前言:
JDK1.8对HashMap进行了比较大的优化,底层实现由之前的“数组+链表”改为“数组+单项链表+红黑树” ,本文具体介绍HashMap的储存模式与方法展开学习与讨论。
JDK 1.8的HashMap 的数据结构如下图所示:当链表节点较少时仍然是以链表存在,当节点大于较多时(大于8)会转为红黑树。
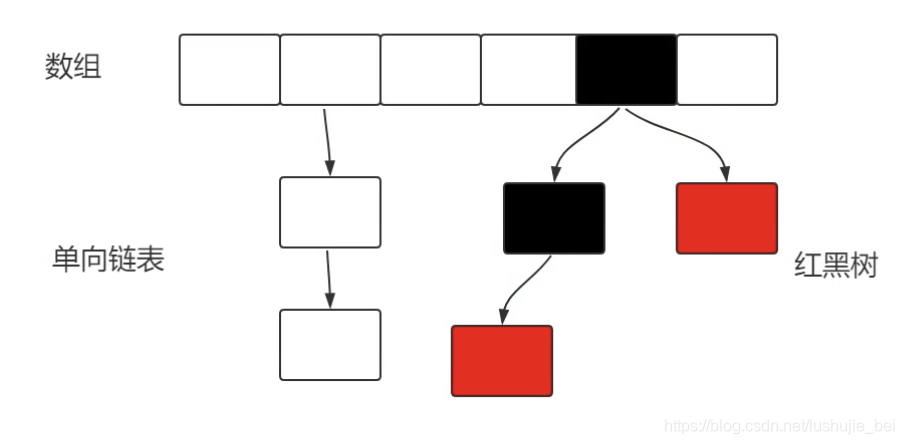
注意几个点:
1:本文中头节点
整个过程就三步:
1:拿到key的hashCode值
2:将hashCode的高位参与运输,重新计算hash值
3:将计算出来的hash值与(table.length-1)进行&运算
基本属性:

定位哈希桶数组索引位置:(重新计算hashCode)
不管增加,删除,查找键值对,定位到哈希数组的位置都是很关键的第一步,前面说过hashMap的数据结构是“数组+链表+红黑树”的结合,所以我们当然希望这个HashMap里面的元素位置尽量分布均匀一点,尽量使得每个位置上的元素数量只有一个 ,那么当我们用hash算法求的这个位置的死后,马上就可以知道对应位置的元素就是我们要的,不用遍历链表与红黑树,大大优化了查询效率,hashMap定位数组索引位置,直接决定了hash方法的离散性能,下面是定位哈希桶数组的源码;

方法解读:
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么计算得到的 hash 值总是相同的。我们首先想到的就是把 hash 值对 table 长度取模运算,这样一来,元素的分布相对来说是比较均匀的。
但是模运算消耗还是比较大的,我们知道计算机比较快的运算为位运算,因此 JDK 团队对取模运算进行了优化,使用上面代码2的位与运算来代替模运算。这个方法非常巧妙,它通过 “(table.length -1) & h” 来得到该对象的索引位置,这个优化是基于以下公式:x mod 2^n = x & (2^n - 1)。我们知道 HashMap 底层数组的长度总是 2 的 n 次方,并且取模运算为 “h mod table.length”,对应上面的公式,可以得到该运算等同于“h & (table.length - 1)”。这是 HashMap 在速度上的优化,因为 & 比 % 具有更高的效率。
在 JDK1.8 的实现中,还优化了高位运算的算法,将 hashCode 的高 16 位与 hashCode 进行异或运算,主要是为了在 table 的 length 较小的时候,让高位也参与运算,并且不会有太大的开销。
下图是一个简单的例子:
当 table 长度为 16 时,table.length - 1 = 15 ,用二进制来看,此时低 4 位全是 1,高 28 位全是 0,与 0 进行 & 运算必然为 0,因此此时 hashCode 与 “table.length - 1” 的 & 运算结果只取决于 hashCode 的低 4 位,在这种情况下,hashCode 的高 28 位就没有任何作用,并且由于 hash 结果只取决于 hashCode 的低 4 位,hash 冲突的概率也会增加。因此,在 JDK 1.8 中,将高位也参与计算,目的是为了降低 hash 冲突的概率。
红黑树与链表之前转换:
链表越来越长时会考虑二叉树中的红黑树
当链表大于8时,会转为红黑树;
当红黑树的节点个数 <= 6 时红黑树转为链表结构
JDK死循环问题:
JDK1.7之前是头插法, 有弊端:性能不好,容易形成死循环
JDK1.8是尾查法 避免死循环,
在 JDK 1.8 以前,Java 语言在并发情况下使用 HashMap 造成 Race Condition,从而导致死循环。程序经常占了 100% 的 CPU,查看堆栈,你会发现程序都 Hang 在了 “HashMap.get()” 这个方法上了,重启程序后问题消失。有人将这个问题当成一个 bug 提给了 Sun,但是 Sun 认为这并不是个 bug,因为HashMap 本来就不保证并发的线程安全性,在并发下,要用 ConcurrentHashMap 来代替。
我们知道,JDK 1.8 以前,导致死循环的主要原因是扩容后,节点的顺序会反掉,如下图:扩容前节点 A 在节点 C 前面,而扩容后节点 C 在节点 A 前面。
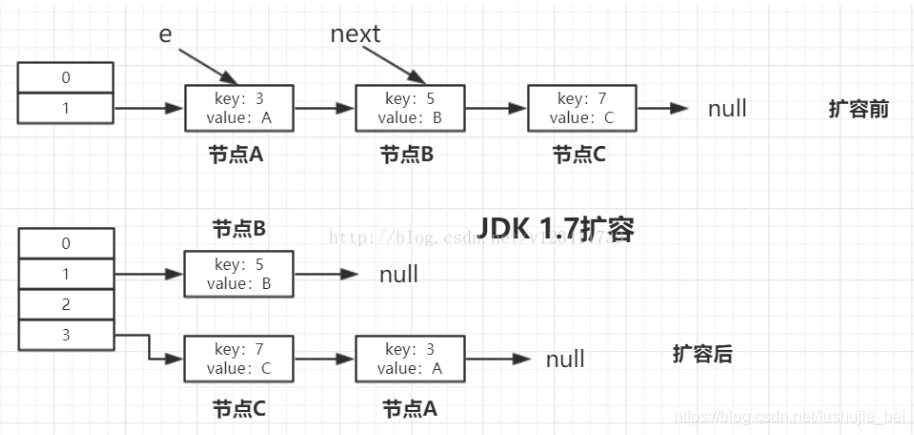
扩容:
大于扩容因子就是扩容, 扩容因子是0.75(threshold), 当执行数组大于12时,就会进行扩容
红黑树小于6时,会替换为链表
扩容时会转移数据,或者叫数据复制,有几种情况
空节点 (不迁移)
1:只存在数组( 先遍历数组)
重新计算hash值
2:红黑树
拆分打散移到新的数组中节点中
3:链表转移 (比较复杂)
1.8扩容过程:

举个例子
前提:我们假设有3个节点,节点 A,节点 B,节点 C,并且假设他们的 hash 值等于 key 值,则按上图扩容的过程模拟如下。
先看下老表和新表计算索引位置的过程:(hash 计算省略前面 28 位 0,只看最后 4 位

具体扩容过程:
第一个例子:
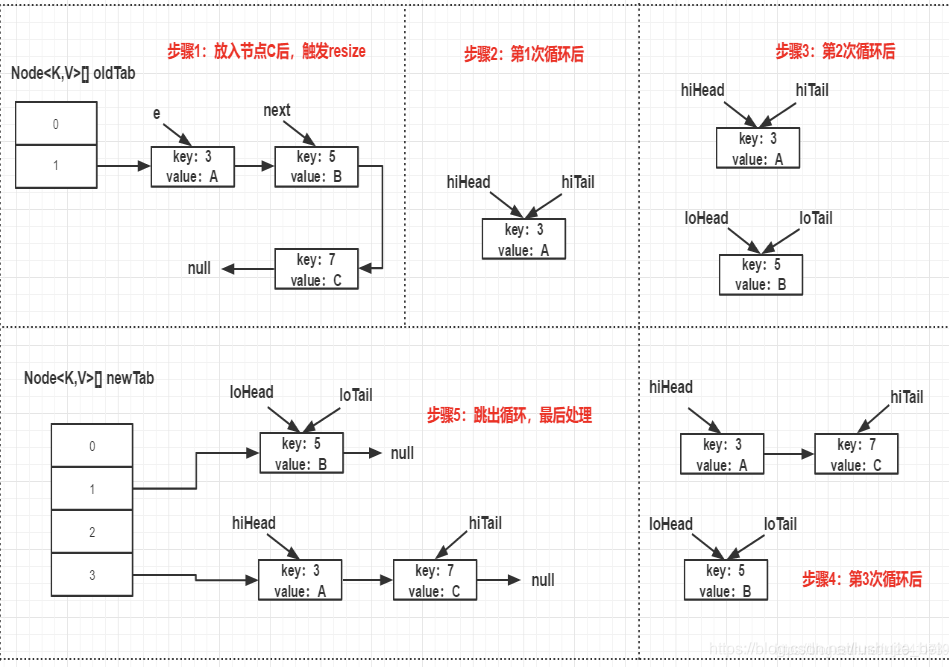
结果:可以看出,扩容后,节点 A 和节点 C 的先后顺序跟扩容前是一样的。因此,即使此时有多个线程并发扩容,也不会出现死循环的情况。当然,这仍然改变不了 HashMap 仍是非并发安全,在并发下,还是要使用 ConcurrentHashMap 来代替。
第二个例子,主要用于链表扩容:
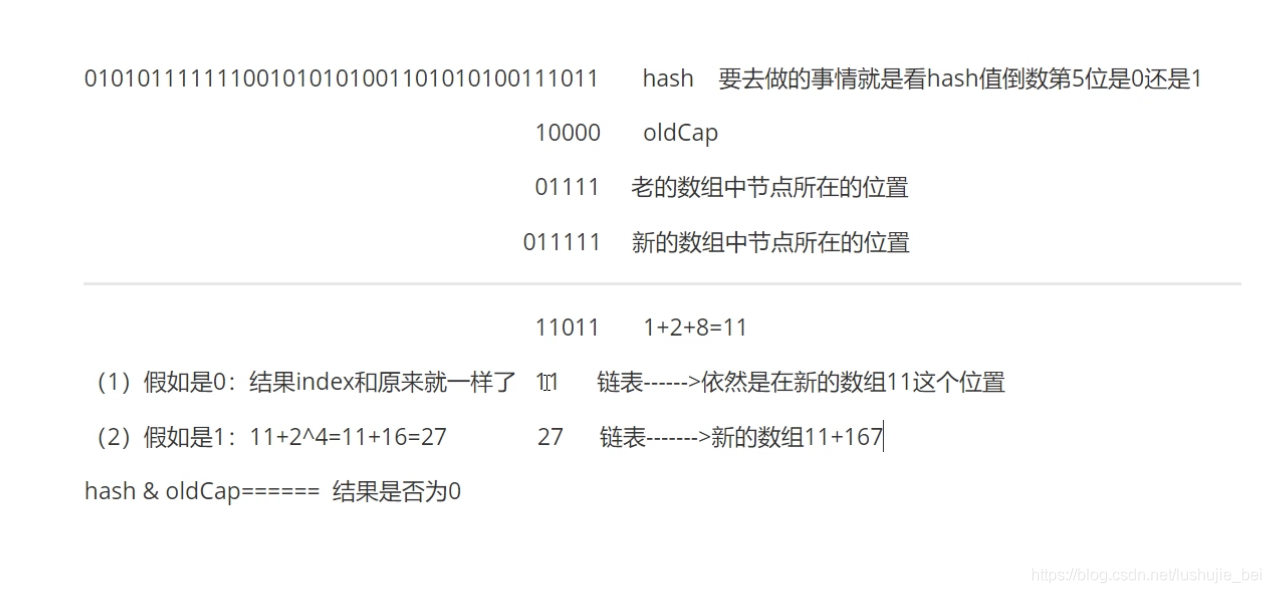
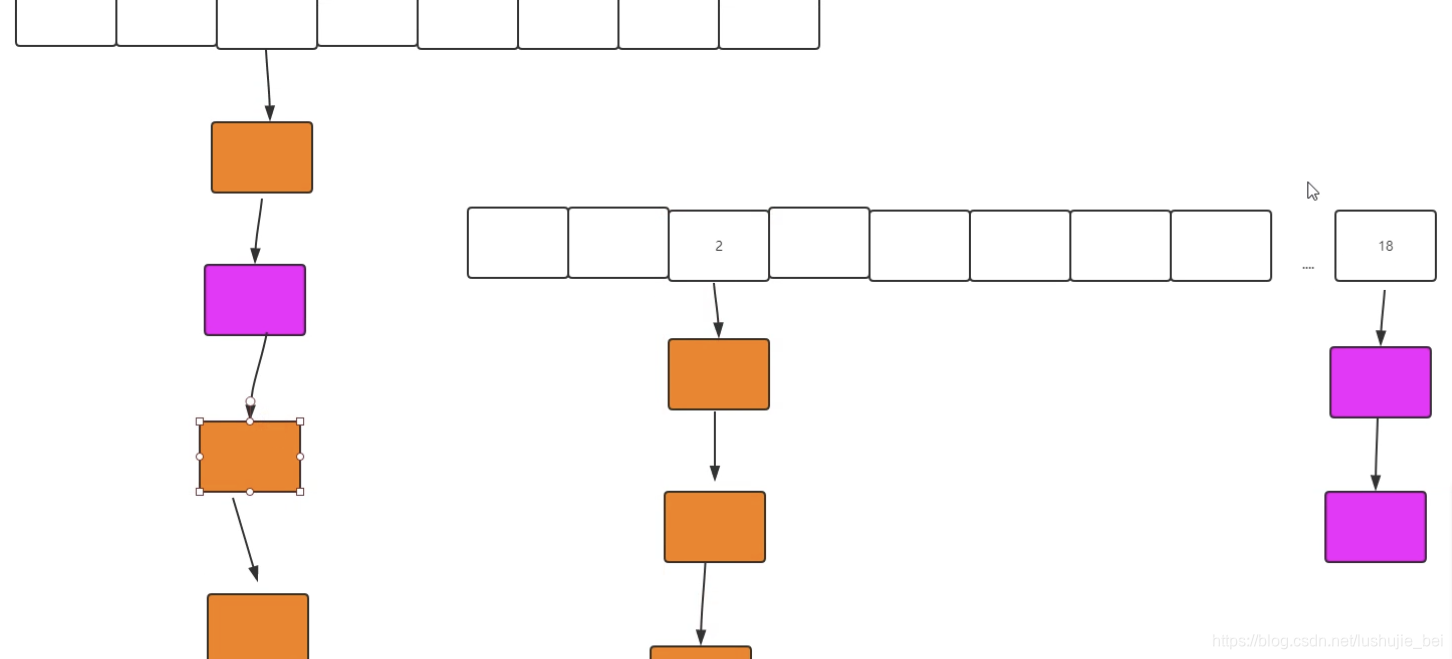
扩容之后:在原来考的数组汇总的Node节点,此时到新的数组中,
要么是在原来的位置(2),要么是在原来的位置 (2+16[ 2 ^ 4]=18)
总结:
HashMap 和 Hashtable 的区别
HashMap 允许 key 和 value 为 null,Hashtable 不允许。
HashMap 的默认初始容量为 16,Hashtable 为 11。
HashMap 的扩容为原来的 2 倍,Hashtable 的扩容为原来的 2 倍加 1。
HashMap 是非线程安全的,Hashtable是线程安全的。
HashMap 的 hash 值重新计算过,Hashtable 直接使用 hashCode。
HashMap 去掉了 Hashtable 中的 contains 方法。
HashMap 继承自 AbstractMap 类,Hashtable 继承自 Dictionary 类。
HashMap 总结:
1:HashMap 的底层是个Node数组(Node<K,V>[] table),在数组的具体索引位置,如果存在多个节点,则可能是以链表或者红黑树的形式存在;
2:增加,删除,查找键值对时,定位到哈希桶数组的位置是很关键的一步,源码中是通过下面3个操作来完成这一步:1)拿到 key 的 hashCode 值;2)将 hashCode 的高位参与运算,重新计算 hash 值;3)将计算出来的 hash 值与 “table.length - 1” 进行 & 运算。
3:HashMap 的默认初始容量(capacity)是 16,capacity 必须为 2 的幂次方;默认负载因子(load factor)是 0.75;实际能存放的节点个数(threshold,即触发扩容的阈值)= capacity * load factor;
4:HashMap 在触发扩容后,阈值会变为原来的 2 倍,并且会对所有节点进行重 hash 分布,重 hash 分布后节点的新分布位置只可能有两个:“原索引位置” 或 “原索引+oldCap位置”。例如 capacity 为16,索引位置 5 的节点扩容后,只可能分布在新表 “索引位置5” 和 “索引位置21(5+16)”。
5:导致 HashMap 扩容后,同一个索引位置的节点重 hash 最多分布在两个位置的根本原因是:1)table的长度始终为 2 的 n 次方;2)索引位置的计算方法为 “(table.length - 1) & hash”。HashMap 扩容是一个比较耗时的操作,定义 HashMap 时尽量给个接近的初始容量值。
6:HashMap 有 threshold 属性和 loadFactor 属性,但是没有 capacity 属性。初始化时,如果传了初始化容量值,该值是存在 threshold 变量,并且 Node 数组是在第一次 put 时才会进行初始化,初始化时会将此时的 threshold 值作为新表的 capacity 值,然后用 capacity 和 loadFactor 计算新表的真正 threshold 值。
7:当同一个索引位置的节点在增加后达到 9 个时,并且此时数组的长度大于等于 64,则会触发链表节点(Node)转红黑树节点(TreeNode),转成红黑树节点后,其实链表的结构还存在,通过 next 属性维持。链表节点转红黑树节点的具体方法为源码中的 treeifyBin 方法。而如果数组长度小于64,则不会触发链表转红黑树,而是会进行扩容。
8:当同一个索引位置的节点在移除后达到 6 个时,并且该索引位置的节点为红黑树节点,会触发红黑树节点转链表节点。红黑树节点转链表节点的具体方法为源码中的 untreeify 方法。
9:HashMap 在 JDK 1.8 之后不再有死循环的问题,JDK 1.8 之前存在死循环的根本原因是在扩容后同一索引位置的节点顺序会反掉。
10:HashMap 是非线程安全的,在并发场景下使用 ConcurrentHashMap 来代替。
11:业务场景使用,加载map进行缓存的一个查询, 策略模式中用到 获取(key,value)的值,