java

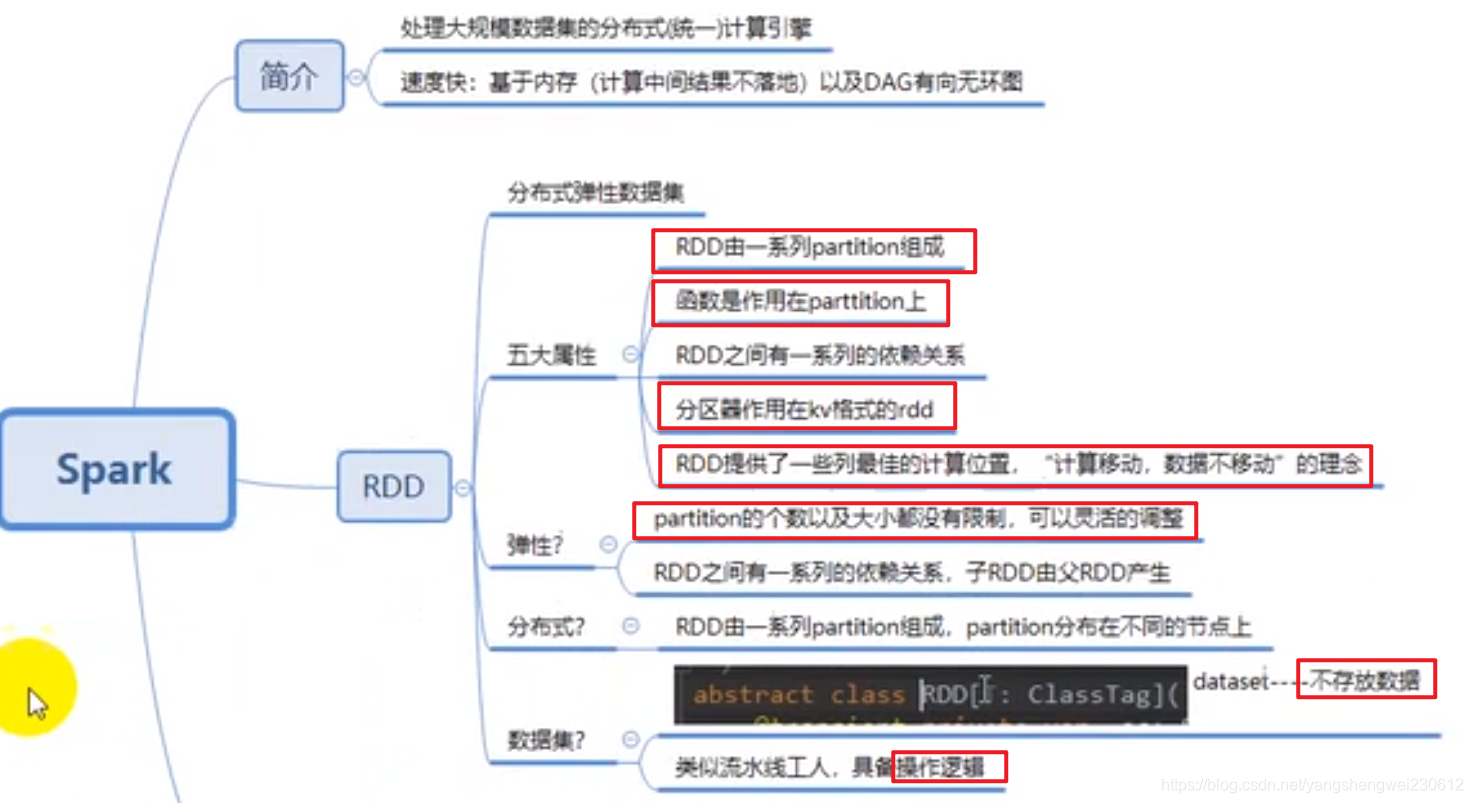
spark简介

DAG:先看到行动算子,再画流程图(有向无环图),再计算
Spark 与 MapReduce 的区别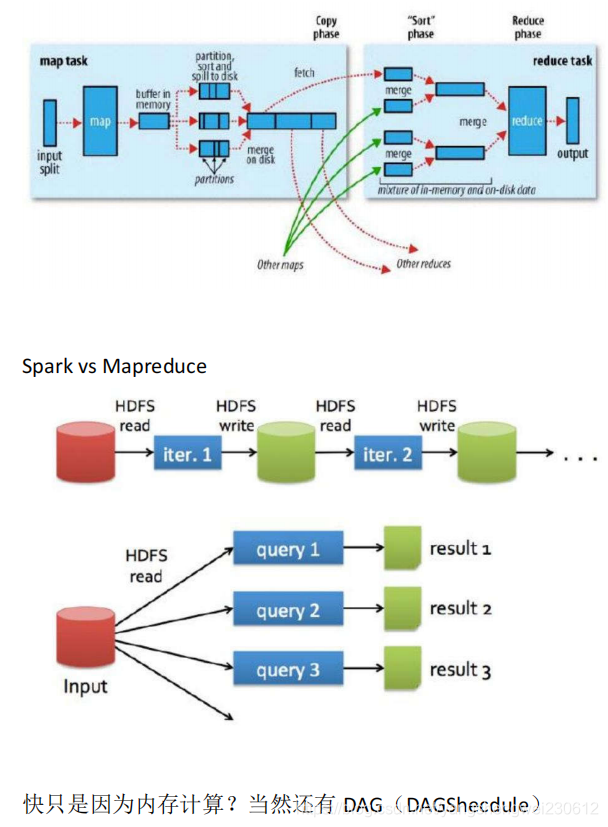


RDD不存数据,存储的是计算逻辑
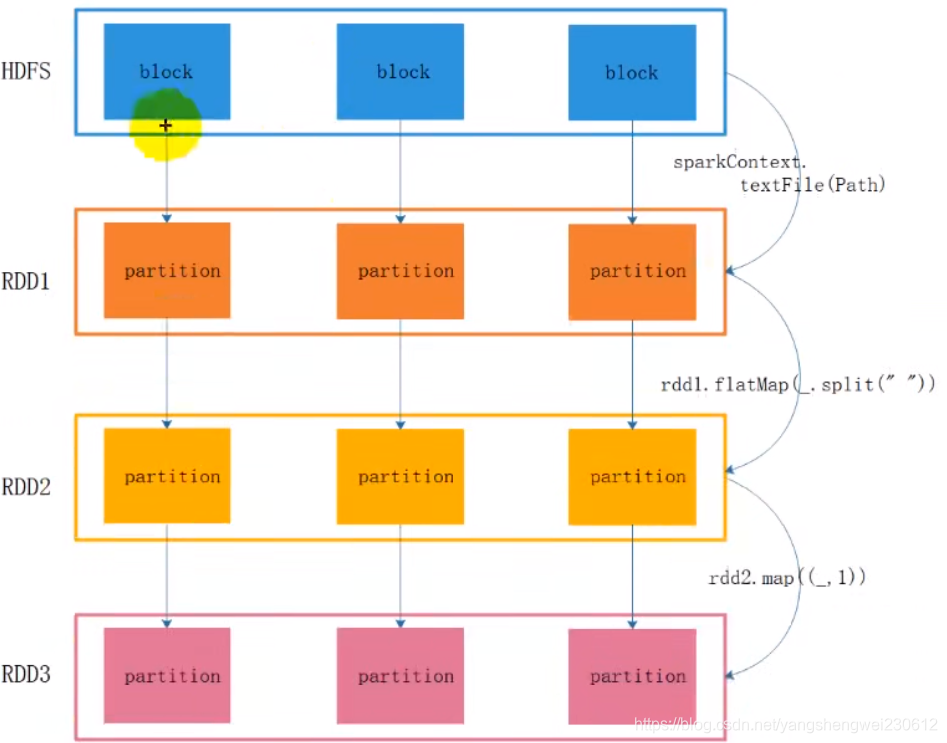




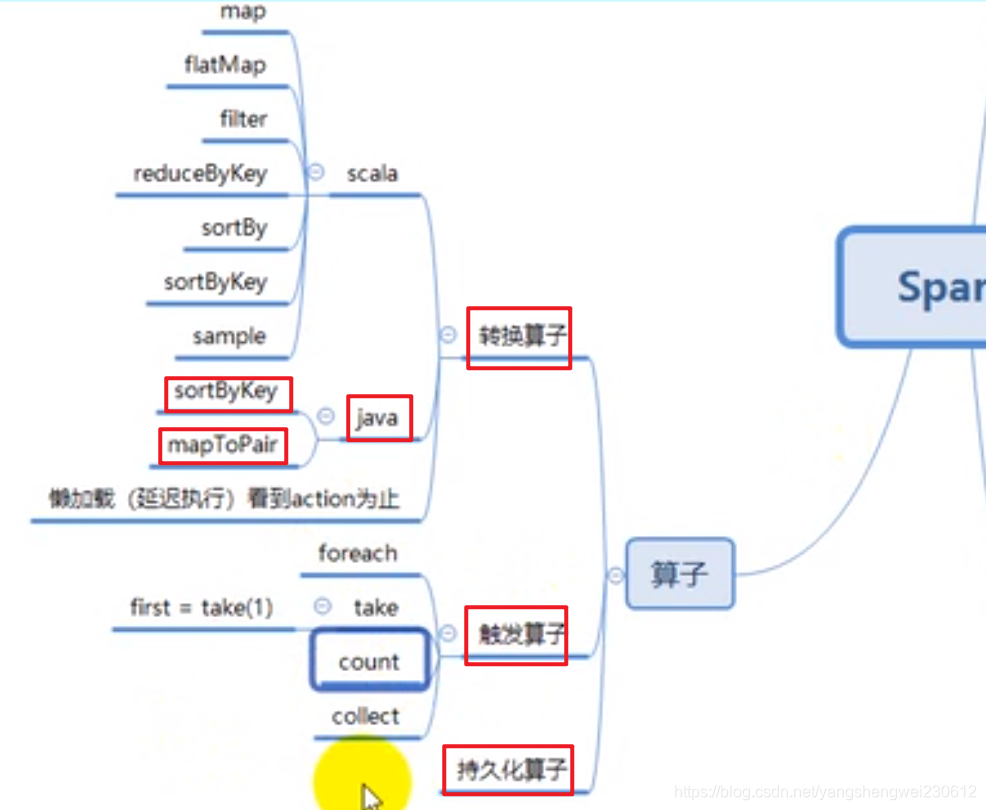
4. Transformations 转换算子






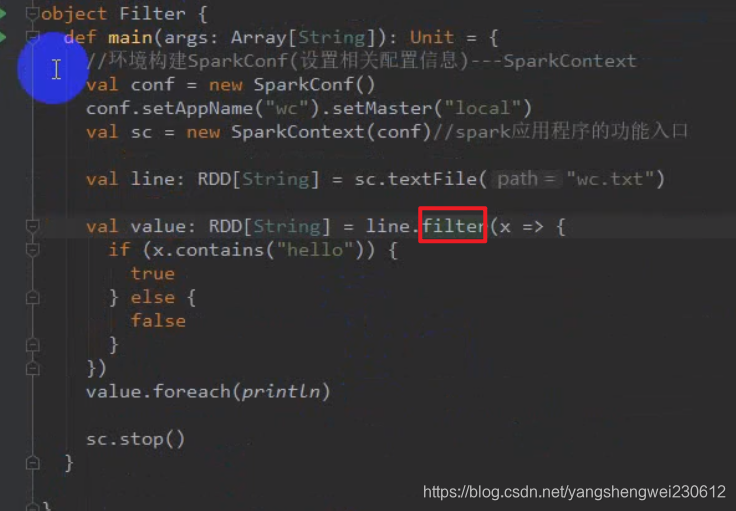

java 排序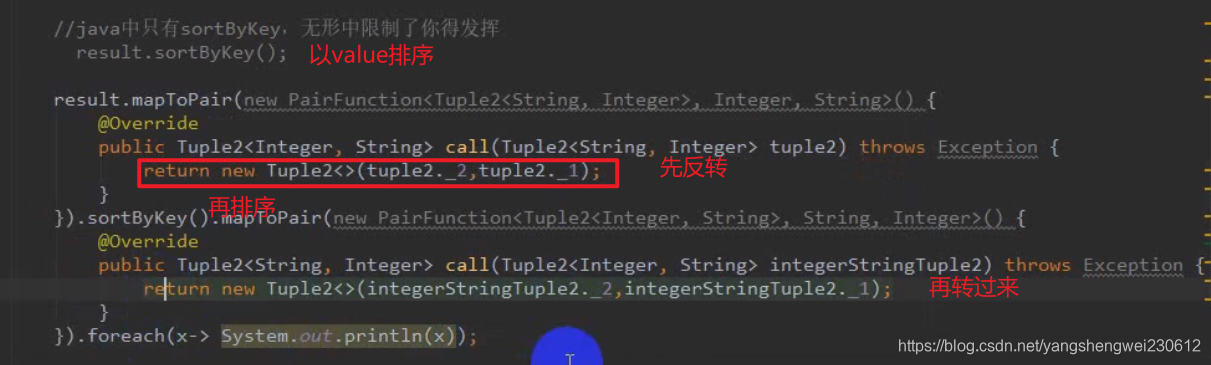

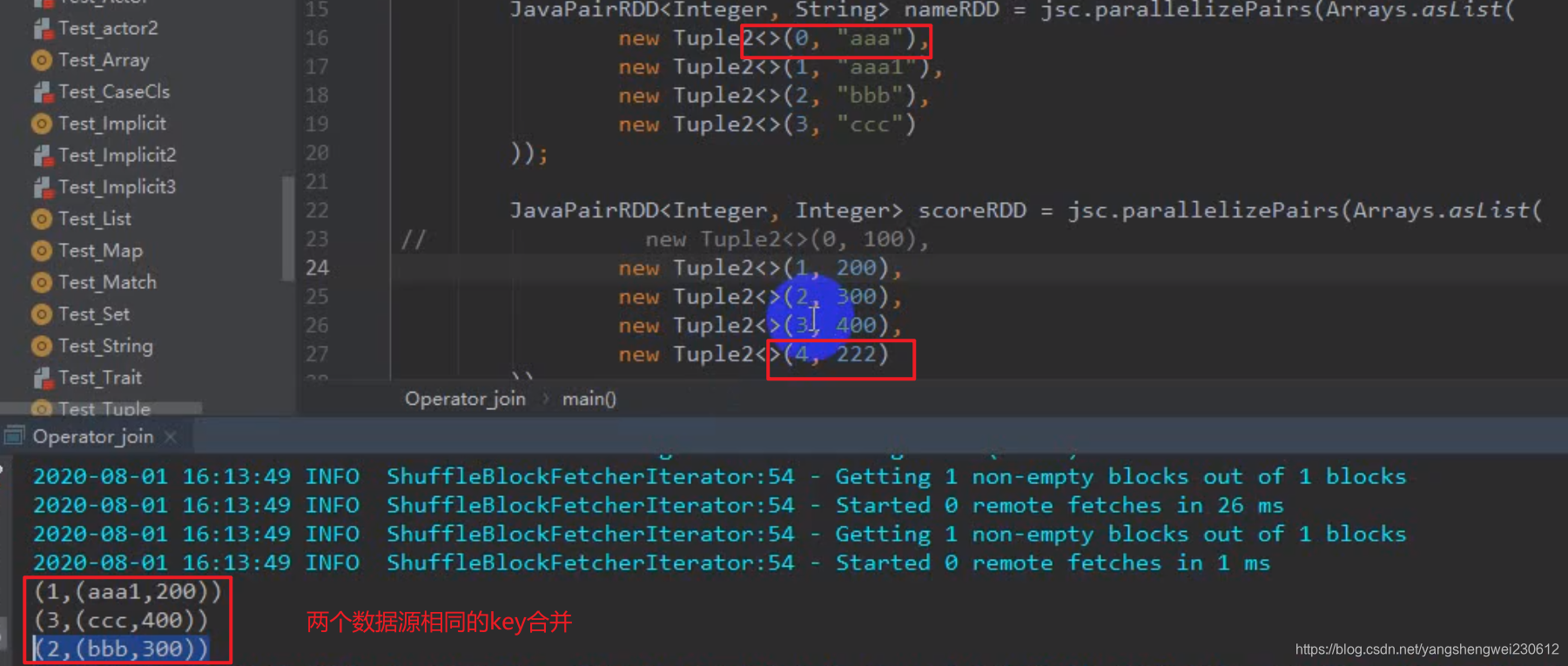
join
join只join相同key下的vale,所有join的分区都是跟着父rdd的最大分数走,及两个rdd jion,join后的rdd分区为两个父rdd分区数大的分区数
JavaPairRDD<Integer, String> nameRDD = sc.parallelizePairs(Arrays.asList(
new Tuple2<Integer, String>(0, "aa"),
new Tuple2<Integer, String>(1, "a"),
new Tuple2<Integer, String>(2, "b"),
new Tuple2<Integer, String>(3, "c")
));
JavaPairRDD<Integer, Integer> scoreRDD = sc.parallelizePairs(Arrays.asList(
new Tuple2<Integer, Integer>(1, 100),
new Tuple2<Integer, Integer>(2, 200),
new Tuple2<Integer, Integer>(3, 300),
new Tuple2<Integer, Integer>(4, 400)
));
JavaPairRDD<Integer, Tuple2<String, Integer>> join = nameRDD.join(scoreRDD);
rightOuterJoin


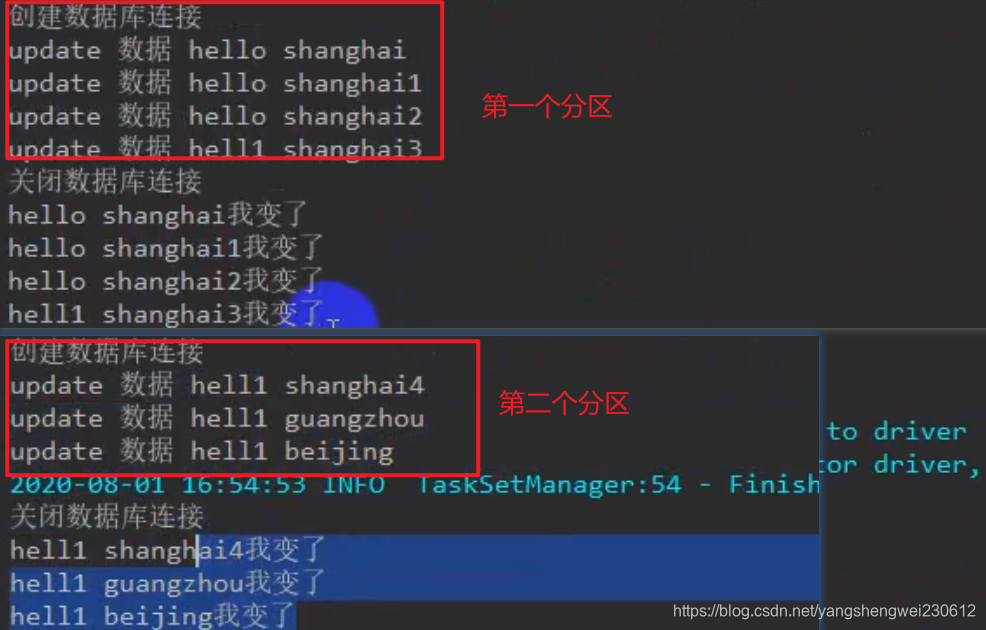
mapParition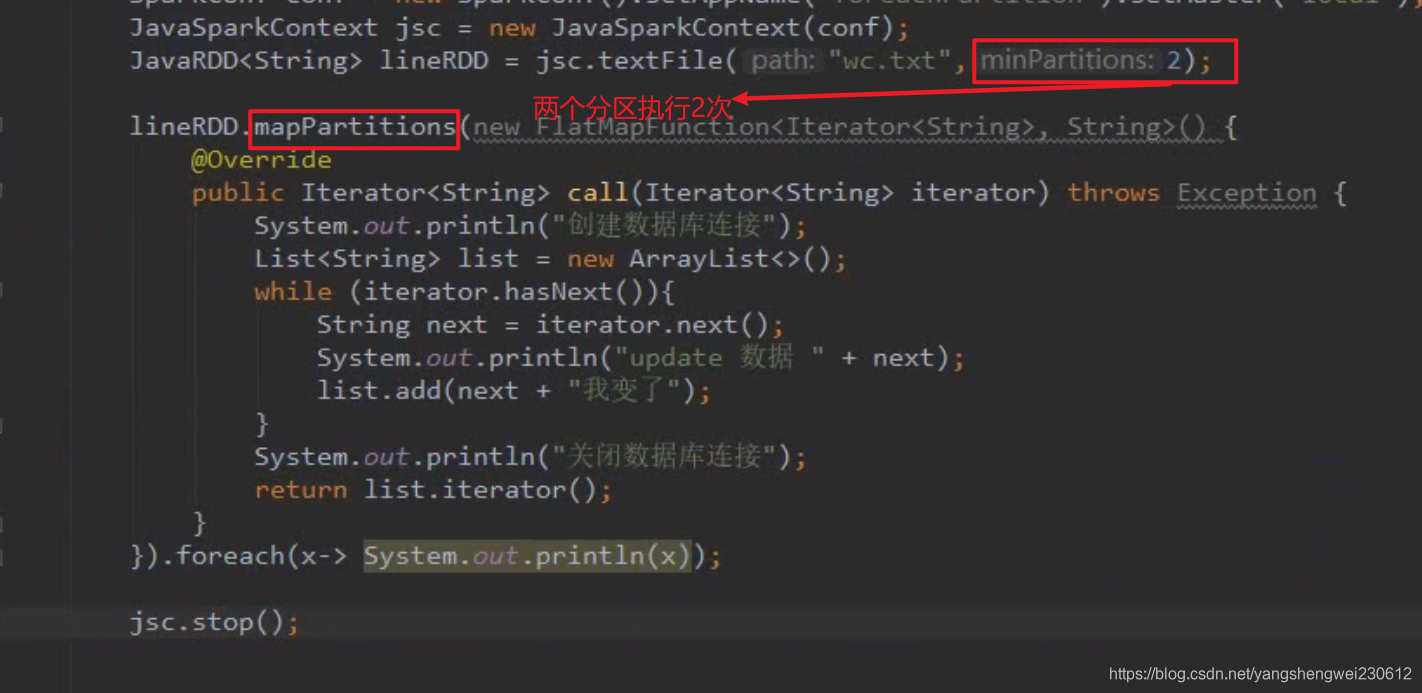
distance 去重
java 代码自己实现distinct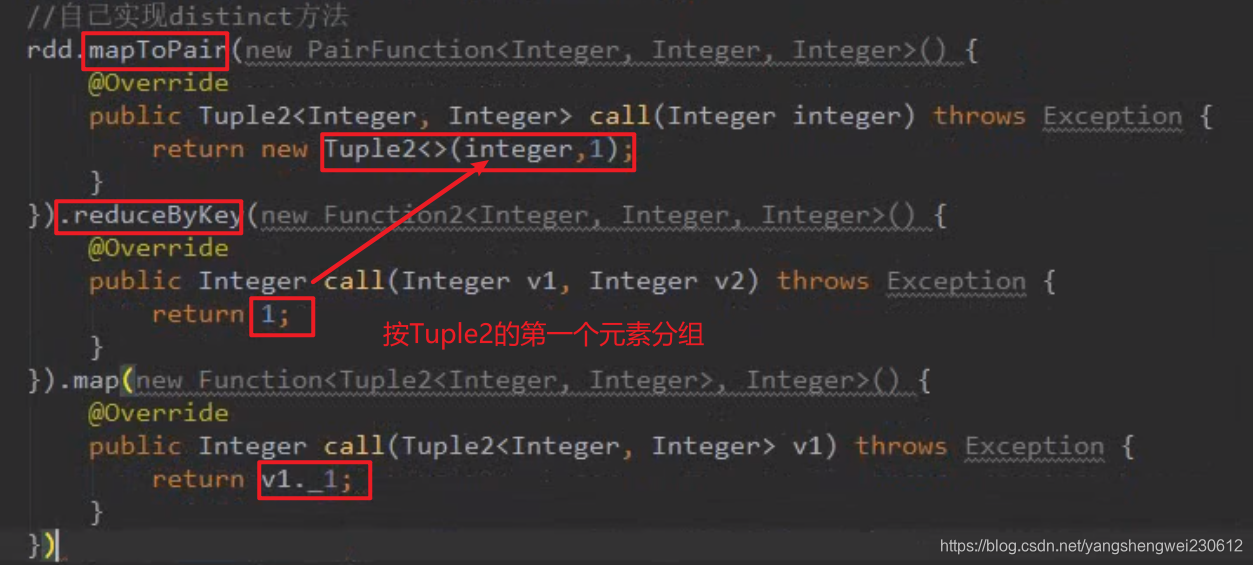

mapPartitionWithIndex
自已知道数据来自哪个分区
* coalesce减少分区
* 第二个参数是减少分区的过程中是否产生shuffle,true是产生shuffle,false是不产生shuffle,默认是false.
* 如果coalesce的分区数比原来的分区数还多,第二个参数设置false,即不产生shuffle,不会起作用。
* 如果第二个参数设置成true则效果和repartition一样,即coalesce(numPartitions,true) = repartition(numPartitions)
过滤操作之后减少分区


5. Action 行动算子




foreachPartition和 mapParition一样都是以分区为单位进行计算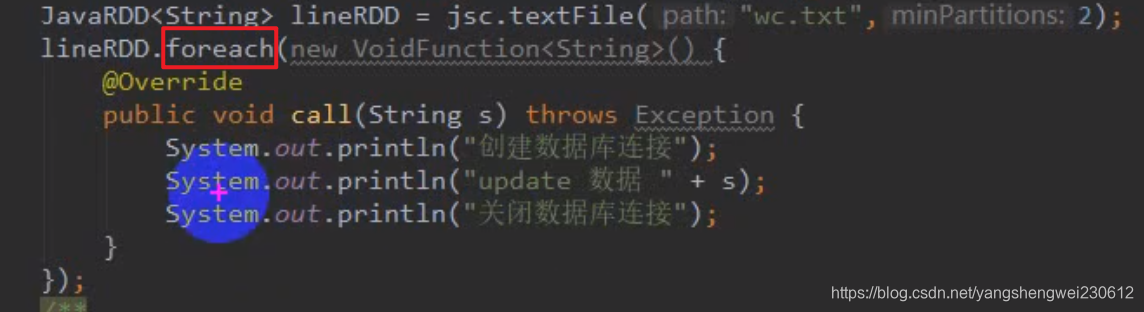
结果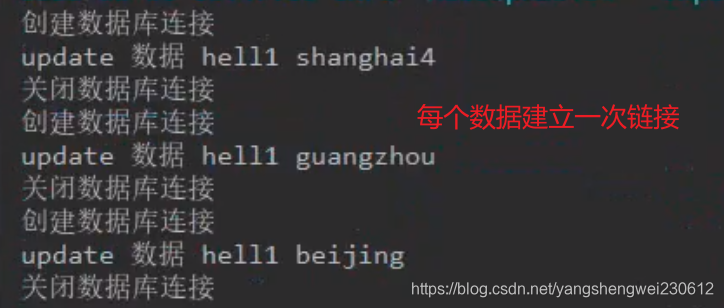
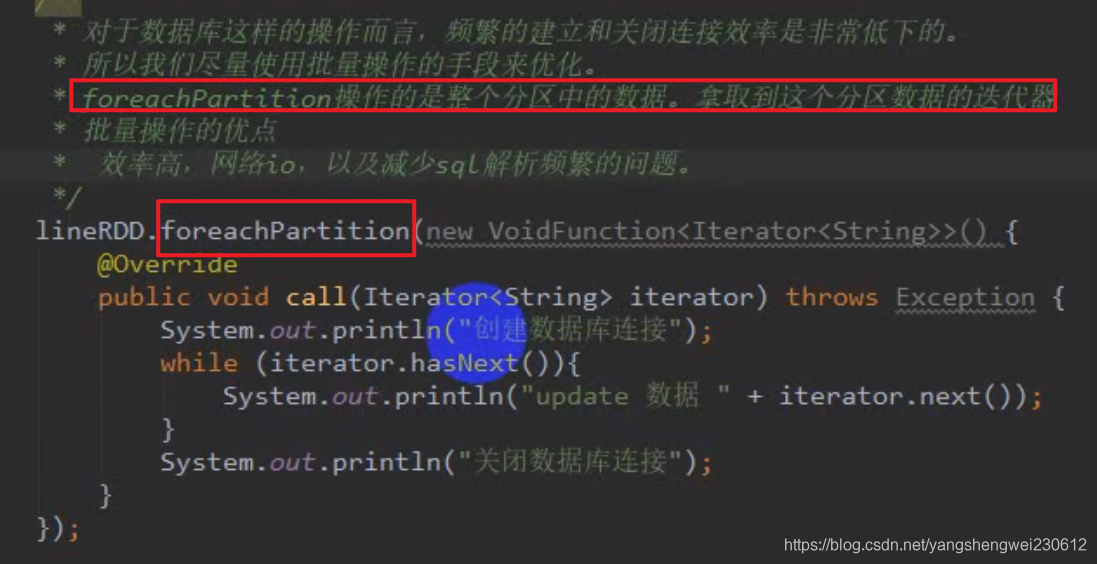
结果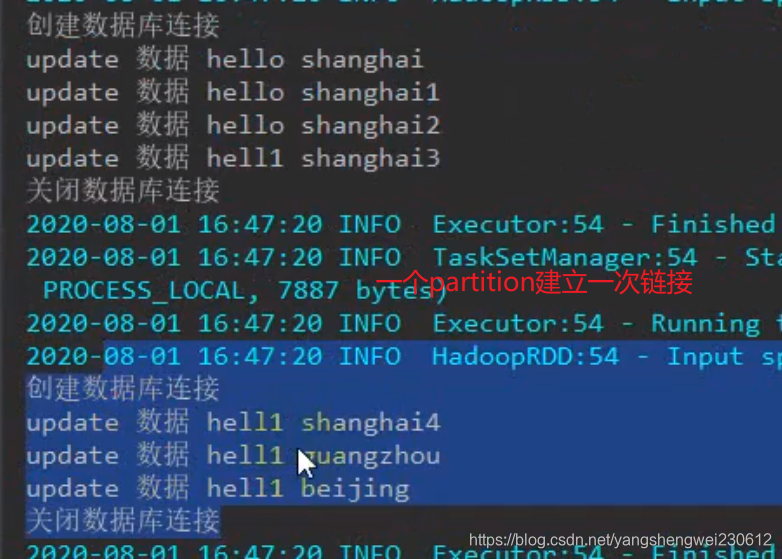

reduce 可以做用在不是看k v格式的RDD
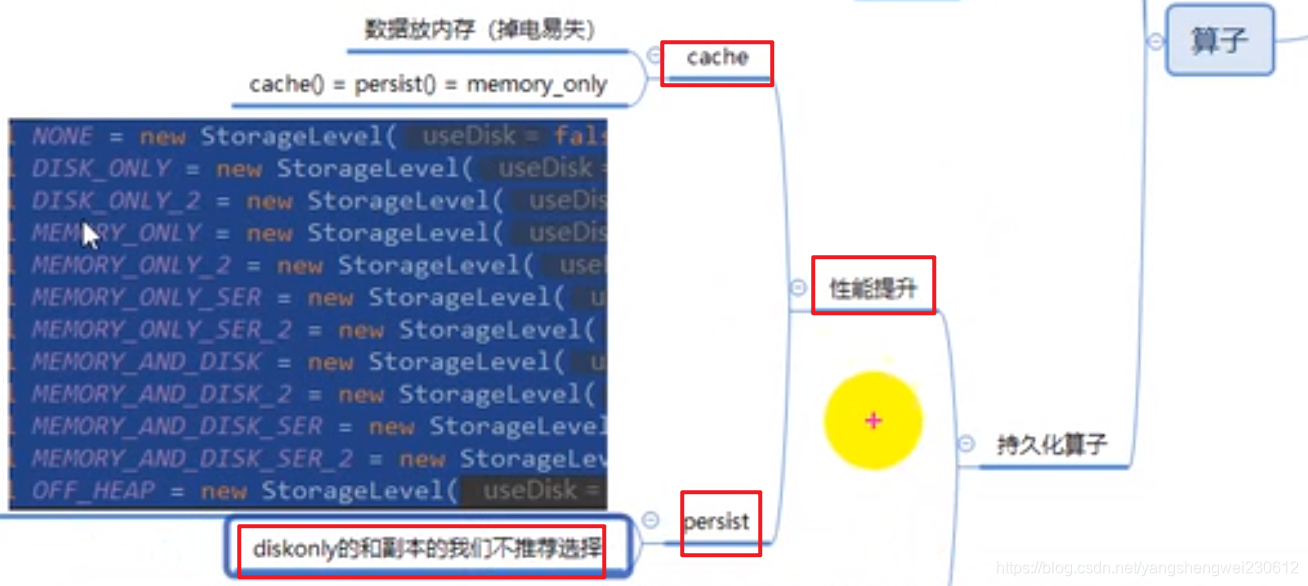
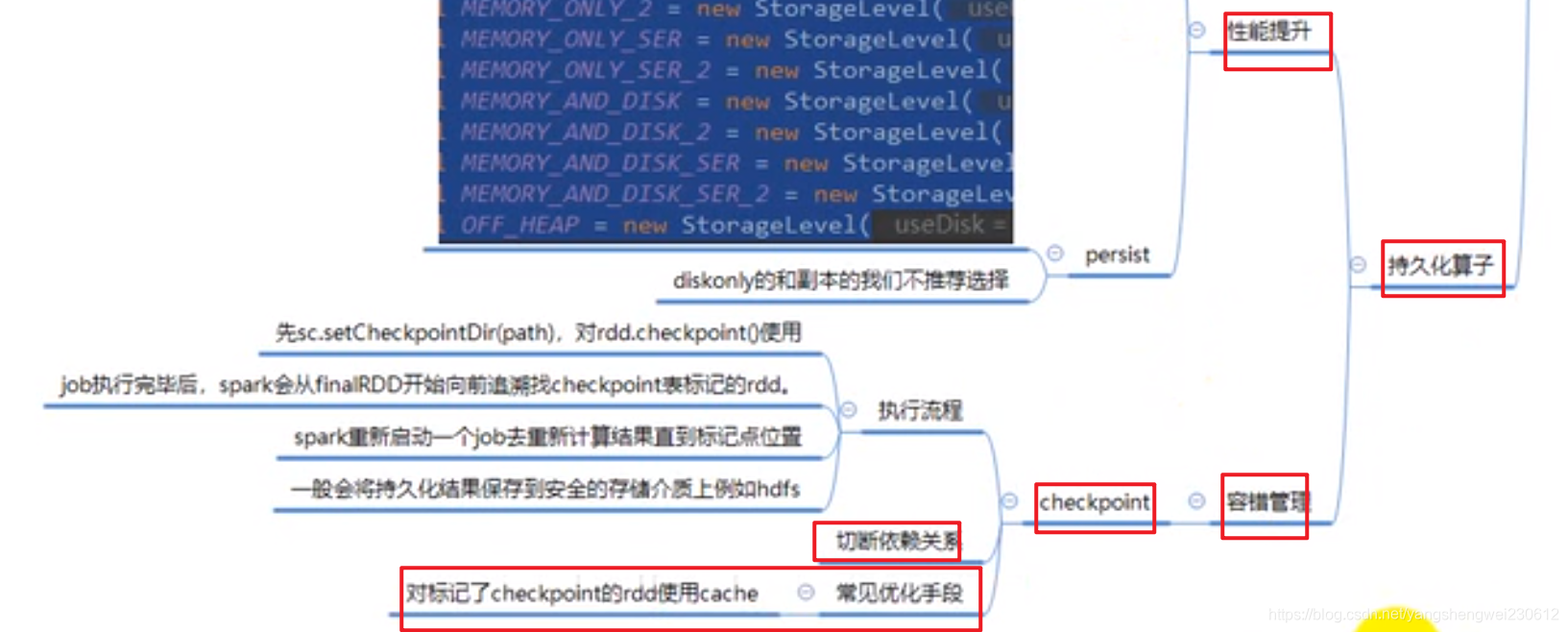
6. 控制算子


cache

测试代码:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class CacheTest {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("CacheTest");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./data/NASA_access_log_Aug95");
lines = lines.cache();
long startTime = System.currentTimeMillis();
long count = lines.count();
long endTime = System.currentTimeMillis();
System.out.println("共"+count+ "条数据,"+"初始化时间+cache时间+计算时间="+
(endTime-startTime));
long countStartTime = System.currentTimeMillis();
long countrResult = lines.count();
long countEndTime = System.currentTimeMillis();
System.out.println("共"+countrResult+ "条数据,"+"计算时间="+ (countEndTime-
countStartTime));
jsc.stop();
}
}
persist:

cache 和 persist 的注意事项:
checkpoint
cache和persist是为了提高性能的,checkpoint是为了容错的。


SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("checkpoint");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setCheckpointDir("./checkpoint");
JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3));
parallelize.checkpoint();
parallelize.count();
sc.stop();
3.集群搭建
一个人行动算子对应一个job,一个Job中有多个task一个task对应一个partition,partiiton数就是所谓并行度,partiiton分区在不同计算节点计算,不同的数据但是相同的逻辑及相同的task。
3.0.Spark-Submit 提交参数




3.1Standalone 模式两种提交任务方式
Standalone 模式两种提交任务方式
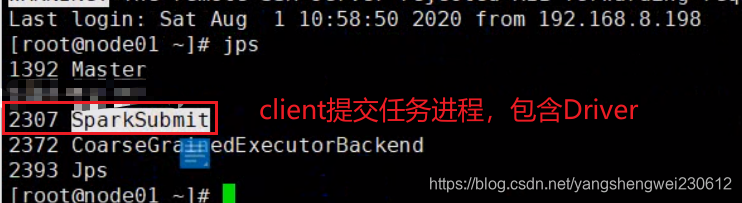
1.Standalone-client 模式提交任务方式
提交命令
不指定默认是client模式
/spark-submit
--master spark://node1:7077
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
1000
或者
./spark-submit
--master spark://node1:7077
--deploy-mode client
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100

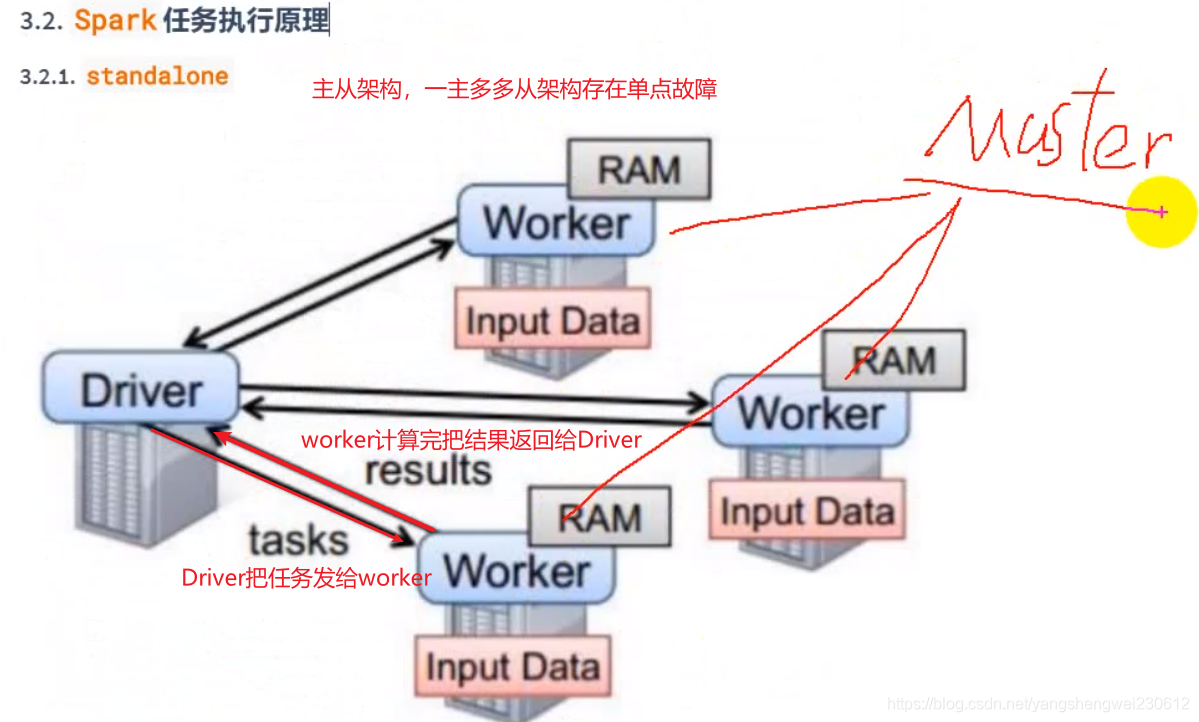
执行原理图解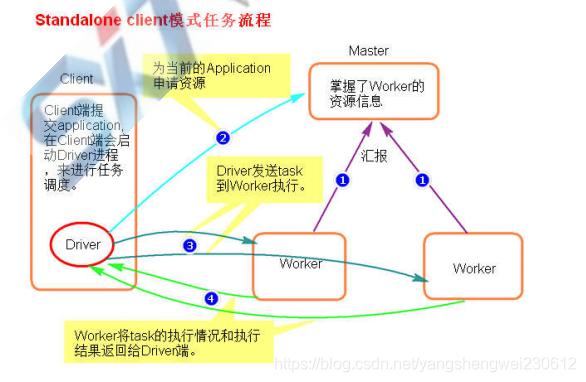
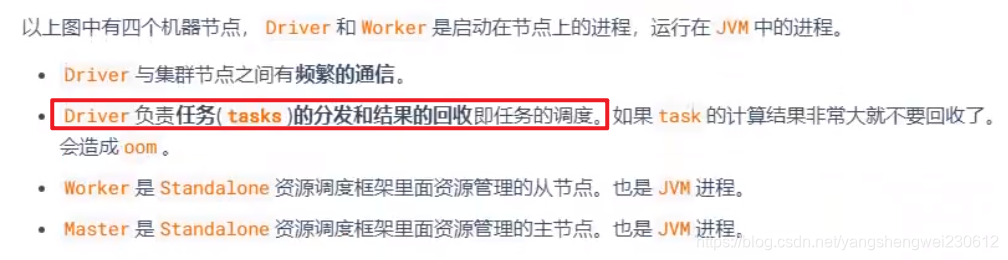
提交一个任务就会在client节点启动一个对应Driver

2. Standalone-cluster模式 提交任务方式
提交命令
./spark-submit
--master spark://node1:7077
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100

执行原理图解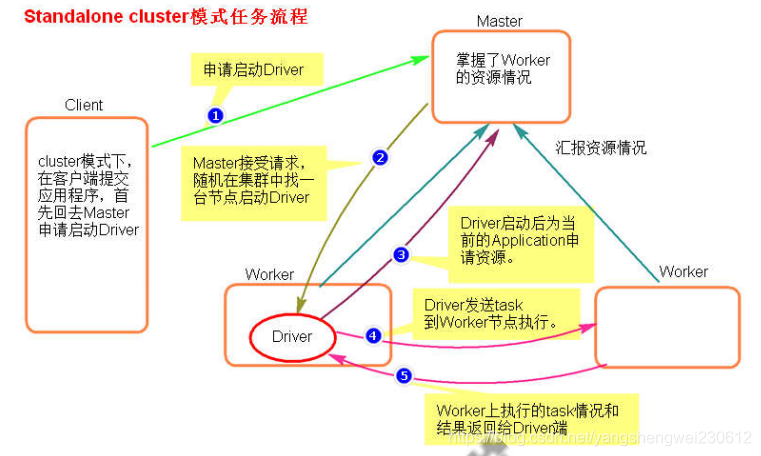
提交一个任务就会在集群中的随机一个节点启动一个对应Driver

3.2. Yarn 模式两种提交任务方式
1.yarn-client 提交任务方式
提交命令
./spark-submit
--master yarn
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100
或者
./spark-submit
--master yarn–client
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100
或者
./spark-submit
--master yarn
--deploy-mode client
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100
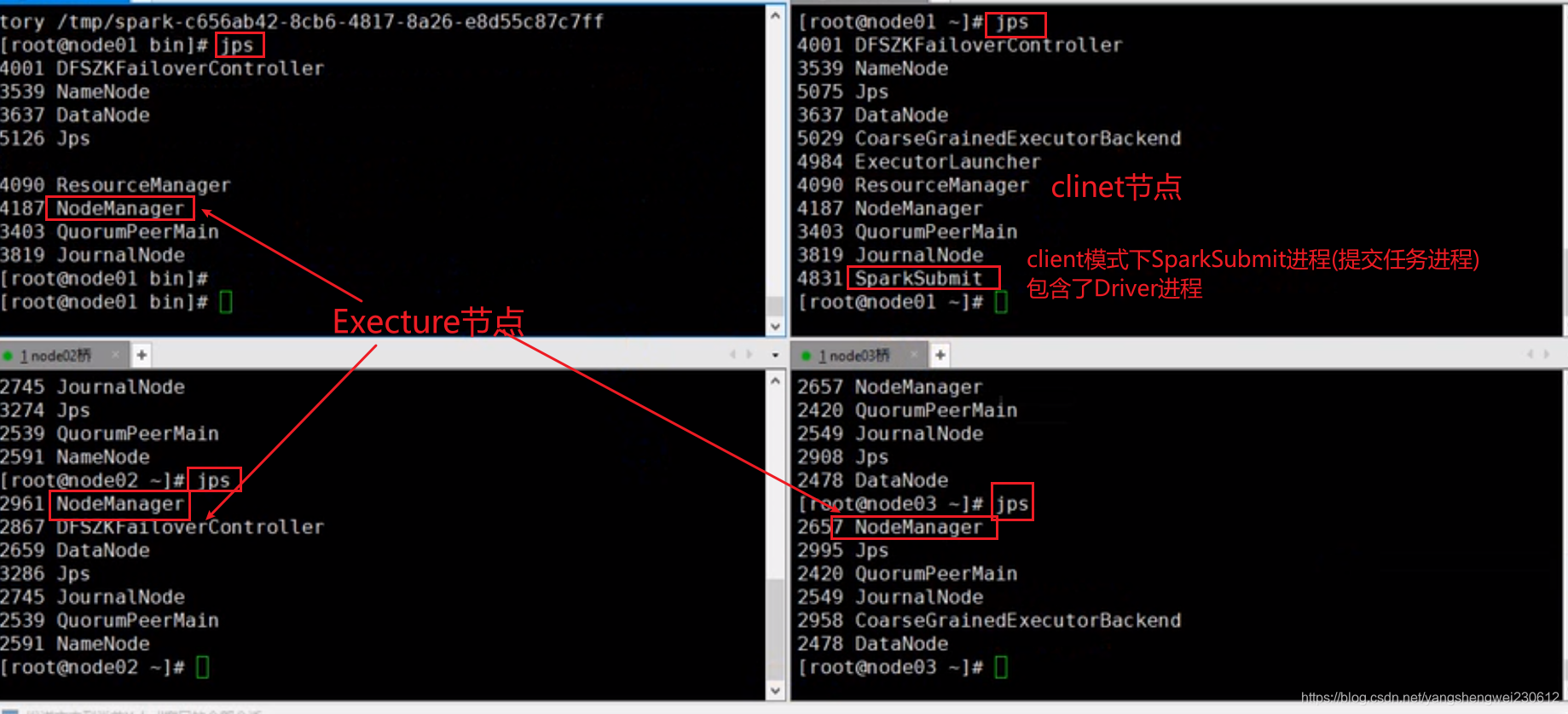
执行原理图解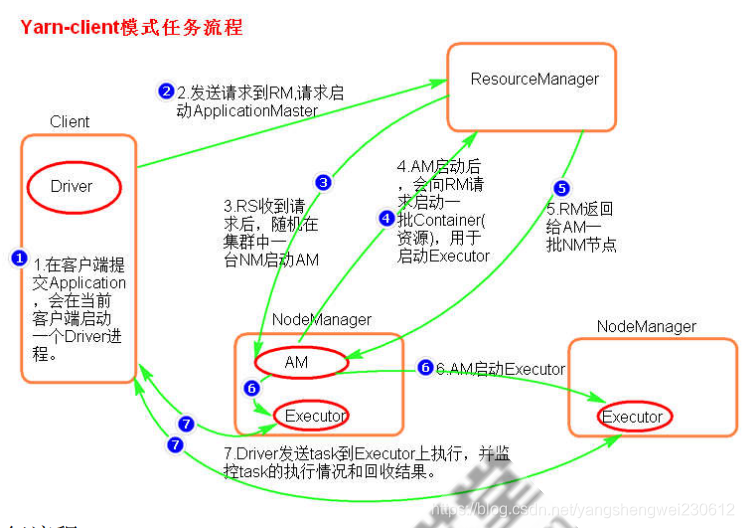
提交一个任务就会在client节点启动一个对应的ApplicationMaster和Driver


2. yarn-cluster 提交任务方式
提交命令
./spark-submit
--master yarn
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100
或者
./spark-submit
--master yarn-cluster
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.2.1.jar
100
执行原理图解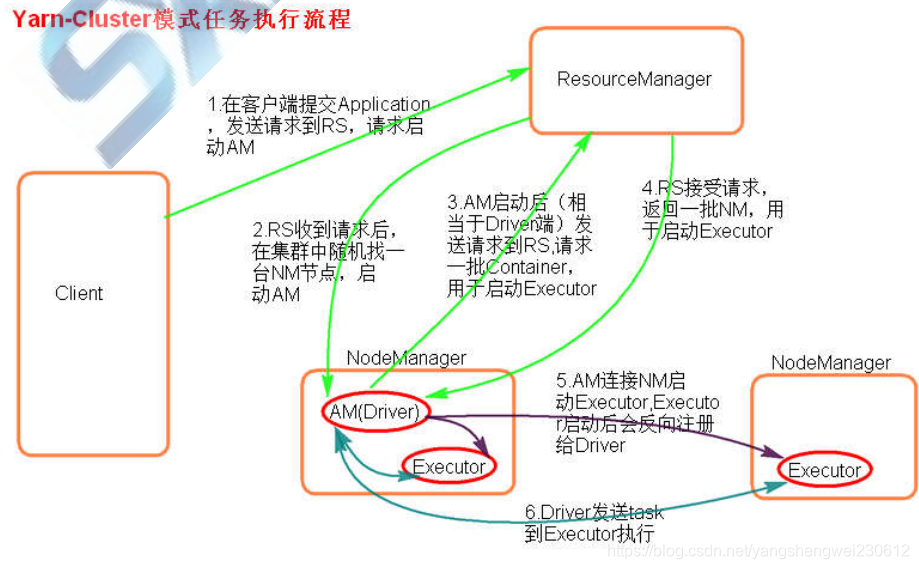
提交一个任务就会在随机的一台NodeManager节点启动一个对用的ApplicationMaster相当于Driver
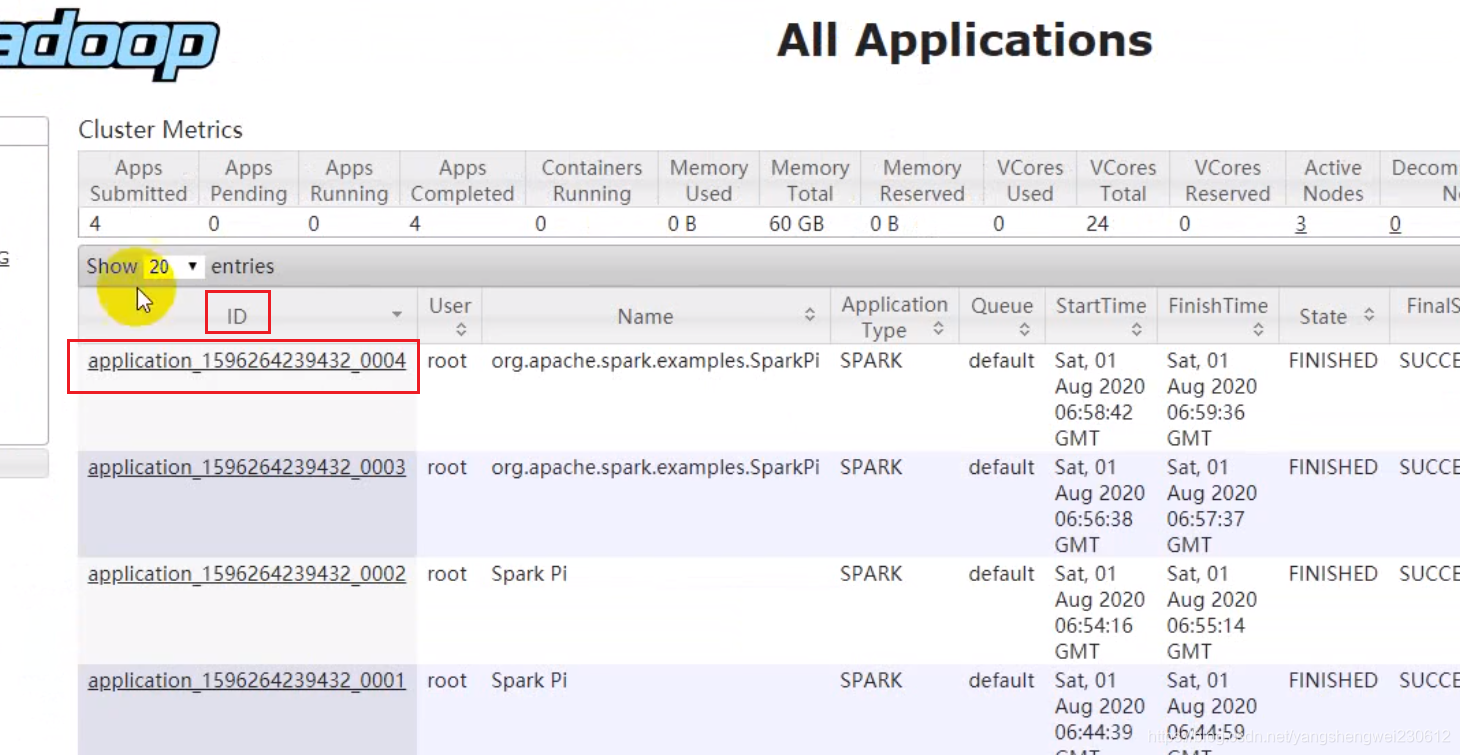
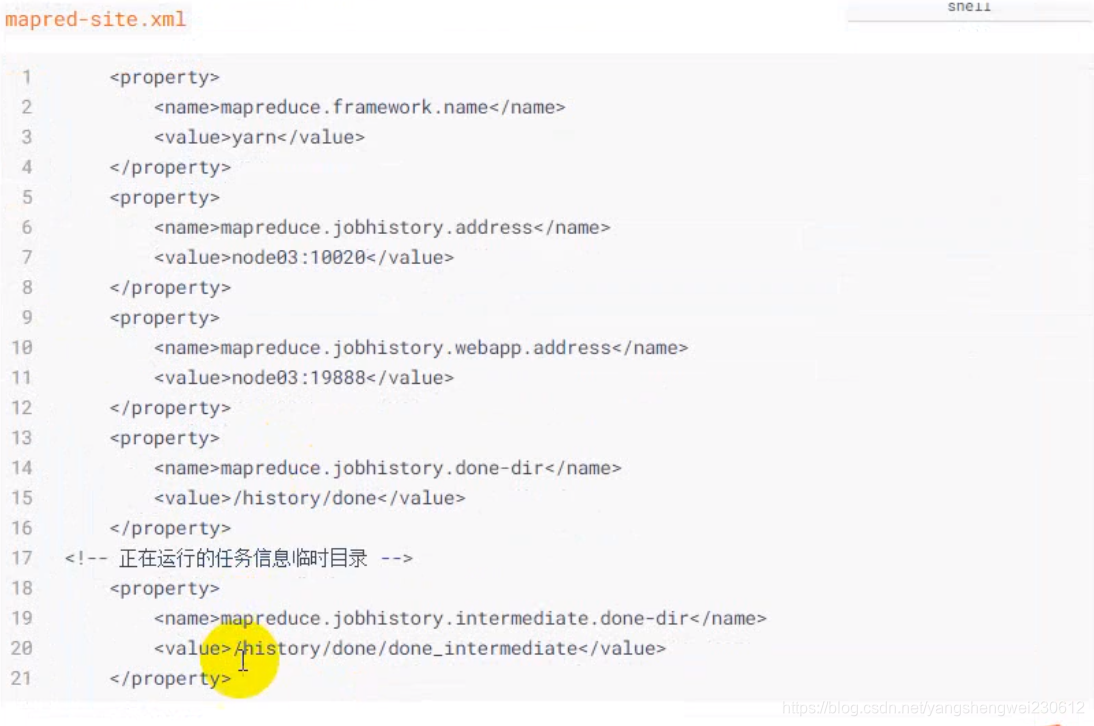
配置历史数据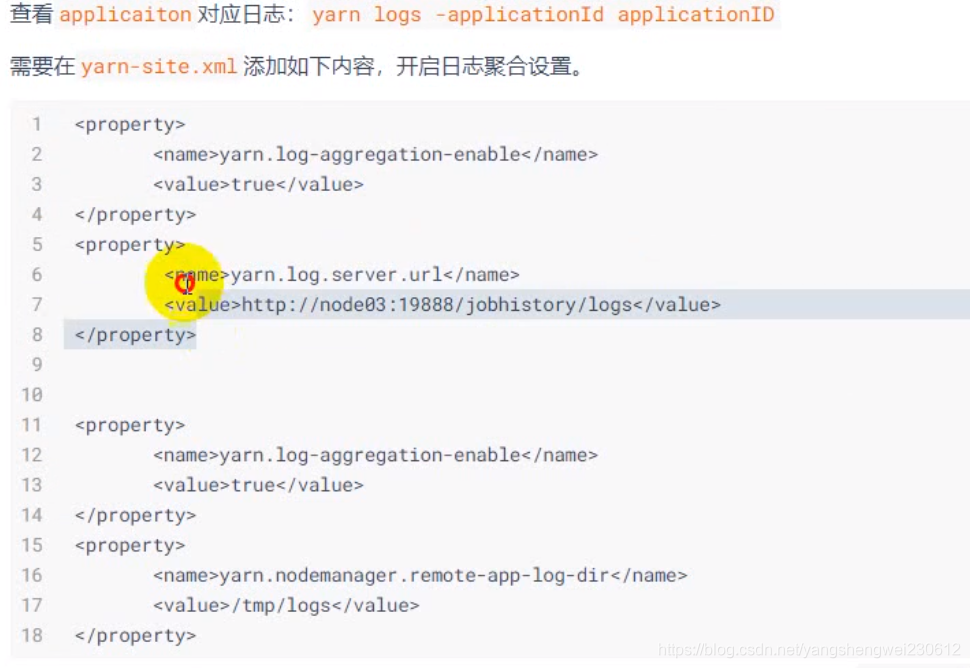
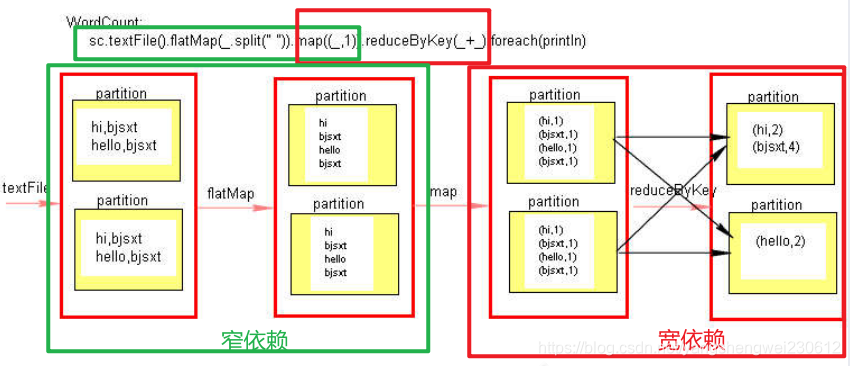
5. 窄依赖和宽依赖
一个application下可以有多个job(一个行动算子对应一个job),一个job可能分为多个stage,一个stage可能包含多个task。
job1,job2,job之间运行时串行的,及job1执行完才能执行job2
stage之间可能串行也可能并行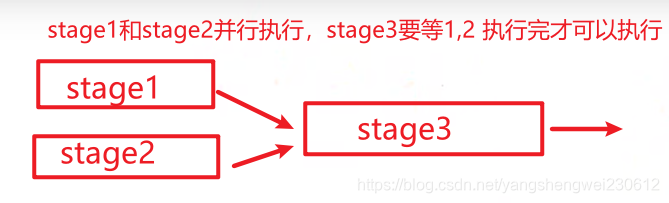
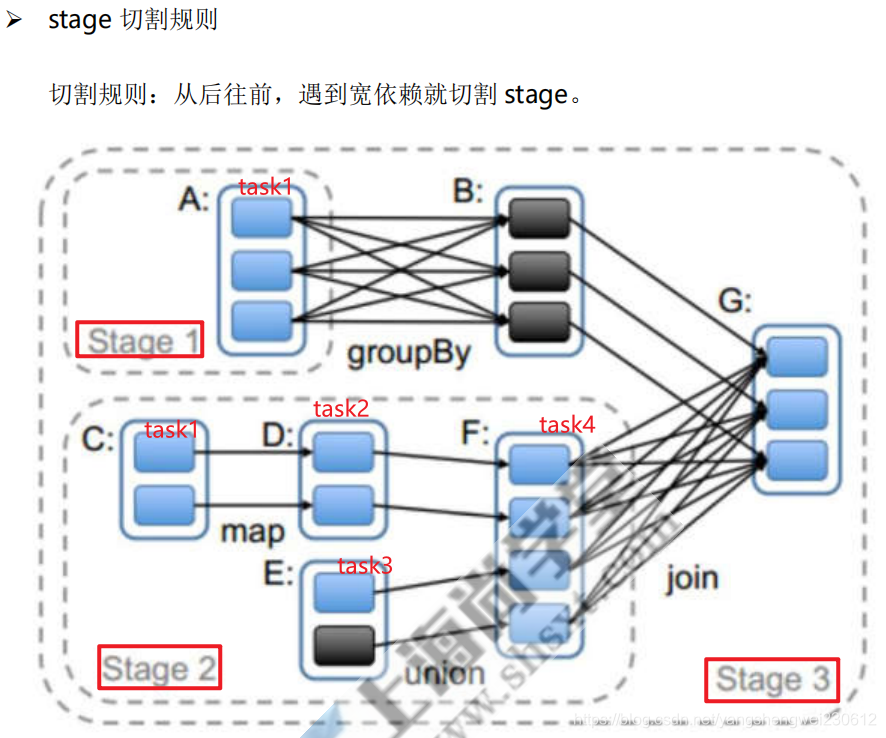


宽窄依赖图理解
RDD分区数不改变就是窄依赖,分区改变就是宽依赖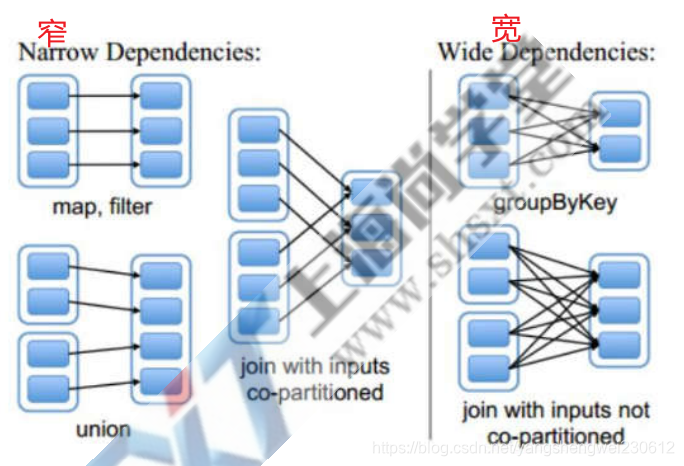
6. Stage

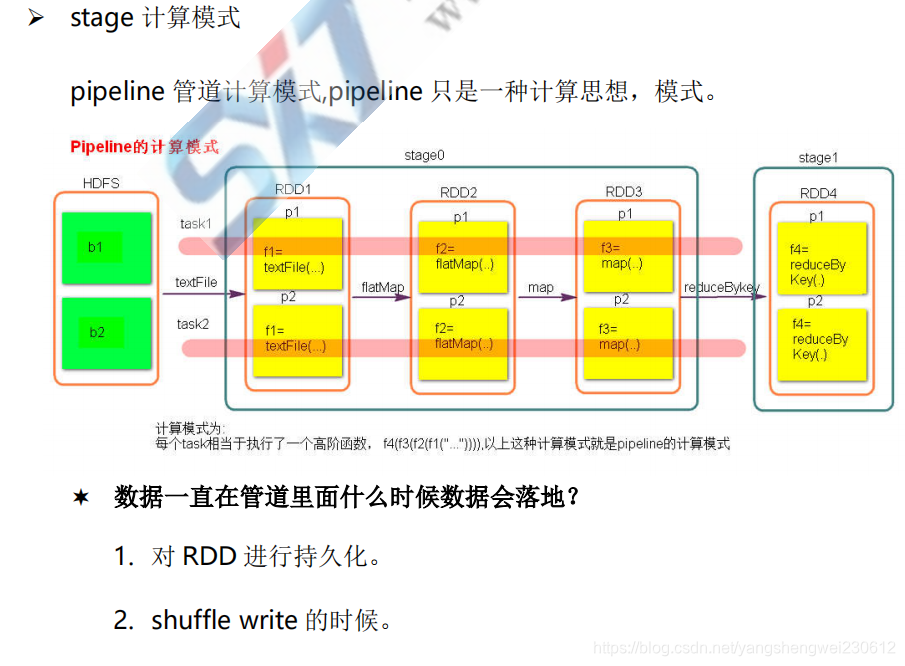
宽依赖的算子可以指定并行度(partiiton数)
val conf = new SparkConf()
conf.setMaster("local").setAppName("pipeline");
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1,2,3,4))
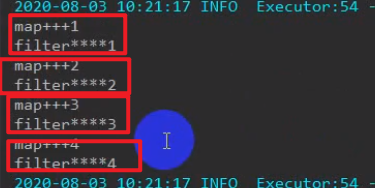
val rdd1 = rdd.map { x => {
println("map--------"+x) x
}}
val rdd2 = rdd1.filter { x => {
println("fliter********"+x)
true
} }
rdd2.collect()
sc.stop()
7. Spark 资源调度和任务调度
一个stage一个stak执行不结束这个stage就执行不结束,satage对应的job(任务)就执行不结束,及颗老鼠屎坏了一锅粥。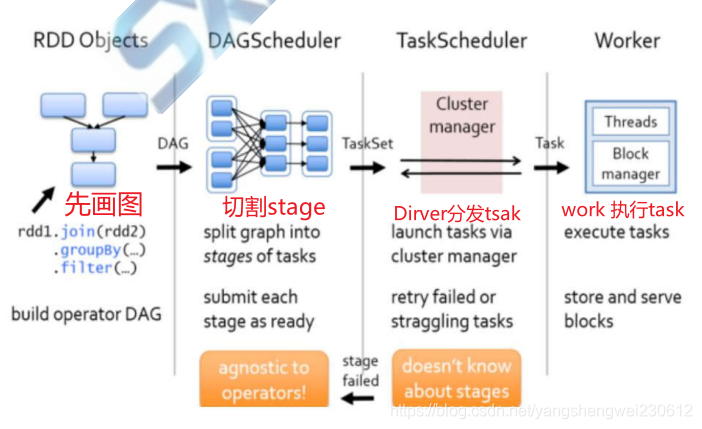
Spark 资源调度和任务调度的流程:
执行慢的task,启动一个新的task计算不交默认是关闭的。
图解 Spark 资源调度和任务调度的流程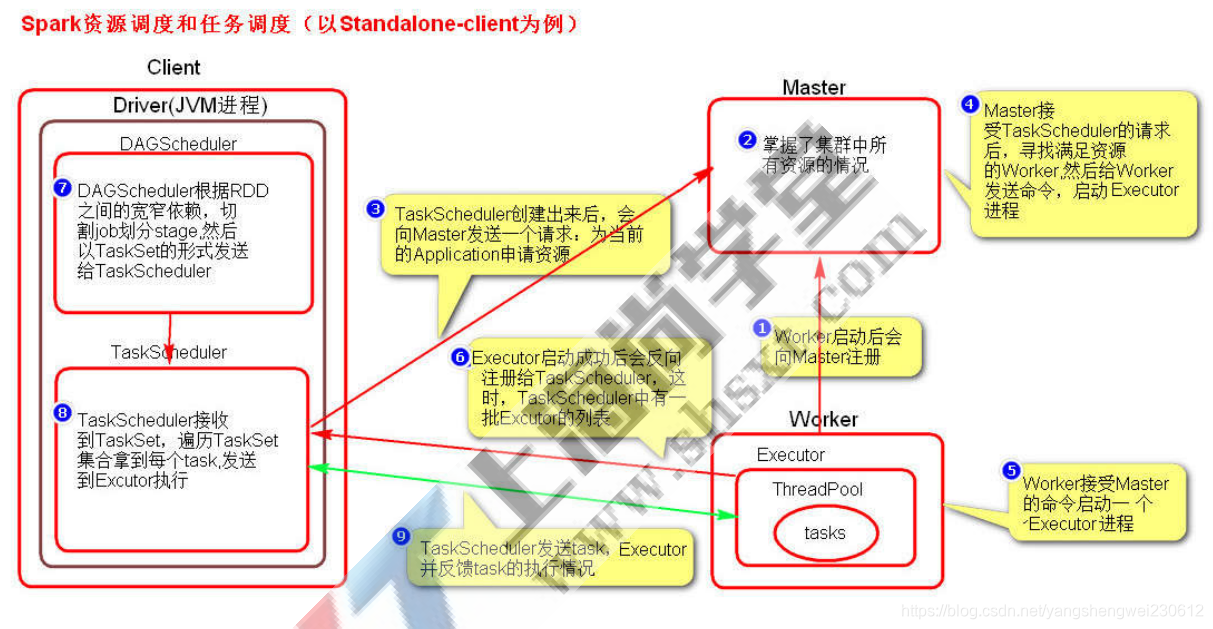
粗粒度资源申请和细粒度资源申请
MR是细粒度的,由每个task计算时task自己申请资源,task计算完就释放资源
Spark是粗粒度的,任务开始的给所有的task申请好资源,所有的task都计算完才释放资源。
