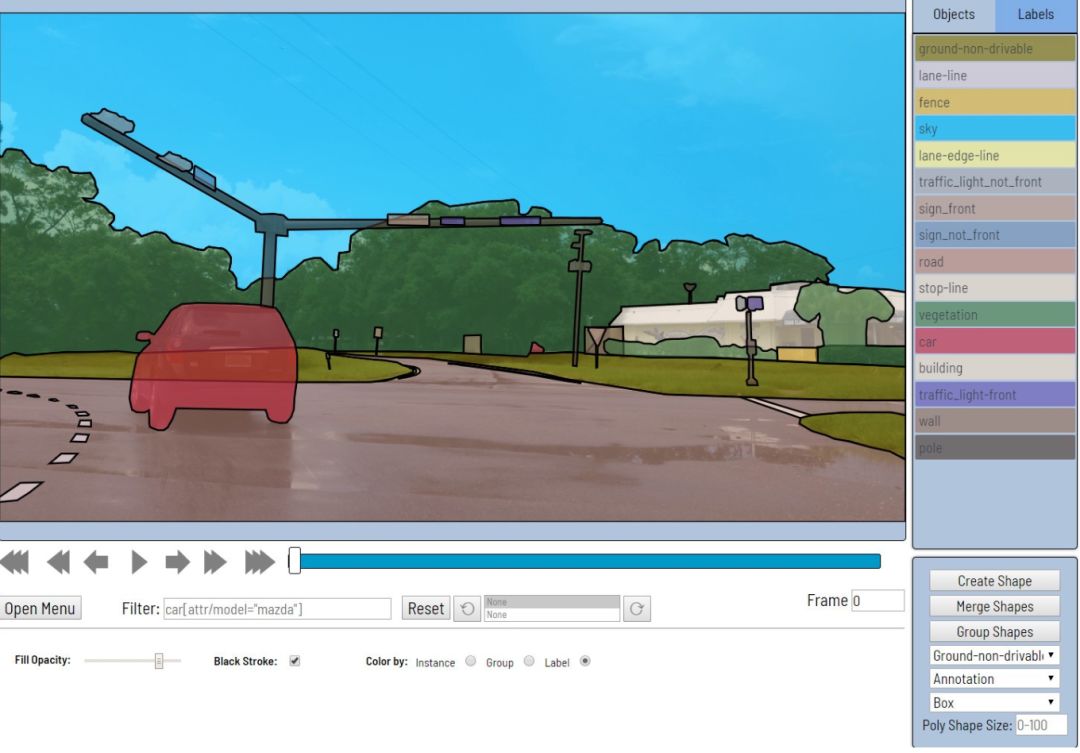 计算机视觉注释工具(CVAT) 在推出OpenCV近20年后,Intel在计算机视觉领域重申并发布了CVAT,这是一个非常强大和完整的注释工具。尽管它需要一些时间来学习和掌握,它提出了大量的功能来标记计算机视觉数据。 优点:
计算机视觉注释工具(CVAT) 在推出OpenCV近20年后,Intel在计算机视觉领域重申并发布了CVAT,这是一个非常强大和完整的注释工具。尽管它需要一些时间来学习和掌握,它提出了大量的功能来标记计算机视觉数据。 优点:它很容易安装和扩展,因为它是一个运行在Docker中的web应用程序
提出了许多自动化工具(如使用TensorFlow*对象检测API的自动标注、视频插值等)
它允许管理协作工作,这样团队中的不同成员就可以在同一个注释任务上协同工作
UI相当复杂。例如,第一次设置注释任务可能非常棘手
一开始不是很直观,可能需要几天的时间来掌握
只能在Chrome运行,所以你必须找到解决办法,如果你害怕谷歌…
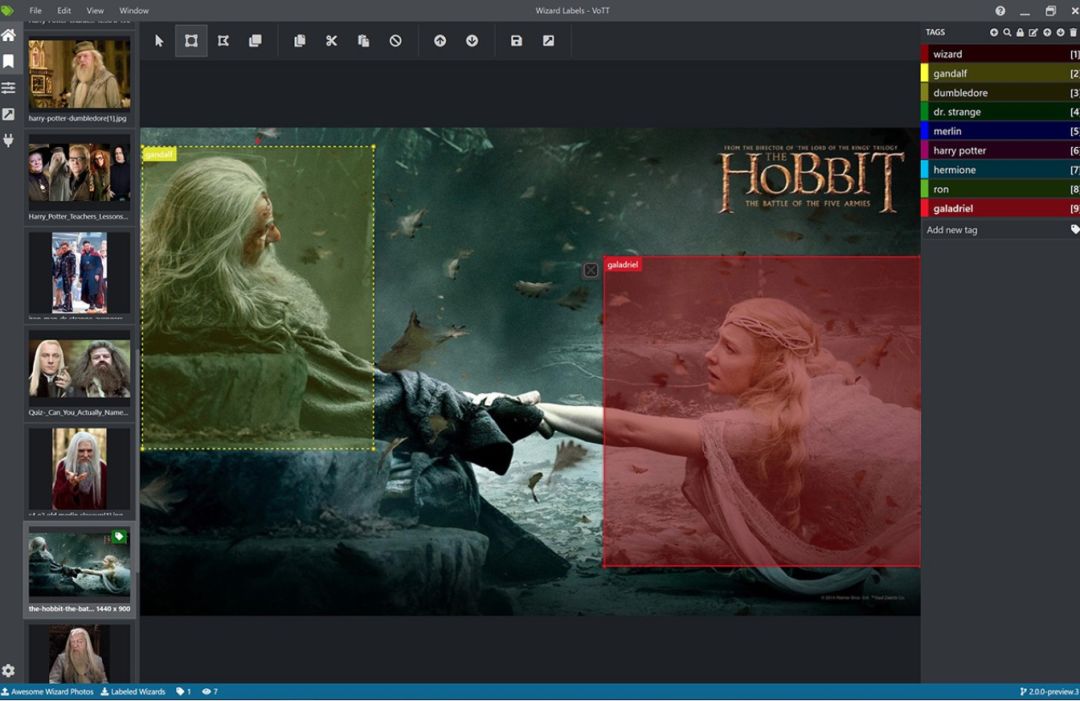 视觉对象标记工具(VoTT) VoTT由微软开发,提供了极好的用户体验,可以在注释时节省大量的时间和精力。此外,创建项目也很简单,因此您无需深入了解文档即可使用它。 优点:
视觉对象标记工具(VoTT) VoTT由微软开发,提供了极好的用户体验,可以在注释时节省大量的时间和精力。此外,创建项目也很简单,因此您无需深入了解文档即可使用它。 优点:代码编写得非常好(在React中),并且完美地定义了接口,因此很容易fork并添加所需的额外功能
正如我所说的,UX是完美的,它有一个黑色的主题和一个跟随鼠标的虚线网格,所以很容易知道从哪里开始一个边界框。这看起来像是一种奖励,但是相信我,这真的很重要!
它建议使用深度学习算法来自动检测对象(它附带了在COCO类上训练的SSD)
它是一个web应用程序和一个电子应用程序。这使您可以将它作为一个thick客户端使用,也可以将它用于web浏览器中运行的应用程序
要使用web应用程序版本,您需要将数据托管在微软的云计算服务Azure上(然而,电子版本允许您在硬盘上使用数据,但需要使用npm安装)。
它没有提供一个内置的API(但是调整代码使您的私有API能够与之通信是非常容易的)
您不能给图片贴标签:您只被允许绘制带有相关标签的边界框(或多边形)。因此,它不适合创建分类数据集
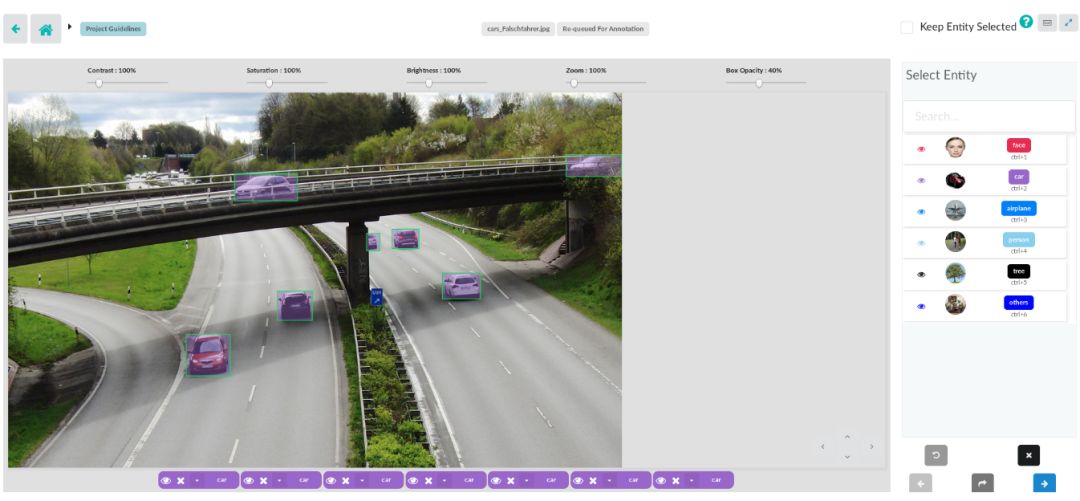 DataTurks DataTurks是一家成立于2018年的初创公司,提供图片、视频和文字的标记服务。然而,直到最近它才成为开源软件(这可能与沃尔玛在2019年2月购买了它有关),此前你都必须为此付费。尽管他们几乎没有就此进行沟通并且似乎已经停止了任何开发,但是注释工具很棒且现在是免费的!
DataTurks DataTurks是一家成立于2018年的初创公司,提供图片、视频和文字的标记服务。然而,直到最近它才成为开源软件(这可能与沃尔玛在2019年2月购买了它有关),此前你都必须为此付费。尽管他们几乎没有就此进行沟通并且似乎已经停止了任何开发,但是注释工具很棒且现在是免费的!当您使用它时,不要注意任何许可证,也不要限制在不同地方使用的非商业版本。Dataturks现在是免费的,您可以使用它的所有功能(我已经尝试并测试过了)!优点:
至于CVAT,它是一个在Docker中运行的web应用程序(查看下面链接获取Docker镜像)
允许协作和异步工作:处理同一数据集的两个团队成员将无法获得相同的图像进行注释
提出一种用于创建和获取注释任务的API
DataTurks似乎已经停止了其产品的开发
UX还可以,但是一些小的调整就可以让它变得更好
 MakeSense.ai Make-Sense https://www.makesense.ai/ Make-sense在两个月前刚刚发布(如果你在未来读到这篇文章,将会在2019年6月发布),并且已经拥有了令人难以置信的用户体验。开始注释从来没有这么快!进入网站,拖放你的图片并开始注释。 优点:
MakeSense.ai Make-Sense https://www.makesense.ai/ Make-sense在两个月前刚刚发布(如果你在未来读到这篇文章,将会在2019年6月发布),并且已经拥有了令人难以置信的用户体验。开始注释从来没有这么快!进入网站,拖放你的图片并开始注释。 优点:快速,高效,但最重要的是,简单!
很酷的用户体验
至于你上传的图片的隐私问题,不要担心,因为他们说:“他们不会存储你的图片,因为他们一开始就不会把它们发送到任何地方。”
不提供任何项目管理功能
也不提供任何API
Coco-Annotator似乎功能齐全,而且它是最近发布的(用户身份验证系统,API端点)。在下面的链接查看演示(用户名:admin 密码:password)
https://annotator.justinbrooks.ca/#/
原文链接: https://blog.sicara.com/best-open-source-annotation-tools-in-computer-vision-4b9f6a18f911