视频链接:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
RNN循环神经网络是用来处理有时间前后顺序的输入数据,典型的就是自然语言处理了。
目录
3.使用RNNCell建立模型:'hello'->'ohlol'
1.RNNcell
RNN cell的本质就是全连接层,只不过它的输入来自两个部分,一个部分是上次运行结果的输出,另一个部分是本次的输入数据,具体如下图:
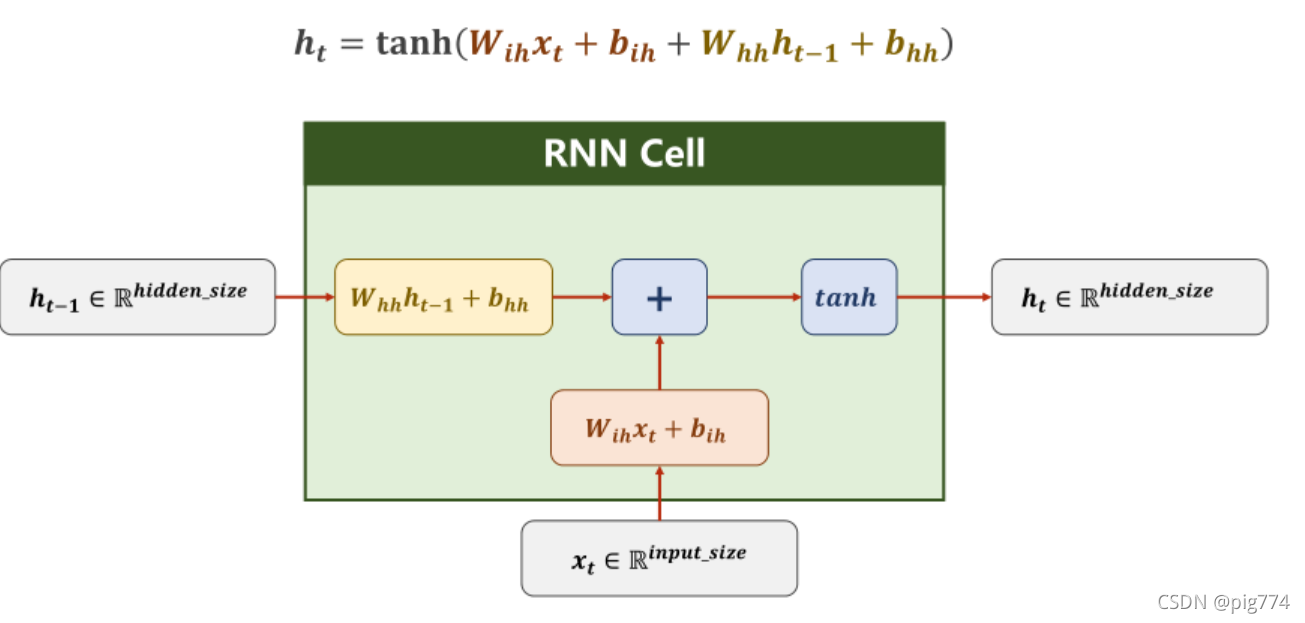
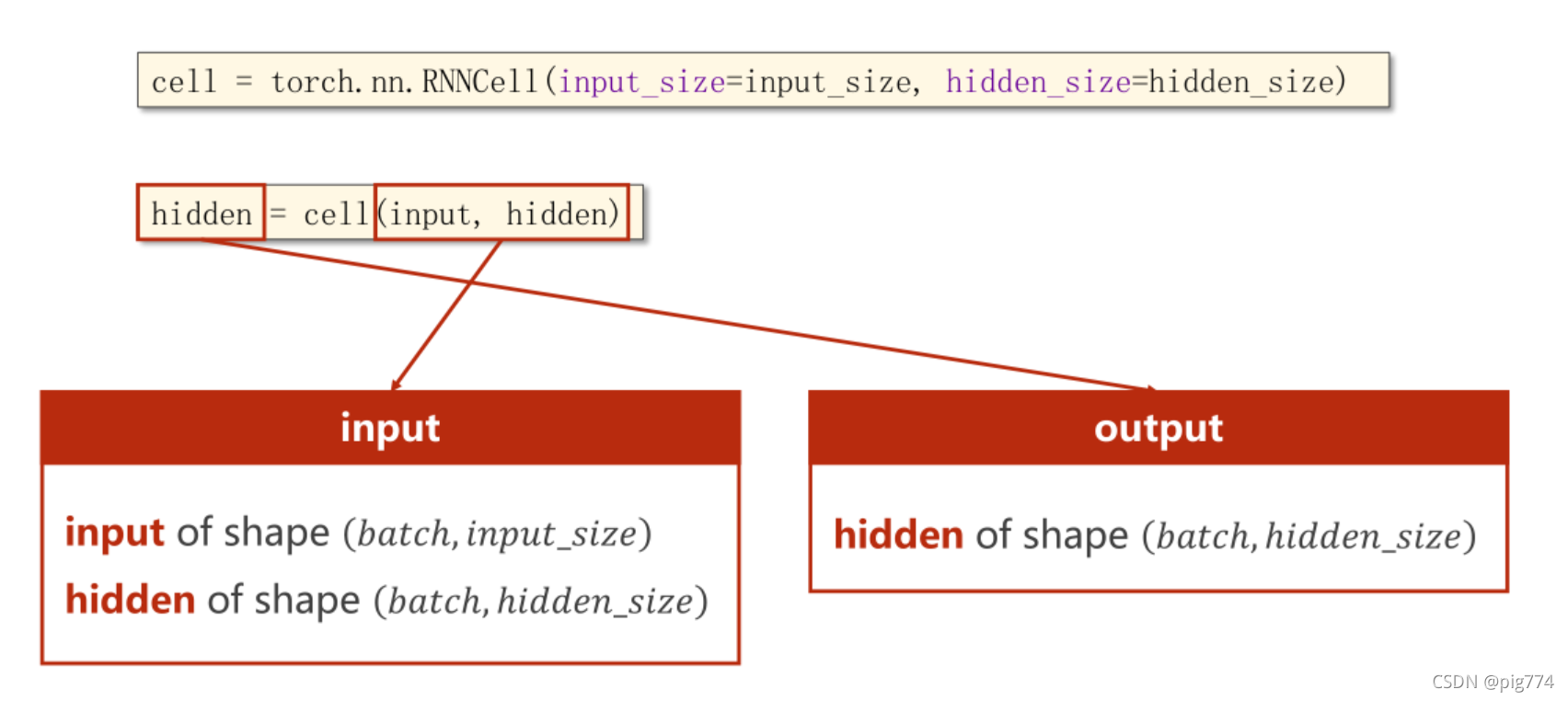
通过下面的代码可以清楚地理解参数之间维度的关系
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
datasets = torch.randn(seq_len,batch_size, input_size)
hidden = torch.zeros(batch_size, hidden_size)
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
# 进行一个RNN,而不是一个RNNcell
for idx, input in enumerate(datasets):
print('*' * 20, idx)
print('input_size:', input.shape)
hidden = cell(input, hidden)
print('input的权重形状')
print(cell.weight_ih.shape)
print('input的偏置形状')
print(cell.bias_ih.shape)
print('outputs size:', hidden.shape)
print('hidden的权重形状')
print(cell.weight_hh.shape)
print('hidden的偏置形状')
print(cell.bias_hh.shape)
print(hidden)我这里只给出一个RNNcell的结果:
******************** 0
input_size: torch.Size([1, 4])
input的权重形状
torch.Size([2, 4])
input的偏置形状
torch.Size([2])
outputs size: torch.Size([1, 2])
hidden的权重形状
torch.Size([2, 2])
hidden的偏置形状
torch.Size([2])
tensor([[-0.6161, -0.1936]], grad_fn=<TanhBackward0>)
从结果可以看出,内部的真正的运算为:
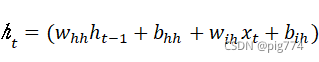
2.RNN
下面我们来看一下整个RNN层的运算流程图:
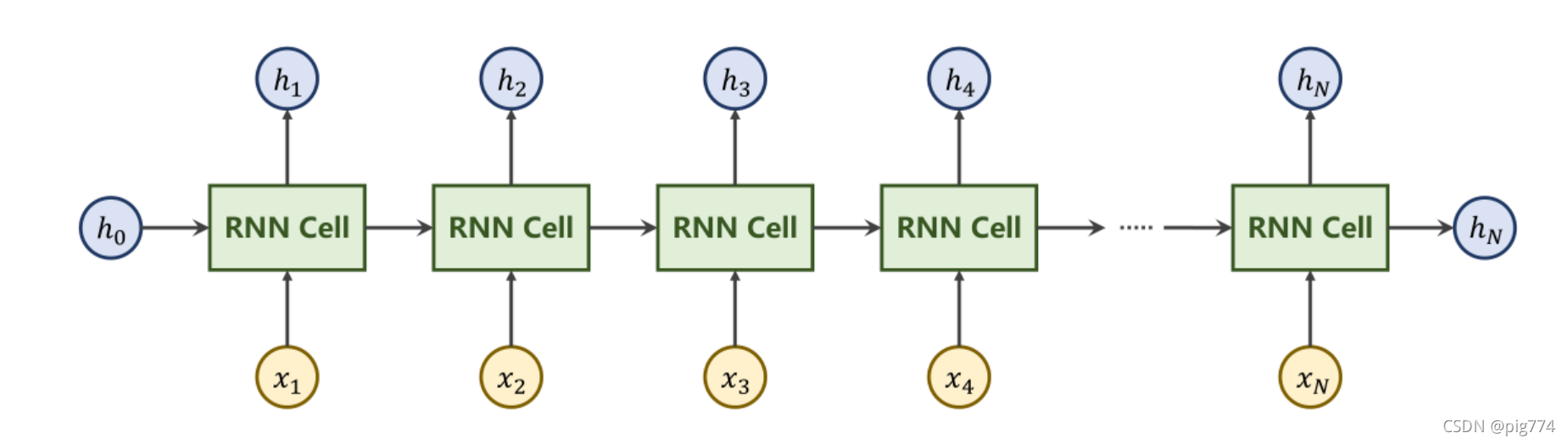
这里我们使用torch.nn.RNN就可以一次性执行多个RNNcell操作,但参数会比之前多一个num_layers,

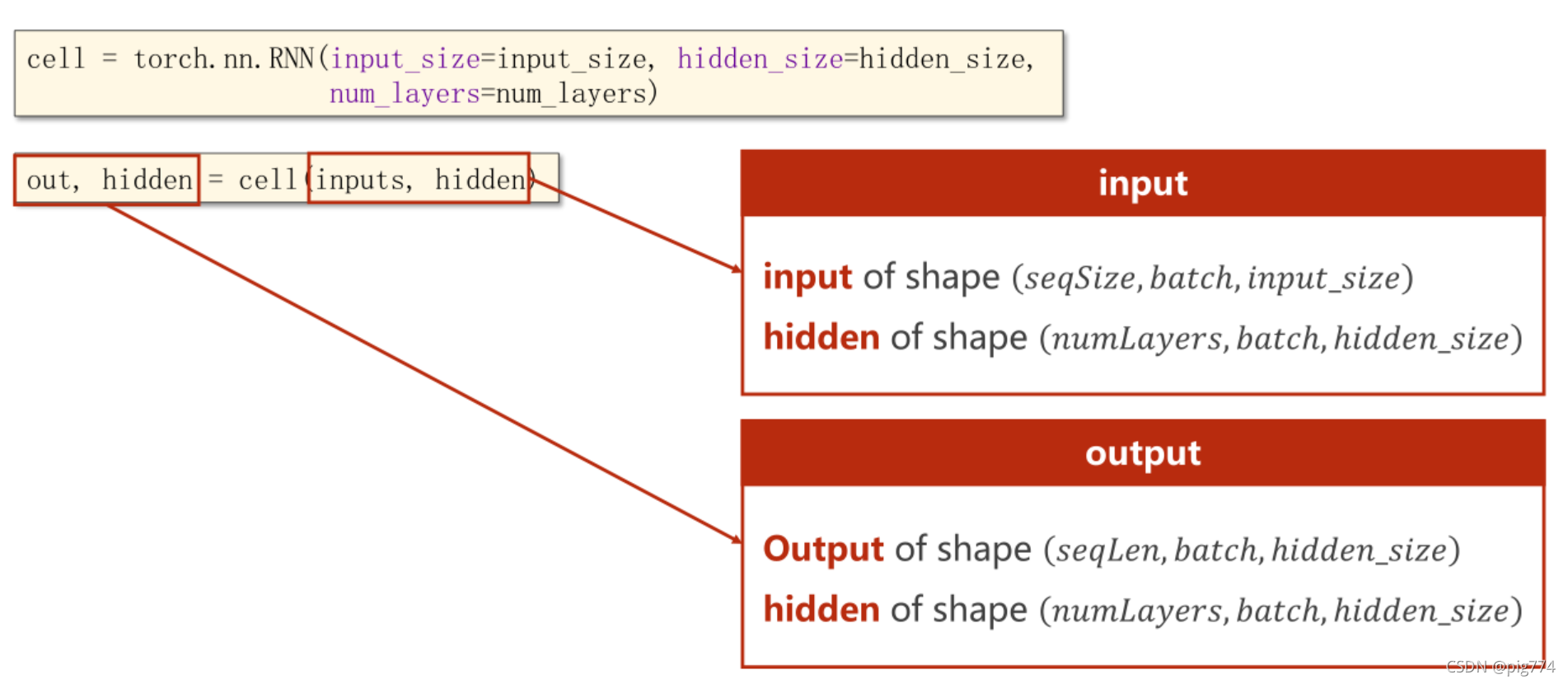
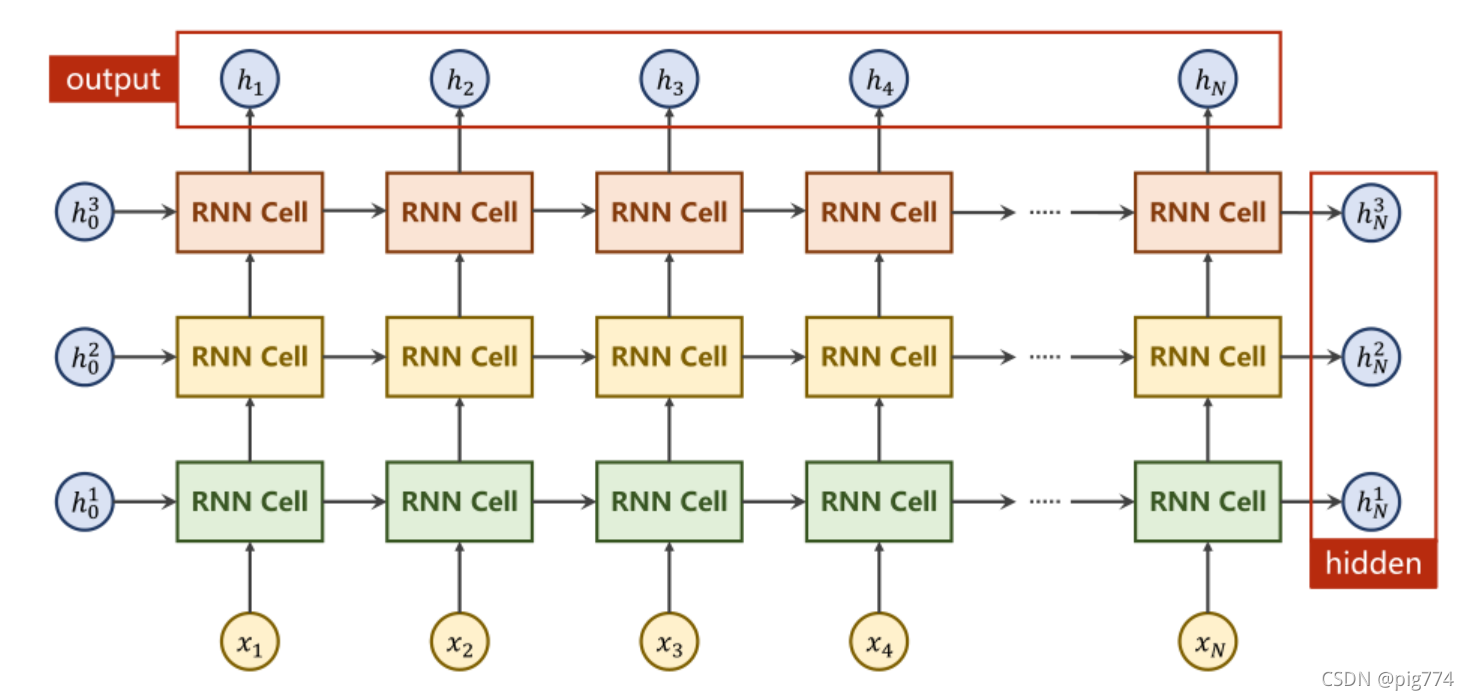
hidden是再作为下一次的输入数据的,output就是该次序列的预测的输出结果。
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
datasets = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
# 生成RNN层
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
# 执行
out, hidden = cell(datasets, hidden)
print('out size:', out.shape) # [3,1,2]
print('out:', out)
print('hidden size:', hidden.shape) # [1,1,2]
print('hidden', hidden)
输出结果:
out size: torch.Size([3, 1, 2])
out: tensor([[[ 0.6453, -0.7334]],
[[-0.0879, -0.9478]],
[[-0.2888, -0.9519]]], grad_fn=<StackBackward0>)
hidden size: torch.Size([1, 1, 2])
hidden tensor([[[-0.2888, -0.9519]]], grad_fn=<StackBackward0>)
3.使用RNNCell建立模型:'hello'->'ohlol'
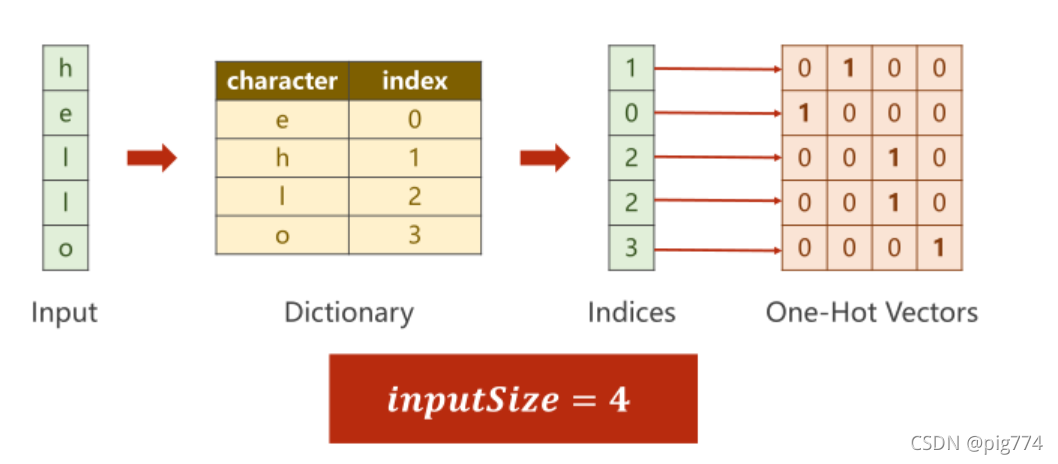
- 准备数据集,处理数据,将单词转变为向量
- 实现模型类
- 构造损失函数和优化器
- 训练
import torch
input_size = 4
hidden_size = 4
batch_size = 1
# 构造数据集
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3] # hello
y_data = [3, 1, 2, 3, 2] # ohlol
# 将x_data转变为向量
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
# 这里要是LongTensor
labels = torch.LongTensor(y_data).view(-1, 1) # reshape the labels (seqlen,1)
# 实现模型类
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=self.hidden_size)
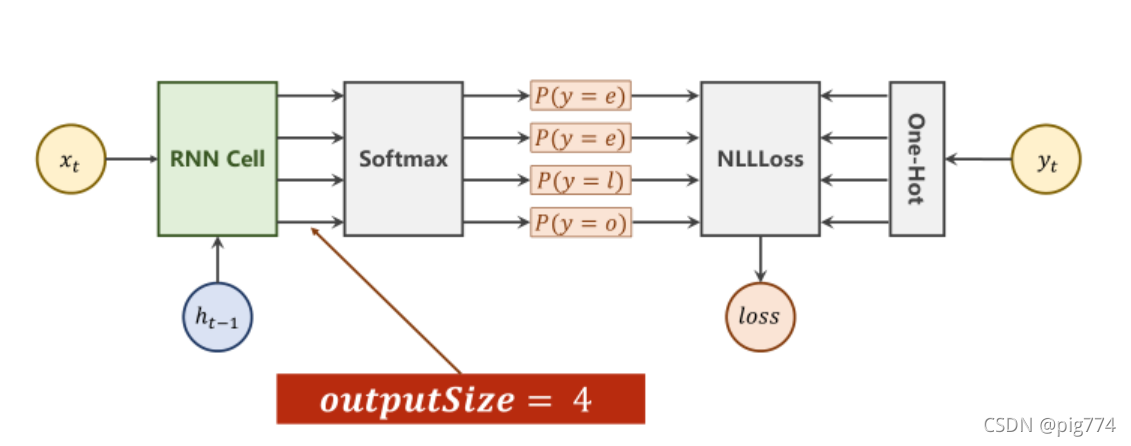
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
# 构造损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
# 训练
loss_list = []
for epoch in range(20):
loss = 0
optimizer.zero_grad()
# 每次开始训练前,都要将h0初始化
hidden = net.init_hidden()
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label)
# 取出最大值
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
print(' ', end='')
loss.backward()
optimizer.step()
loss_list.append(loss.item())
print(f'epoch={epoch+1},loss={loss.item()}')
结果如下:
lhehl epoch=1,loss=7.421962261199951
lolol epoch=2,loss=5.977343559265137
lolol epoch=3,loss=5.3166327476501465
lolol epoch=4,loss=4.806377410888672
lolol epoch=5,loss=4.240643501281738
lhlol epoch=6,loss=3.759169578552246
lhlol epoch=7,loss=3.4401092529296875
lhlol epoch=8,loss=3.1920981407165527
ohlol epoch=9,loss=2.9561209678649902
ohlol epoch=10,loss=2.7316439151763916
ohlol epoch=11,loss=2.5386734008789062
ohlol epoch=12,loss=2.391939640045166
ohlol epoch=13,loss=2.289687156677246
ohlol epoch=14,loss=2.213822603225708
ohlol epoch=15,loss=2.1478323936462402
ohlol epoch=16,loss=2.0885415077209473
ohlol epoch=17,loss=2.0389533042907715
ohlol epoch=18,loss=2.0001094341278076
ohlol epoch=19,loss=1.970154881477356
ohlol epoch=20,loss=1.9463403224945068
Process finished with exit code 0
4.使用RNN建立模型:'hello'->'ohlol'
import torch
input_size = 4
hidden_size = 4
batch_size = 1
# 构造数据集
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3] # hello
y_data = [3, 1, 2, 3, 2] # ohlol
# 将x_data转变为向量
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
# 这里要是LongTensor
labels = torch.LongTensor(y_data)
# 实现模型类
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
out, _ = self.rnn(input, hidden)
return out.view(-1, hidden_size)
net = Model(input_size, hidden_size, batch_size, num_layers=1)
# 构造损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
# 训练
loss_list = []
for epoch in range(20):
optimizer.zero_grad()
output = net(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
loss_list.append(loss.item())
_, idx = output.max(dim=1)
idx = idx.data.numpy()
print('predicted:', ''.join([idx2char[x] for x in idx]), end=' ')
print(f'epoch={epoch + 1},loss={loss.item()}')
predicted: lllll epoch=1,loss=1.4251950979232788
predicted: ellol epoch=2,loss=1.2052630186080933
predicted: lhlol epoch=3,loss=1.066596269607544
predicted: ohlol epoch=4,loss=0.961388885974884
predicted: ohlol epoch=5,loss=0.8782007098197937
predicted: ohlol epoch=6,loss=0.8153387308120728
predicted: ohlol epoch=7,loss=0.7574172616004944
predicted: ohlol epoch=8,loss=0.7028937935829163
predicted: ohlol epoch=9,loss=0.6582227349281311
predicted: ohlol epoch=10,loss=0.6231571435928345
predicted: ohlol epoch=11,loss=0.5856501460075378
predicted: ohlol epoch=12,loss=0.548419177532196
predicted: ohlol epoch=13,loss=0.5150136351585388
predicted: ohlol epoch=14,loss=0.4859493374824524
predicted: ohlol epoch=15,loss=0.4624292254447937
predicted: ohlol epoch=16,loss=0.4448699951171875
predicted: ohlol epoch=17,loss=0.4302904009819031
predicted: ohlol epoch=18,loss=0.4172581732273102
predicted: ohlol epoch=19,loss=0.40639621019363403
predicted: ohlol epoch=20,loss=0.39772507548332214
Process finished with exit code 0