项目原理
基于词频:统计文章中词频,构建词频特征向量,利用特征向量夹角的余弦值表示文本的相似度。两篇文章最大相似度为1,特征向量夹角为0°。
基于词频的文本相似度检测步骤:
- 文本1和文本2
- 分词—去停用词
- 统计两篇文章的词频
- 词频向量1和词频向量2
- 相似度的计算
- 分词:例:“我是一个学生” 分词后为“我//是//一个//学生”
- 去停用词 分词后可发现有很多词是没有实际含义的功能性词,例如“我” 、“怎么办”、“总之”。因此分词后不能直接对词频进行统计,应先去掉停用词后,再对词频进行统计。
- 词频 单词在文章中出现的次数,词频越大,可以认为该词越重要
- 词频向量在构建词频向量时,需要考虑向量的意义,也必须保障向量的一致性,即两个文本向量每一维的值应该代表的是同一个词的词频。
例:
文档1 今天//有事//,//没办法//去//学校//上课//了
文档2 真想//去//学校//上课//,//但是//今天//有事//,//去不了//学校//了
去掉停用词后
文档1中的词频:[有事1,没办法1,去1,学校1,上课1]
文档2中的词频:[真想1,去1,学校2,上课1,有事1,去不了1]
直接用上述词频构建每一个文本的词频向量是无意义的,因为每一维表示的意思均不同,因此需构建一致的词频向量。
将所有的有效词结合起来构建[学校,去,真想,上课,有事,去不了,没办法]
计算词频向量:
文档1 :[1,1,0,1,1,0,1] 文档2:[2,1,1,1,1,1,0] - 向量相似度 采用余弦相似度
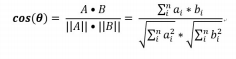
在TextSimilarity类中对各个接口进行声明
class TextSimilarity
{
public:
typedef std::unordered_map<std::string, double> WordFrep;//词频
typedef std::unordered_set<std::string> WordSet;//词表
typedef std::pair<std::string, double> PSI;//键值对
TextSimilarity(const char* dictPach);//构造函数
TextSimilarity(Config& cfg);
void printStopWordSet();//打印停用词表
void printWordFrep(const WordFrep& wordFreq);//打印词频
double getTextSimilarity(const char* file1, const char* file2);//提供获取文本相似度的接口
//private:
//获取停用词表
void getStopWordSet(const char*file);
//获取IDF(逆文档率),表示每个词重要性的权重
void getIDF(const char* file);
//统计词频: word num(map中序遍历是有序的,本身是无序的)
//项目本身需要Value有序,但map不支持,所以使用无序的map,效率较高
void getWordFrep(const char* file, WordFrep& wordFreq);
//统计相对词频,单词词频/文章单词总数
void getNormalizedWordFrep(WordFrep& wordFreq);
//统计加入IDF权重的词频
void getTfIdf(WordFrep& wordFreq, WordFrep& outTfIdf);
//GBK转UTF8
std::string GBK2UTF8(const std::string& gbk);
//UTF8转GBK
std::string UTF82GBK(const std::string& utf8);
//根据Value值进行排序
void sortReverseByValue(const WordFrep& wordFreq, std::vector<PSI>& outSortedWordFreq);
//构建统一的词表
void getWordCode(std::vector<PSI>& inSortWordFreq, WordSet& wordCode);
//根据词表,创建词频向量
void getVector(WordSet& wordCode, WordFrep& wordFreq, std::vector<double>& outVec);
//计算文本相似度
double getCosine(std::vector<double>& vec1, std::vector<double>& vec2);
//分词对象成员
std::string DICT_PATH;//词典路径
cppjieba::Jieba _jieba;//分词对象
//停用词表,只需要存放停用词,用string(字符串)来存储,给一个哈希表
WordSet _stopWordSet;
int _maxWordNum;
WordFrep _Idf;
};
成员变量有5个,分别是分词的词典路径,分词对心,停用词表,构建统一词表的最大个数_maxWordNum,以IDF方式计算的词频_Idf;
IDF(Inverse Document Frequency): 逆文档率,它表示每一个词重要性的权重,一个词越少见,它的值就越大,反之,一个词越常见,它的值就越小。
下面分别实现各个接口的功能:
//构造函数:
TextSimilarity::TextSimilarity(const char* dictPach)
:DICT_PATH(dictPach)
, _jieba(
DICT_PATH + "/jieba.dict.utf8"
, DICT_PATH + "/hmm_model.utf8"
, DICT_PATH + "/user.dict.utf8"
, DICT_PATH + "/idf.utf8"
, DICT_PATH + "/stop_words.utf8"
)
, _maxWordNum(20)//统一的词表最大的个数,初始化为20
{
std::string stopFileDir = DICT_PATH + "/stop_words.utf8";
getStopWordSet(stopFileDir.c_str());
getIDF((DICT_PATH + "/idf.utf8").c_str());
}
//获取停用词,填充在对象_stopWordSet中
void TextSimilarity::getStopWordSet(const char*file)
{
std::ifstream fin(file);
if (!fin.is_open())
{
cout << file << "open failed!" << endl;
return;
}
std::string word;
while (!fin.eof())
{
getline(fin, word);
_stopWordSet.insert(word);
}
fin.close();
}
//拓展,以IDF的方式来确定关键词,获取不同词的IDF权重值,存放在_Idf中
void TextSimilarity::getIDF(const char* file)
{
std::ifstream fin(file);
if (!fin.is_open())
{
std::cout << "file" << file << "open failed!" << std::endl;
return;
}
//读字符流文件,通过字符流的输入来读取,输入运算符重载
std::pair<std::string,double> input;
while (!fin.eof())
{
fin >> input.first >> input.second;
_Idf.insert(input);
}
std::cout << "idf size:" << _Idf.size() << endl;
}
//对一个文本先进行分词,去停用词,之后统计每个词的词频,统计后的结果存放在wordFreq对象中
void TextSimilarity::getWordFrep(const char* file, WordFrep& wordFreq)
{
std::ifstream fin(file);
if (!fin.is_open())
{
cout << file << "open failed!" << endl;
return;
}
std::string line;//空的\0
std::vector<std::string> words;
while (!fin.eof())//文件没有到结束就一直读取
{
words.clear();
getline(fin, line);
//gbk-->utf8
line = GBK2UTF8(line);
//分词
_jieba.Cut(line, words, true);
//统计词频
for (const auto& wd:words)
{
//去停用词
//if (_stopWordSet.find(wd)!=_stopWordSet.end())
if (_stopWordSet.count(wd))//返回两个值1存在,0不存在,以utf8格式查找
continue;
//词频累加
//operator[]:insert(make_pair(K,V()),k不存在,插入成功,返回V&
wordFreq[wd]++;
}
}
fin.close();
}
由于分词的对象是utf8格式的,而我们在文本中输入的文字是GBK格式的;因此在分词之前首先将读到的文本从GBK格式转化成utf8格式的,也就是代码中的GBK2UTF8(const string&);
下面是GBK2UTF8的实现:
1.将GBK->UTF16
2.将UTF16->UTF8
//将文本由GBK转化成UTF8格式
std::string TextSimilarity::GBK2UTF8(const std::string& gbk)
{
//gbk--->utf16
int utf16Bytes = MultiByteToWideChar(CP_ACP, 0, gbk.c_str(), -1, nullptr, 0);//获取buffer大小
wchar_t* utf16Buffer = new wchar_t[utf16Bytes];
MultiByteToWideChar(CP_ACP, 0, gbk.c_str(), -1, utf16Buffer, utf16Bytes);//进行转换
//utf16--->utf8
int utf8Bytes = WideCharToMultiByte(CP_UTF8, 0, utf16Buffer, -1, nullptr, 0, nullptr, nullptr);
char* utf8Buffer = new char[utf8Bytes];
WideCharToMultiByte(CP_UTF8, 0, utf16Buffer, -1, utf8Buffer, utf8Bytes, nullptr, nullptr);
std::string outString(utf8Buffer);//创建新对象,将utf8Buffer内容传入进去
if (utf8Buffer)
delete[] utf8Buffer;
if (utf16Buffer)
delete[] utf16Buffer;
return outString;
}
//相对词频:单词词频/文章单词总数
void TextSimilarity::getNormalizedWordFrep(WordFrep& wordFreq)
{
int sz = wordFreq.size();
for (auto& wf : wordFreq)
{
wf.second /= sz;
}
}
//计算TF-IDF方式计算的词频,存储在outTfIdf
void TextSimilarity::getTfIdf(WordFrep& normalWordFreq, WordFrep& outTfIdf)
{
for (const auto& wf : normalWordFreq)
{
//TFIDF=wf*idf,相对词频*idf权重——》作为TF-IDF的词频
outTfIdf.insert(make_pair(wf.first,wf.second * _Idf[wf.first]));
}
}
//根据词频进行对文本的词语按词频降序进行排序,排序的结果存放在outSortedWordFreq中
void TextSimilarity::sortReverseByValue(const WordFrep& wordFreq,
std::vector<PSI>& outSortedWordFreq)
{
for (const auto& wf : wordFreq)
{
outSortedWordFreq.push_back(wf);
}
sort(outSortedWordFreq.begin(), outSortedWordFreq.end(), CMP());
}
在排序中使用到一个仿函数cmp()
//仿函数重载,重载()运算符
struct CMP
{
//比较的是pair对象的second值,按照逆序排
bool operator()(const TextSimilarity::PSI& left
, const TextSimilarity::PSI& right)
{
return left.second > right.second;
}
};
//对已经排过序的词频,取前_maxWordNUM个词,便于之后构建统一的词向量
void TextSimilarity::getWordCode(std::vector<PSI>& inSortWordFreq, WordSet& wordCode)
{
int len = inSortWordFreq.size();
int sz = len < _maxWordNum ? len : _maxWordNum;
for (int i = 0; i < sz; ++i)
{
wordCode.insert(inSortWordFreq[i].first);
}
}
//根据取到的前_maxWordFreq或len个词表,构建词频向量,存放在outVec
void TextSimilarity::getVector(WordSet& wordCode, WordFrep& wordFreq,std::vector<double>& outVec)
{
outVec.clear();
int sz = wordCode.size();
outVec.reserve(sz);//给vector进行增容
for (const auto& wc : wordCode)
{
if (wordFreq.count(wc))
outVec.push_back(wordFreq[wc]);//拿到单词对应的频率,放到vector中
else
outVec.push_back(0);
}
}
//根据词频向量,使用余弦相似度计算两个文本的相似度
double TextSimilarity::getCosine(std::vector<double>& vec1, std::vector<double>& vec2)
{
if (vec1.size() != vec2.size())
return 0;
double product = 0.0;
double modual1 = 0.0, modual2 = 0.0;
//分子
for (int i = 0; i < vec1.size(); ++i)
{
product += vec1[i] * vec2[i];
}
//分母
for (int i = 0; i < vec1.size(); ++i)
{
modual1 += pow(vec1[i], 2);
}
modual1 = pow(modual1, 0.5);
for (int i = 0; i < vec2.size(); ++i)
{
modual2 += pow(vec2[i], 2);
}
modual2 = pow(modual2, 0.5);
return product / (modual2*modual1);
}
整体流程实现:
void testWordReverse()
{
TextSimilarity ts("dict");
TextSimilarity::WordFrep wf;
TextSimilarity::WordFrep tfidf;
ts.getWordFrep("test.txt", wf);
ts.getNormalizedWordFrep(wf);
//ts.printStopWordSet();
//ts.printWordFrep(wf);
ts.getTfIdf(wf, tfidf);
std::vector<TextSimilarity::PSI> vecFreq;
std::vector<TextSimilarity::PSI> vecTfidf;
ts.sortReverseByValue(wf, vecFreq);
ts.sortReverseByValue(tfidf, vecTfidf);
std::cout << "sorted word freq:" << std::endl;
for (const auto& wf : vecFreq)
{
std::cout << ts.UTF82GBK(wf.first) << ": " << wf.second << " ";
}
std::cout << std::endl;
std::cout << "sorted tfidf:" << std::endl;
for (const auto& wf : vecTfidf)
{
std::cout << ts.UTF82GBK(wf.first) << ": " << wf.second << " ";
}
std::cout << std::endl;
TextSimilarity::WordFrep wf2;
TextSimilarity::WordFrep tfidf2;
ts.getWordFrep("test2.txt", wf2);
ts.getNormalizedWordFrep(wf2);
ts.getTfIdf(wf2, tfidf2);
std::vector<TextSimilarity::PSI> vecFreq2;
std::vector<TextSimilarity::PSI> vecTfidf2;
ts.sortReverseByValue(wf2, vecFreq2);
ts.sortReverseByValue(tfidf2, vecTfidf2);
std::cout << "sorted word freq2:" << std::endl;
for (const auto& wf : vecFreq2)
{
std::cout << ts.UTF82GBK(wf.first) << ": " << wf.second << " ";
}
std::cout << std::endl;
std::cout << "sorted word tfidf2:" << std::endl;
for (const auto& wf : vecTfidf2)
{
std::cout << ts.UTF82GBK(wf.first) << ": " << wf.second << " ";
}
std::cout << std::endl;
//set是本来存储就是去重的
TextSimilarity::WordSet wordCode;
TextSimilarity::WordSet wordCode2;
TextSimilarity::WordSet wordTFIDFCode;
//构建统一的词表wordCode,wordCode的大小<=40
ts.getWordCode(vecFreq, wordCode);
ts.getWordCode(vecFreq2, wordCode);
//构建使用TFIDF方法计算的词频的统一词表,存放在wordCode2
ts.getWordCode(vecTfidf, wordCode2);
ts.getWordCode(vecTfidf2, wordCode2);
std::cout << "wf worfcode:" << std::endl;
for (const auto& wc : wordCode)
{
std::cout << ts.UTF82GBK(wc) << " ";
}
std::cout << std::endl;
std::cout << "TFidf worfcode:" << std::endl;
for (const auto& wc : wordCode2)
{
std::cout << ts.UTF82GBK(wc) << " ";
}
std::cout << std::endl;
std::vector<double> Vec1;
std::vector<double> Vec2;
std::vector<double> VecTfidf1;
std::vector<double> VecTfidf2;
//计算文本1和文本2的词频向量,分别存放在Vec1和Vec2
ts.getVector(wordCode, wf, Vec1);
ts.getVector(wordCode, wf2, Vec2);
ts.getVector(wordCode2, wf, VecTfidf1);
ts.getVector(wordCode2, wf2, VecTfidf2);
std::cout << "vec1:" << std::endl;
for (const auto& e : Vec1)
{
std::cout << e << " ";
}
std::cout << std::endl;
std::cout << "vec2:" << std::endl;
for (const auto& e : Vec2)
{
std::cout << e << " ";
}
std::cout << std::endl;
std::cout << "vecTfidf1:" << std::endl;
for (const auto& e : VecTfidf1)
{
std::cout << e << " ";
}
std::cout << std::endl;
std::cout << "vecTfidf2" << std::endl;
for (const auto& e : VecTfidf2)
{
std::cout << e << " ";
}
std::cout << std::endl;
//计算文本相似度
std::cout << ts.getCosine(Vec1, Vec2) << std::endl;
std::cout << ts.getCosine(VecTfidf1, VecTfidf2) << std::endl;
}
结果展示:
没有使用TFIDF计算词频的文本相似度为0.18144
使用TFID计算词频的两个文本的相似度为0.227002
版权声明:本文为qq_41913858原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。