本文可以用于flink相关内容的入门练习对照。欢迎各路高手批评指导!
flink版本:1.10.1
kafka版本:0.10.0
hive版本:1.2.1
依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.10.1</version>
</dependency><dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>代码:
package joinhive
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
import org.apache.flink.table.api.scala.{StreamTableEnvironment, _}
import org.apache.flink.table.api.{EnvironmentSettings, Table}
import org.apache.flink.table.catalog.hive.HiveCatalog
import org.apache.flink.types.Row
//kafka数据样例类
case class UserInfo(userid: String, ulac: String, usell: String)
object KafkaCombineHive {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val paramTool: ParameterTool = ParameterTool.fromArgs(args)
val host: String = paramTool.get("host")
val port: Int = paramTool.getInt("port")
val group: String = paramTool.get("group")
val properties = new Properties()
properties.setProperty("group.id", group)
properties.setProperty("bootstrap.servers", host + ":" + port)
val simpleStringSchema = new SimpleStringSchema()
val kafka: FlinkKafkaConsumer010[String] = new FlinkKafkaConsumer010[String]("f_input01", simpleStringSchema, properties)
kafka.setStartFromLatest()
kafka.setCommitOffsetsOnCheckpoints(true)
val KafkaInStream: DataStream[String] = env.addSource(kafka)
//增加对kafka的转换 其内部格式为样例类
val kafkaUserStream: DataStream[UserInfo] = KafkaInStream.map(a => {
val tem = a.split(",")
UserInfo(tem(0), tem(1), tem(2))
})
// 尝试创建kafka的表
val blinkStreamSettings_k: EnvironmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
val blinkStreamTableEnv_k: StreamTableEnvironment = StreamTableEnvironment.create(env, blinkStreamSettings_k)
val kafka_tab: Table = blinkStreamTableEnv_k.fromDataStream(kafkaUserStream)
blinkStreamTableEnv_k.createTemporaryView("ktable", kafka_tab)
// val sql2 = "select * from ktable where userid = 's101'"
val sql2 = "select * from ktable"
val result_k: Table = blinkStreamTableEnv_k.sqlQuery(sql2)
/**
* 下方为hive处理部分
*/
//创建hive-site.xml路径 ,当前是win环境下把hive-site.xml 放在D:\dp_maintenance
val hiceConfdir = "D:\\dp_maintenance"
//hive 版本为1.2.1
val hiveVersion = "1.2.1"
//创建HiveCatalog
val hive: HiveCatalog = new HiveCatalog("hive", "default", hiceConfdir, hiveVersion)
// hive.getHiveConf
// 注册hive catalog
blinkStreamTableEnv_k.registerCatalog("hive", hive)
//使用指定hive catalog
blinkStreamTableEnv_k.useCatalog("hive")
//sql里ods22是指hive的database lacci是该库下的一个维表,即提供数据和kafka流做关联的hive表
val sql_select1 = "select * from ods22.lacci".stripMargin
val resultselect: Table = blinkStreamTableEnv_k.sqlQuery(sql_select1)
// blinkStreamTableEnv_k.createTemporaryView("hive1", resultselect)
// val sql3 = "select * from hive1 "
result_k.join(resultselect, "id = userid").toAppendStream[Row].print()
env.execute("kafka join hive")
}
}
hive中维表样例:
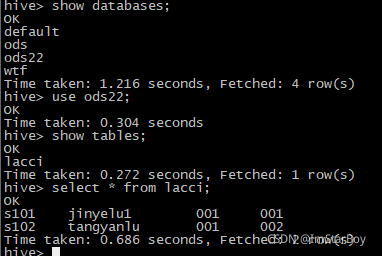
输入:

输出:
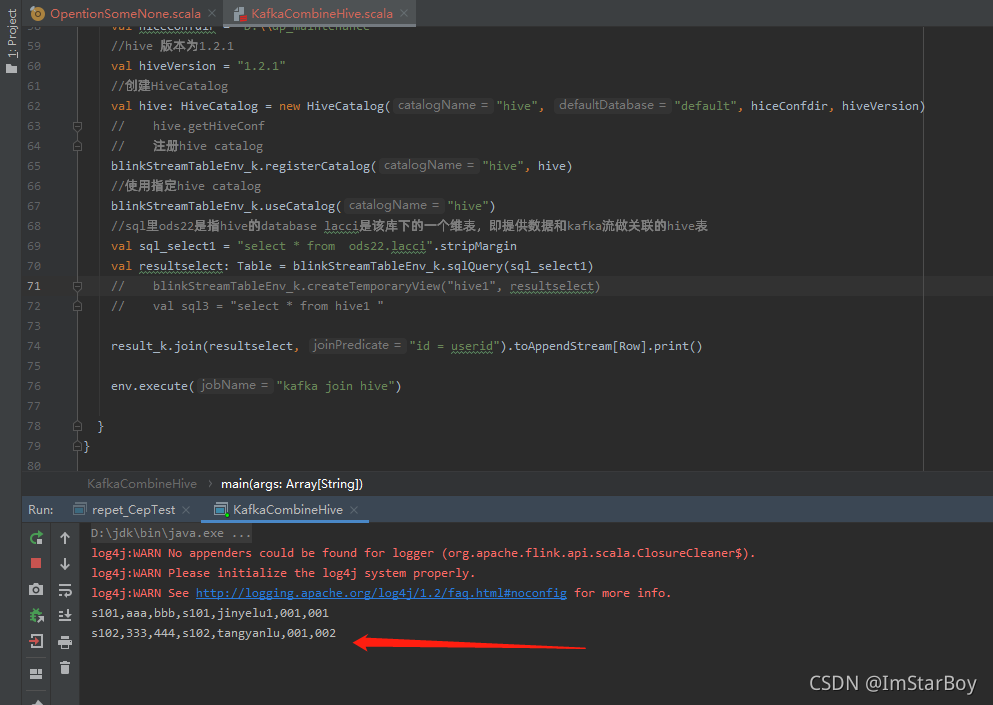
补充说明:
这是一个最简单的关联场景。没有往kafka或者hdfs里sink;
当前使用的join并不是“left join”,所以流数据如果按照条件没能在维表里关联到数据,则该条流数据也不在最后的table里;
网上很多方法可以“动态”加载更新后的hive维表,例如flink1.11版本之后TABLE_DYNAMIC_TABLE_OPTIONS_ENABLED=true。
版权声明:本文为ImStarBoy原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。