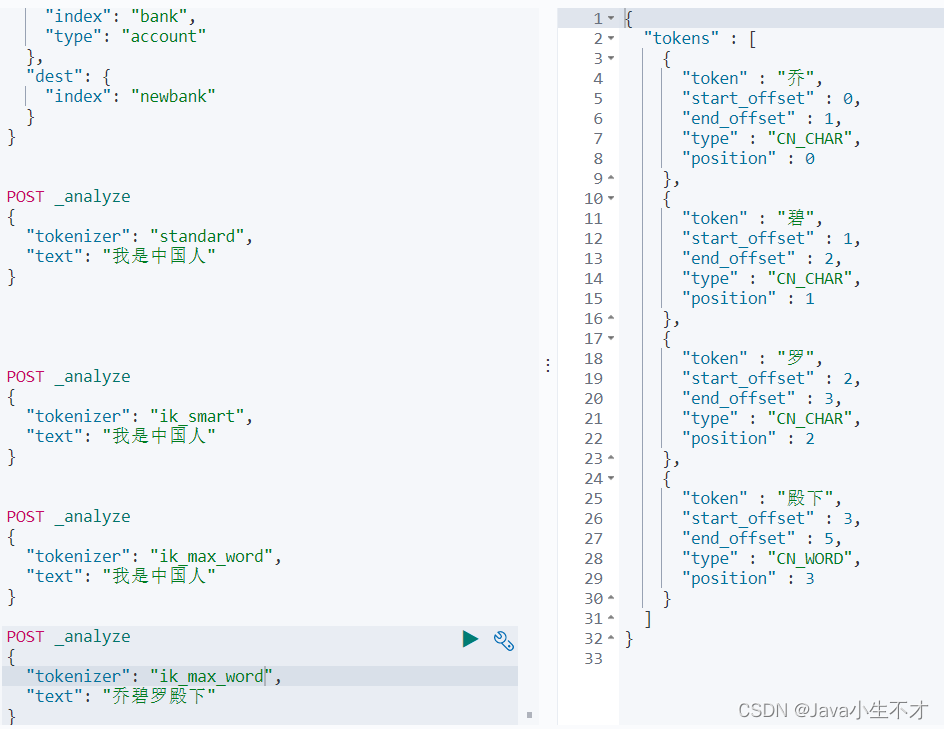
在实际分词中有些分词并不能出现我们预期的分词结果,因此我们可以使用自定义词库
1.安装nginx
在mydata下创建目录
mkdir nginx
启动实例
docker run -p 80:80 --name nginx

2.拷贝nginx的配置文件
将nginx容器内的配置文件拷贝到当前目录
docker container cp nginx:/etc/nginx .
注意nginx后有空格和点
3.删除原有nginx
终止原容器
docker stop nginx
移除原容器
docker rm nginx
将nginx改名为conf
mv nginx conf

4.再装nginx
创建目录,并将conf移到nginx下
mkdir nginx
mv conf nginx/
创建新的nginx
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10

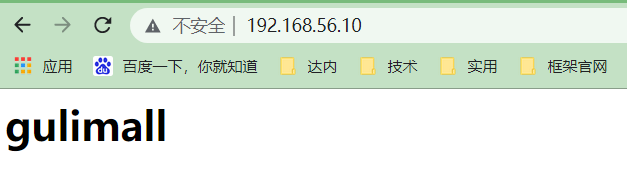
编写index.html
vi index.html
5.自定义词库
创建es目录
mkdir es
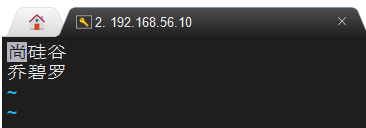
自定义词库
vi fenci.txt

6.配置远程词库
cd /mydata/
cd elasticsearch/
cd plugins/
cd ik/
cd config/

编辑 IKAnalyyzer.cfg.xml配置远程词库的地址
vi IKAnalyzer.cfg.xml

重启es
docker restart elasticsearch

7.测试
POST _analyze
{
"tokenizer": "ik_max_word",
"text": "乔碧罗殿下"
}

版权声明:本文为qq_41596346原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。