前言:
最近在看不同的代码,发现有几个地方存在疑惑,所以梳理一下。
1. model.eval() model.train()
2.volatile=True or false
3. requires_grad = True or false
4. with torch.no_grad():
这个几个地方用来操作或者限定tensor在训练或者测试阶段是否进行:求导,或者一些其他限定。
一、 model.eval() model.train()
官方文档
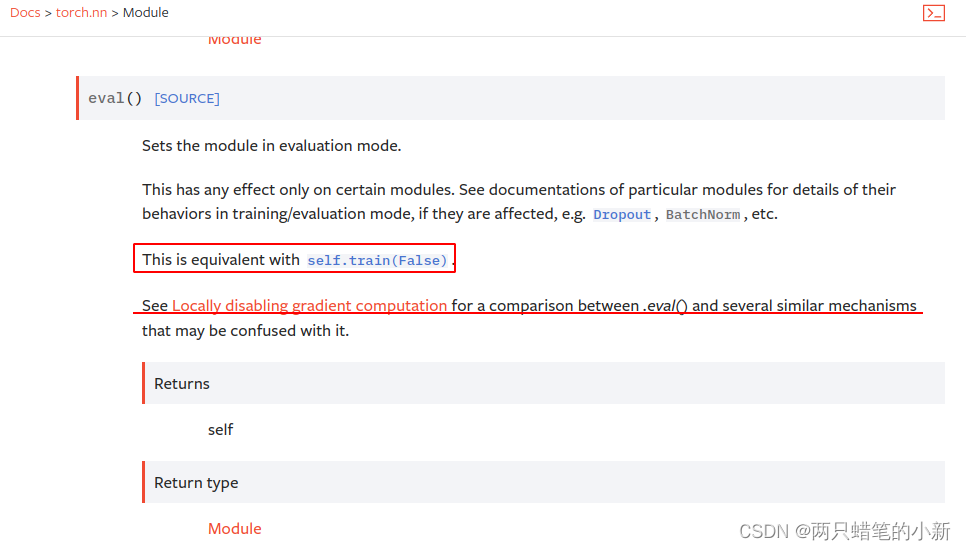
从红色的方框可以看出model.eval() = model.train(False),那么再来看model.train()
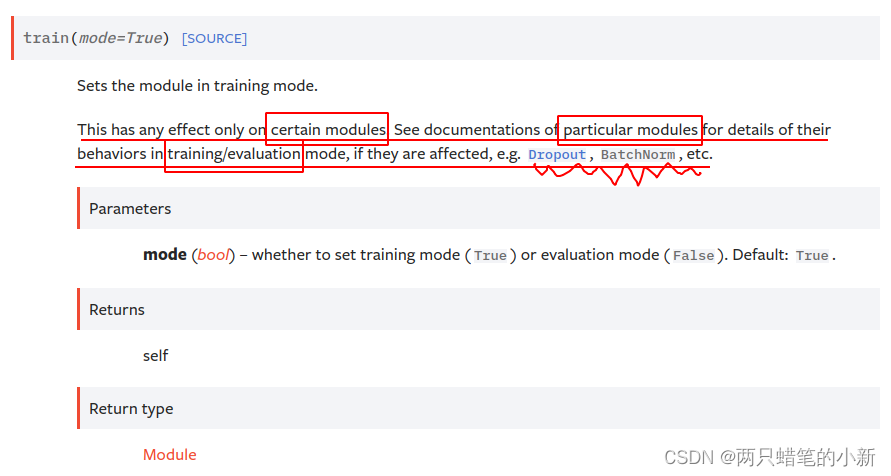
几层意思:
1.等价关系
>> model.train() = model.train(True)
>>model.eval() = model.train(False)
2.这种命令只对特定的模块起作用,例如Dropout, BatchNorm, etc.
model的eval方法主要是针对某些在train和predict两个阶段会有不同参数的层。比如Dropout层和BN层。但是在查阅资料,没有找到除了这两个以外的其他的模块。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
总结:model.eval() model.train()只对例如 Dropout, BatchNorm的起作用
二、volatile=True or false
该参数来源于:
torch.autograd.Variable(tensor,volatile=volatile)
该参数已经被废弃了,如果强行使用,会出现以下警示:
orch.autograd.Variable(tensor,volatile=True)
UserWarning: volatile was removed and now has no effect. Use `with torch.no_grad():` instead.
这个参数已经没有作用了。
三、requires_grad = True or false
使用该变量 torch.autograd.Variable(tensor,requires_grad=True or False)
指定要不要更新这个参数(通过梯度(迭代)来更新),对于不需要更新的参数,可以把它设定为False,可以加快运算。Variable默认是不需要求导的,即requires_grad属性默认为False,如果某一个节点requires_grad被设为True,那么所有依赖它的节点requires_grad都为True。
用户在手动定义Variable时,参数requires默认值是False。而在Module中的层在定义时,相关的Variable的requires_grad参数默认是True。在计算图中,如果有一个输入的requires_grad是True,那么输出的requires_grad也是True。只有在所有输入的requires_grad都为False时,输出的requires_grad才为False。
高阶使用请看文档:
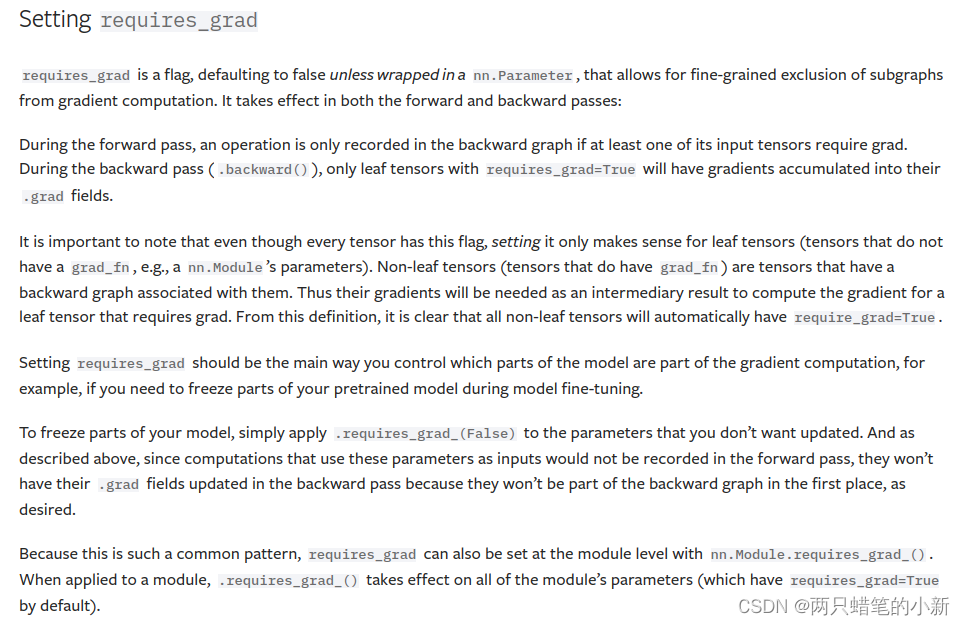
requires_grad是一个标志,默认为 false除非包含在 a nn.Parameter中,它允许从梯度计算中细粒度地排除子图。(这句话是直接google翻译的,博主的理解是:在梯度计算的时候,可以很详细的指定哪些变量不求梯度,例如在微调模型的时候)它在向前和向后传递中都生效:
在前向传播期间,如果其输入张量中的至少一个需要计算梯度,则仅在后向图中记录操作。在后向传递(.backward())期间,只有require_grad=True的叶张量才会在其.grad字段中累积梯度。
重要的是要注意,即使每个张量都有这个标志, 设置它只对叶张量有意义(叶张量:一个没有grad_fn的张量 ,例如 ann.Module的参数)。非叶张量(具有grad_fn的张量)是具有与其相关联的后向图的张量。因此,需要它们的梯度作为中间结果来计算需要 grad 的叶张量的梯度。从这个定义中,很明显所有非叶张量都会自动具有require_grad=True.
设置requires_grad应该是您控制模型的哪些部分是梯度计算的主要方式,例如,如果您需要在模型微调期间冻结部分预训练模型。
要冻结模型的某些部分,只需应用.requires_grad_(False)您不想更新的参数即可。如上所述,由于使用这些参数作为输入的计算不会记录在前向传递中,因此它们不会.grad在后向传递中更新其字段,因为它们首先不会成为后向图的一部分,如预期的。
因为这是一种常见的模式,requires_grad所以也可以在模块级别使用nn.Module.requires_grad_(). 应用于模块时,对模块的所有参数(默认.requires_grad_()具有)生效。requires_grad=True
四、with torch.no_grad()
官方文档:no_grad — PyTorch 1.12 documentation
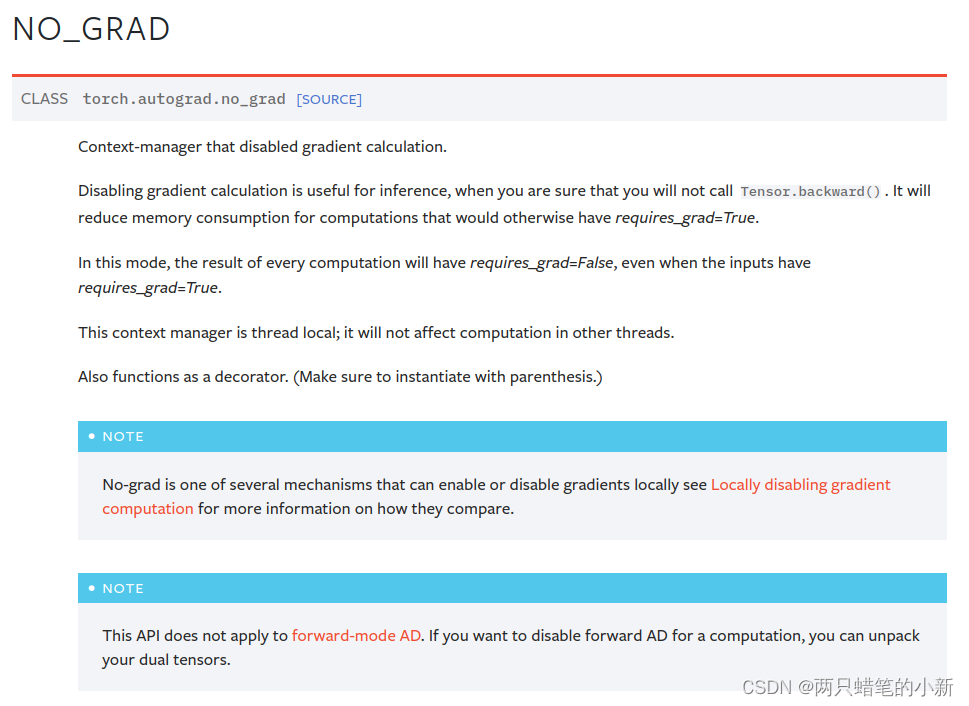
禁用梯度计算的上下文管理器。
当您确定不会调用Tensor.backward(). 它将减少原本需要 requires_grad=True的计算的内存消耗。在这种模式下,每次计算的结果都会有 requires_grad=False,即使输入有requires_grad=True。这个上下文管理器是线程本地的(也就是说,这个是);它不会影响其他线程中的计算。
最后、测试代码
import torch
from torch.autograd import Variable
'''
1.pytorch中的求导操作:
volatile=True or false 该参数已经不起作用了
'''
x1 = Variable(torch.ones(2, 2)*2, requires_grad=False)
x2 = Variable(torch.ones(2, 2)*3, requires_grad=True)
x3 = Variable(torch.ones(2, 2)*4, requires_grad=True)
print(x1)
print(x2)
print(x3)
print("---------")
# print(x1.data)
y = x1*x3 + x2
t_1 = y.sum()
print(y)
t_1.backward()
print(x1.grad)
print(x2.grad)
print(x3.grad)