目录
2.argmaxaccuracy = (output.argmax(1) == targets).sum()
5.最后看准确率要把tensor数据类型转普通数据,.item()
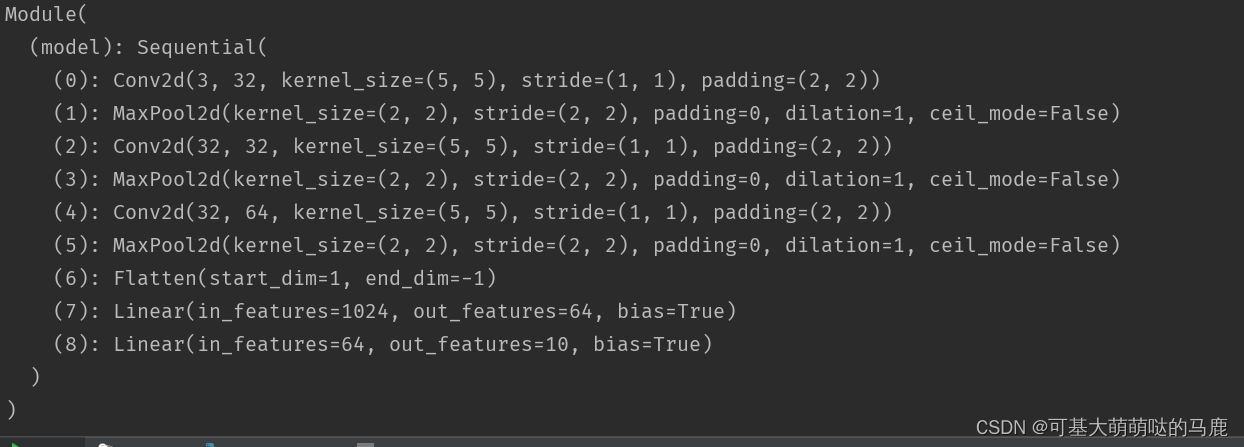
1.模型结构
# 搭建神经网络
import torch
from torch import nn
class Module(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=(5, 5), padding=2, stride=1, dilation=1),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Conv2d(32, 32, kernel_size=(5, 5), padding=2),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Conv2d(32, 64, kernel_size=(5, 5), padding=2),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, input):
output = self.model(input)
return output
# 测试模型是否准确
if __name__== '__main__':
module = Module()
input = torch.ones((64,3,32,32))
output = module(input)
print(output.shape)2.train
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备训练数据集
from torch import nn
from torch.utils.data import DataLoader
import time
train_data = torchvision.datasets.CIFAR10(root='E:\QQPCmgr\Desktop\Android_learn\pytorch\dataset',train=True,transform=torchvision.transforms.ToTensor()
,download=True)
test_data = torchvision.datasets.CIFAR10(root='E:\QQPCmgr\Desktop\Android_learn\pytorch\dataset',train=False,transform=torchvision.transforms.ToTensor()
,download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print('训练数据集的长度为{}'.format(train_data_size))
print('测试数据集的长度为{}'.format(test_data_size))
# 用dataLoader加载数据集
train_data_Loader = DataLoader(train_data,batch_size=64)
test_data_Loader = DataLoader(test_data,batch_size=64)
# 创建网络模型
module = Module()
# 网络模型转移到cuda
if torch.cuda.is_available():
module = module.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 损失函数放在cuda
loss_fn = loss_fn.cuda()
# 优化器(1*10^-2)
learning_rate = 1e-2
optimizer = torch.optim.SGD(module.parameters(),lr=learning_rate)
# 设置训练网络的一些参数,训练次数,测试次数,训练的轮数
train_step = 0
test_step = 0
epoch = 10
# 添加tensorboard
writer = SummaryWriter('logs')
start_time = time.time()
for i in range(epoch):
module.train()
print("-----第{}轮训练开始-----".format(i+1))
for data in train_data_Loader:
imgs ,targets = data
# 训练数据转cuda
imgs = imgs.cuda()
targets = targets.cuda()
output = module(imgs)
loss = loss_fn(output,targets)
# 优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_step = train_step+1
if train_step %100 ==0:
print('训练次数:{},LOSS={}'.format(train_step,loss),)
writer.add_scalar("train_loss",loss.item(),train_step)
# 每一轮训练后测试
total_test_loss = 0
# 整体正确率
total_accuracy = 0
accuracy = 0
# 测试模式
module.eval()
with torch.no_grad():
for data in test_data_Loader:
imgs ,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
output = module(imgs)
loss = loss_fn(output,targets)
total_test_loss = total_test_loss+loss
accuracy = (output.argmax(1) == targets).sum()
print(accuracy)
total_accuracy = (total_accuracy +accuracy).item()
# 最好转item数据类型,不然这个accuracy会是一个tensor的数据类型
print(total_accuracy)
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的准确率为:{}".format(total_accuracy/test_data_size))
test_step +=1
writer.add_scalar("test_loss",total_test_loss,test_step)
writer.add_scalar("测试准确率",total_accuracy/test_data_size,test_step)
# torch.save(module,"module_{}.pth".format(i+1))
# 官方推荐的模型保存方式
# torch.save(module.state_dict(),"module_{}.pth".format(i+1))
print("模型已保存")
writer.close()
end_time = time.time()
print(end_time-start_time)需要注意的事项:
1.一些语句
module.train()
module.eval()
with torch.no_grad()最好加上
因为在测试的时候,我们不需要梯度,不需要对参数进行优化
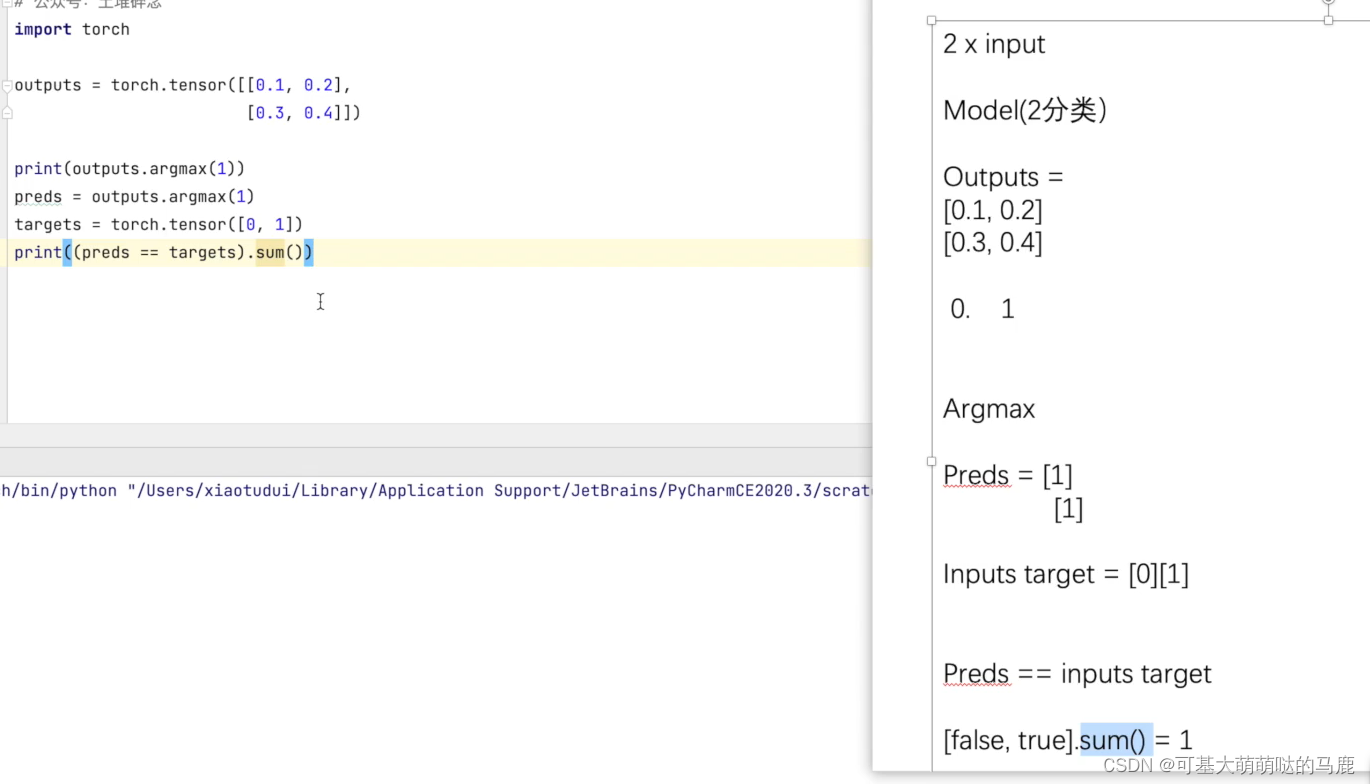
2.argmax
accuracy = (output.argmax(1) == targets).sum()这行代码的意思如下:
argmax表示横向取最大值
先得到概率最大的Index->[0,1]
再用preds ==targets 比较,得到(false,true)
最后.sum求所有的true的个数之和

3.无法引用自己写的类
如果发现自己写的类不能引用,可以这样设置,把要引用的文件夹设置成source

4.保存模型
- 当使用官方推荐的转成字典格式的模型时,可以这样读取:
- 先load模型参数,再初始化模型对象,最后用字典的方式去读取模型
import torch from model import * dict_modle = torch.load('module_1.pth') module1 = Module() module1.load_state_dict(dict_modle) print(module1)
5.最后看准确率要把tensor数据类型转普通数据,.item()
计算准确率或者输出看loss,准确率时,需要把原来的tensor数据类型,转成普通的数字
即.item()进行转换
total_accuracy = (total_accuracy +accuracy).item() # 最好转item数据类型,不然这个accuracy会是一个tensor的数据类型,tensor数据类型和一个普通的数据相除,结果一定是0如果不转,就会输出:

版权声明:本文为weixin_42934729原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。