本文章是阅读 朱凯著的《ClickHouse原理解析与应用实践》的个人读书笔记总结,如有偏差与原著为主,只供学习参考,谢绝转载。
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)
About name
**C**lick Stream
Data Ware**H**ouse
数据类型
基础类型

数值类型
整数

浮点数
定点数
更改精度的数值运算
两种形式可以申明定点
1.简写方式
Decimal32(S)、Decimal64(S)、 Decimal128(S)
2.原生方式
Decimal(P,S)
·P代表精度,决定总位数(整数部分+小数部分),取值范围是1 ~38;
·S代表规模,决定小数位数,取值范围是0~P。
简写和原生方式对应关系
字符串
时间类型

复合类型
特殊类型

数据库
数据表
建表
常规建表
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
省略… ) ENGINE = engine
create table if not exists db_name.table_name(
)
Enging=(,)
partition by
order by()
sample by
SETTINGS index_granularity = 8192
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/default/ods_balance_history', '{replica}')
PARTITION BY toYYYYMMDD(ds)
ORDER BY (hr, time, user_id, asset, business, btype, function)
SAMPLE BY user_id SETTINGS index_granularity = 8192
复制其他表建表
select建表
临时表temporary
临时表的优先级是大于普通表,当两张数据表名称相同的时候,会优先读取临时表的数据。
只支持Memory表引擎,如果会话结束,数据表就会被销毁;临时表不属于任何数据库,所以在它的建表语句中,既没有数据库参数也没有表引擎参数。
create temporary table if not exists db_name.table_name
关于字段定义
明确定义的数据类型优先于默认值的定义
表字段支持三种默认值表达式的定义方法,分别是DEFAULT、 MATERIALIZED和ALIAS。
虽然提供了三种,但除了DEFAULT,其他限制很多,不建议使用,建表时强烈推荐使用明确定义数据类型。
分区
数据分区(partition)和数据分片(shard)是完全不同的两个概念。数据分区是针对本地数据而言的,是数据的一种纵向切分。而数据分片是数据的一种横向切分。
目前只有合并树(MergeTree)家族系列的表引擎才支持数据分区。
分区规则
MergeTree数据分区的规则由分区ID决定
分区ID拥有四种规则:
1.不指定分区键:分区ID默认取名为all
2.使用整型:有符号整型和无符号整型,直接按照该整型的字符形式输出
3.使用日期类型,按照YYYYMMDD进行格式化后的字符形式输出。
4.其他类型:通过128位Hash算法取其Hash值作为分区ID的取值。
命名规则,分区目录的合并过程以及一级索引…略(6.3,6.4二级索引)
PARTITION BY toYYYYMMDD(ds)
分区键不应该使用粒度过细的数据字段。例如,按照小时分区,将会带来分区数量的急剧增长,从而导致性能下降。
复制指定分区
将A表的分区数据复制到B表
ALTER TABLE B REPLACE PARTITION 201907 FROM A
要求满足两个前提条件:
1.两张表需要拥有相同的分区键;
2.它们的表结构完全相同。
清除分区内某列数据 CLEAR COLUMN
没啥用的,将某一列数据全部清空改为默认值,很鸡肋的功能,反正我没用过
ALTER TABLE tb_name CLEAR COLUMN column_name IN PARTITION partition_expr
删除指定分区
在建表时设置月日期作为分区的话,可以删除整月
ALTER TABLE table_name DROP PARTITION 201907
卸载与装载分区-DETACH
分区被卸载后,它的物理数据并没有删除,而是被转移到了当前数据表目录的detached子目录下。
卸载:
ALTER TABLE tb_name DETACH PARTITION partition_expr
装载
ALTER TABLE tb_name ATTACH PARTITION partition_expr
记住,一旦分区被移动到了detached子目录,就代表它已经脱离了ClickHouse的管理,ClickHouse并不会主动清理这些文件。
备份与还原分区
视图
普通视图
不会存储任何数据
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name AS SELECT ...
物化视图

创建的物化视图是个逻辑表, 需要有个地方存放数据 inner表就做这个事情。当然创建物化视图的时候是可以指定持久化表的表名的。 不指定的话就是.inner_xxxx
物化视图支持表引擎
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...
POPULATE修饰符决定了物化视图的初始化策略:如果
使用了POPULATE修饰符,那么在创建视图的过程中,会连带将源表中已存在的数据一并导入。
是使用了.inner.特殊前缀的数据表(持久化),所以删除视图的方法是直接使用DROP TABLE查询
数据表的基本操作
追加新字段
直接在表末尾增加新字段
ALTER TABLE testcol_v1 ADD COLUMN OS String DEFAULT 'mac'
在指定字段的后面增加新字段
ALTER TABLE testcol_v1 ADD COLUMN IP String AFTER ID
对于数据表中已经存在的旧数据而言,新追加的字段会使用默认值补全。
修改数据类型 MODIFY
修改某个字段的数据类型,实质上会调用相应的toType转型方法。如果当前的类型与期望的类型不能兼容,则修改操作将会失败。
ALTER TABLE tb_name MODIFY COLUMN [IF EXISTS] name [type] [default_expr]
修改备注 COMMENT
追加备注的语法如下
ALTER TABLE tb_name COMMENT COLUMN [IF EXISTS] name 'some comment'
删除某字段
述列字段在被删除之后,它的数据也会被连带删除。
ALTER TABLE tb_name DROP COLUMN [IF EXISTS] name
修改表名
也可以同时修改数据库,但只支持同一个服务节点内。
RENAME TABLE default.testcol_v1 TO db_test.testcol_v2
清空数据表
将表内的数据全部清空
TRUNCATE TABLE [IF EXISTS] [db_name.]tb_name
数据的写入
ClickHouse内部所有的数据操作都是面向Block数据块的。
默认的情况下,每个数据块最多可以写入1048576行数据(由max_insert_block_size参数控制)。也就是说,如果一条INSERT语句写入的数据少于max_insert_block_size行,那么这批数据的写入是具有原子性的,即要么全部成功,要么全部失败。
使用VALUES格式直接写入
INSERT INTO table_name VALUES
('A0011','www.nauu.com', '2019-10-01'),
('A0012','www.nauu.com', '2019-11-20'),
('A0013','www.nauu.com', '2019-12-20')
使用SELECT子句形式
写这么多足以看出我对它的爱。。。
insert into table_name(字段名,字段名)
SELECT 字段
FROM 表名
where ds = '2021-01-04'
group by
...
使用指定格式的语法:??
INSERT INTO [db.]table [(c1, c2, c3…)] FORMAT format_name data_set
删除与修改
数据删除的过程是以数据表的每个分区目录为单位,将所有目录重写为新的目录,新目录的命名规则是在原有名称上加上system.mutations.block_numbers.number。数据在重写的过程中会将需要删除的数据去掉。旧的数据目录并不会立即删除,而是会被标记成非激活状态(active为0)。等到MergeTree引擎的下一次合并动作触发时,这些非激活目录才会被真正从物理意义上删除。
删除
ALTER TABLE [db_name.]table_name DELETE WHERE filter_expr
ALTER TABLE partition_v2 DELETE WHERE ID = 'A003'
修改:
UPDATE支持在一条语句中同时定义多个修改字段,分区键和主键不能作为修改字段。
ALTER TABLE partition_v2 UPDATE URL = 'www.wayne.com',OS = 'mac' WHERE ID IN (SELECT ID FROM partition_v2 WHERE EventTime = '2019-06-01')
数据TTL
TTL即Time To Live,数据的存活时间
定期删除过期的数据
定期移动过期数据进行归档
适用对象
列
表
分区表
物化视图的列
常见类型:
TTL create_time + interval 10 second
TTL create_time + toIntervalSecond(10)
1.列级别TTL
主键字段不能被声明TTL。
CREATE TABLE ttl_table_v1(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 10 SECOND,
type UInt8 TTL create_time + INTERVAL 10 SECOND )
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time) ORDER BY id
2.表级别TTL
要为整张数据表设置TTL,需要在MergeTree的表参数中增加TTL表达式
CREATE TABLE ttl_table_v2(
id String, create_time DateTime,
code String TTL create_time + INTERVAL 1 MINUTE,
type UInt8 )
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
TTL create_time + INTERVAL 1 DAY
TTL运行机制
1.每当表写入新数据的时候,会根据interval表达式的计算结果为这个分区生成ttl.txt文件,该文件会记录过期的时间
2.只有MergeTree合并分区的时候会触发TTL过期数据的逻辑
3.在删除分区的时候,选择使用了贪婪算法,算法规则即尽可能找到会最早过期,同时时间最早的分区
4.若一个分区内某一列因为TTL到期则全部删除,在合并之后生成的新分区目录中将不会包含这个列字段的数据文件(.bin 和.mrk)
注意:
TTL默认的合并频率有mergeTree的参数merge_with_ttl_timeout控制,默认周期为86400秒
专门维护一个专有的TTL任务队列,有别于MergeTree常规合并任务,若这个值设置的过小则可能带来性能损耗。
此设置意味着在一个分区或发生后台合并时,每24H执行一次TTL删除,因此,在最坏的情况下,click house最多每24h删除一个此行为可能不理想,因此,可以修改表的merge_with_ttl_timeout设置
1.直接修改:alter table t_table_ttl MODIFY SETTING merge_with_ttl_timeout = 3600;
设置为一个小时。
2.除了触发TTL合并之外,optimize命令可以强制触发合并
触发一个分区合并
optimize table t;
触发所有分区合并
optimize table t final
3.没哟有删除TTL声明的方法,但是提供了全剧控制TTL合并任务的启动和关停方法
system stop/start TTL MERGE
修改删除TTL:https://clickhouse.tech/docs/en/sql-reference/statements/alter/ttl/
存储策略
JBOD策略
HOT/COLD策略
数据存储6.5
数据标记6.6
表引擎系列
表引擎大致分成6个系列,合并树、外部存储、内存、文件、接口和其他
MergeTree的存储结构

MergeTree

在ClickHouse众多的表引擎中,MergeTree是最为核心,因为只有MergeTree才支持主键索引、数据分区、数据副本、TTL等高级特性并拥有最强的性能。
MergeTree在ClickHouse中有两层语义:
1.代表合并树(MergeTree)表引擎家族;
2.表示合并树家族中最基础的MergeTree表引擎。合并树(MergeTree),合并的对象正是它的分区目录,在数据的写入过程中,以数据片段的形式被写入磁盘,且数据片段不可修改。每执行一次INSERT),MergeTree都会按照分区规则生成一个全新的分区目录。为了避免片段过多,在未来的某一时刻,属于相同分区的数据片段会被合并成一个全新的分区目录。
MergeTree表引擎是一个家族系列,目前整个系列一共包含了14种不同类型的MergeTree

7种MergeTree共用一个主体,它们的主要区别在Merge部分的逻辑,所以特殊功能只会在Merge合并时才会触发。

均继承于MergeTree的 MergingSortedBlockInputStream。
MergingSortedBlockInputStream 的主要作用,是按照ORDER BY的规则保持新分区数据的有序性.
Merge的逻辑:分区内数据排序后,找到相邻的数据,做特殊处理。
- 余下的7种ReplicatedMergeTree系列,借助ZooKeeper的消息日志广播,ReplicatedMergeTree在原有的基础之上增加了分布式协同的能力,实现了副本实例之间的数据同步功能。
默认情况:
- ORDER BY 决定了每个分区中数据的排序规则;(负责分区内数据排序)
- PRIMARY KEY 决定了一级索引(primary.idx);(负责一级索引生成);
- ORDER BY 可以指代PRIMARY KEY, 通常只用声明ORDER BY 即可。
- ORDER BY的作用, 负责分区内数据排序;
- PRIMARY KEY的作用, 负责一级索引生成;
- Merge的逻辑, 分区内数据排序后,找到相邻的数据,做特殊处理。
- 只有在触发合并之后,才能触发特殊逻辑。
- 只对同一分区内的数据有效。

ReplacingMergeTree-数据去重

ReplacingMergeTree在合并分区时删除重复的数据。
(1)使用ORBER BY排序键作为判断重复数据的唯一键。
(2)只有在合并分区的时候才会触发删除重复数据的逻辑。
(3)以数据分区为单位删除重复数据。当分区合并时,同一分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。
(4)在进行数据去重时,因为分区内的数据已经基于ORBER BY
进行了排序,所以能够找到那些相邻的重复数据。
(5)数据去重策略有两种:
·如果没有设置ver版本号,则保留同一组重复数据中的最后一行。
·如果设置了ver版本号,则保留同一组重复数据中ver字段取值最大的那一行。
SummingMergeTree/AggregatingMergeTree聚合
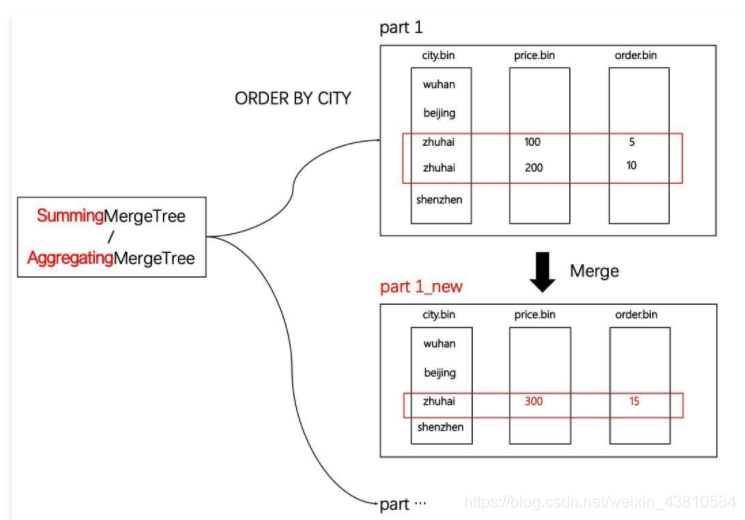
可以将物化视图设置成聚合类MergeTree,将其作为固定主题的查询表使用。值得一提的是,通常只有在使用SummingMergeTree或AggregatingMergeTree的时候,才需要同时设置ORDER BY与PRIMARY KEY。
显式的设置PRIMARY KEY,是为了将主键和排序键设置成不同的值,是进一步优化的体现。例如某个场景的查询需求如下:
聚合条件,GROUP BY A,B,C
过滤条件,WHERE A
此时,如下设置将会是一种较优的选择:
GROUP BY A,B,C
PRIMARY KEY A
BTW,如果ORDER BY与PRIMARY KEY不同,PRIMARY KEY必须是ORDER BY的前缀(为了保证分区内数据和主键的有序性)。
SummingMergeTree
(1)用ORBER BY排序键作为聚合数据的条件Key。
(2)只有在合并分区的时候才会触发汇总的逻辑。
(3)以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。
(4)如果在定义引擎时指定了columns汇总列(非主键的数值类型字段),则SUM汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段。
(5)在进行数据汇总时,因为分区内的数据已经基于ORBER BY排序,所以能够找到相邻且拥有相同聚合Key的数据。
(6)在汇总数据时,同一分区内,相同聚合Key的多行数据会合并成一行。其中,汇总字段会进行SUM计算;对于那些非汇总字段,则会使用第一行数据的取值。
(7)支持嵌套结构,但列字段名称必须以Map后缀结尾。嵌套类型中,默认以第一个字段作为聚合Key。除第一个字段以外,任何名称以Key、Id或Type为后缀结尾的字段,都将和第一个字段一起组成复合Key。
根据排序键对数值类型的列进行汇总求和,数值列进行求和,非数值列随机取值(相同排序键的行合并为一行)
如果一个排序键对应大量的行,则该引擎能显著减少存储空间并加快数据查询的速度
建议该引擎与MergeTree引擎结合。完整的数据存储在MergeTree表中,使用SummingMergeTree存储聚合数据,可以防止排序键的组合不正确而丢失有价值的数据。
指定表引擎:
ENGINE = SummingMergeTree([columns])
参数:columns,具有列名称的元组,其中的值将被汇总。可选参数。
列必须是数值类型,并且不能是主键中列。
如果columns参数没有指定,ClickHouse将汇总除了主键列之外的所有数值类型列的值。
汇总规则:
数值类型的列的值会被汇总,列的集合由参数columns定义。
如果求和的所有列中的值都为0,则删除该行。
如果列不在主键中且未汇总,则从现有的值中任意选择一个值。
主键中的列不会汇总。
ClickHouse可能不会完整地汇总所有行,因此需在查询中使用聚合函数sum和GROUP BY子句
AggregatingMergeTree
(1)用ORBER BY排序键作为聚合数据的条件Key。
(2)使用AggregateFunction字段类型定义聚合函数的类型以及聚合的字段。
(3)只有在合并分区的时候才会触发聚合计算的逻辑。
(4)以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并计算,而不同分区之间的数据则不会被计算。
(5)在进行数据计算时,因为分区内的数据已经基于ORBER BY排序,所以能够找到那些相邻且拥有相同聚合Key的数据。
(6)在聚合数据时,同一分区内,相同聚合Key的多行数据会合并成一行。对于那些非主键、非AggregateFunction类型字段,则会使用第一行数据的取值。
(7)AggregateFunction类型的字段使用二进制存储,在写入数据时,需要调用State函数;而在查询数据时,则需要调用相应的Merge函数。其中,*表示定义时使用的聚合函数。
(8)AggregatingMergeTree通常作为物化视图的表引擎,与普通MergeTree搭配使用。
AggregatingMergeTree可用于增量数据聚合,包括物化视图的聚合。
将相同排序健的所有行(在一个数据片段内)替换为一行,该行存储了聚合函数状态的组合。
该引擎需结合AggregateFunction数据类型的列使用
指定表引擎:
ENGINE = AggregatingMergeTree()
数据插入:
使用带-State后缀的聚合函数。如sumState、uniqState等。
数据查询:
使用GROUP BY子句和聚合函数(与插入的聚合函数相同),但是使用-Merge后缀的聚合函数。如sumMerge、uniqueMerge等。
原文链接:
https://blog.csdn.net/K_520_W/article/details/115678920
DROP TABLE IF EXISTS test_aggregates;
CREATE TABLE test_aggregates
(
d Date,
sumV AggregateFunction(sum, UInt64),
uniqV AggregateFunction(uniq, UInt64)
)
ENGINE = AggregatingMergeTree()
ORDER BY d;
INSERT INTO test_aggregates
SELECT
toDate('2020-06-01') AS d,
sumState(number) as sumV,
uniqState(number) AS uniqV
FROM
(
SELECT toUInt64(number%8) as number FROM system.numbers LIMIT 10
);
xxxxx :) select * from test_aggregates;
SELECT *
FROM test_aggregates
┌──────────d─┬─sumV─┬─uniqV────────┐
│ 2020-06-01 │ _x001D_ │u鏘 ޑh⭋4uULԳE|ȧe │
└────────────┴──────┴──────────────┘
1 rows in set. Elapsed: 0.005 sec.
xxxxx :) select sumMerge(sumV),uniqMerge(uniqV) FROM test_aggregates;
SELECT
sumMerge(sumV),
uniqMerge(uniqV)
FROM test_aggregates
┌─sumMerge(sumV)─┬─uniqMerge(uniqV)─┐
│ 29 │ 8 │
└────────────────┴──────────────────┘
1 rows in set. Elapsed: 0.007 sec.
drop table t_basic;
create table t_basic(key String, sign UInt8, userId String) ENGINE=MergeTree order by key;
drop table t_m_view;
CREATE MATERIALIZED VIEW t_m_view
ENGINE = AggregatingMergeTree() ORDER BY (key)
AS SELECT
key,
sumState(sign) AS sumSign,
uniqState(userId) AS uniqUsers
FROM t_basic
CollapsingMergeTree/ VersionedCollapsingMergeTree–数据更新
数据的更新在ClickHouse中有多种实现手段,例如按照分区Partition重新写入、使用Mutation的DELETE和UPDATE查询。
使用CollapsingMergeTree或VersionedCollapsingMergeTree也能实现数据更新,这是一种使用标记位,以增代删的数据更新方法:
CollapsingMergeTree和VersionedCollapsingMergeTree的区别又是什么呢?
CollapsingMergeTree对数据写入的顺序是敏感的,它要求标志位需要按照正确的顺序排序。例如按照1,-1的写入顺序是正确的; 而如果按照-1,1的错误顺序写入,CollapsingMergeTree就无法正确抵消。
无法保证这种顺序写入的时候,此时就需要使用VersionedCollapsingMergeTree。
VersionedCollapsingMergeTree在CollapsingMergeTree基础之上,额外要求指定一个version字段,在分区Merge合并时,它会自动将version字段追加到ORERY BY的末尾,从而保证了标志位的有序性。
ENGINE = VersionedCollapsingMergeTree(sign,ver)ORDER BY id//等效于ORDER BY id,ver
GraphiteMergeTree-监控集成
GraphiteMergeTree可以与Graphite集成,如果你使用了Graphite作为系统的运行监控系统, 则可以通过GraphiteMergeTree存储指标数据,加速查询性能、降低存储成本。
各种MergeTree之间的关系总结

Replicated-高可用
Replicated* 拥有数据副本的能力,如下图所示:
如果进一步需要高可用的需求,选择一种MergeTree和Replicated组合即可,例如ReplicatedMergeTree、ReplicatedReplacingMergeTree等等。
数据查询
对于SQL语句的解析是大小写敏感的
[WITH expr |(subquery)]
SELECT [DISTINCT] expr
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE expr]
[[LEFT] ARRAY JOIN]
[GLOBAL] [ALL|ANY|ASOF] [INNER | CROSS | [LEFT|RIGHT|FULL [OUTER]] ] JOIN
(subquery)|table ON|USING columns_list
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr] [WITH ROLLUP|CUBE|TOTALS]
[HAVING expr]
[ORDER BY expr]
[LIMIT [n[,m]]
[UNION ALL]
[INTO OUTFILE filename]
[FORMAT format]
[LIMIT [offset] n BY columns]
副本和分片Unit10
分区和分片有什么区别?
ENGINE = ReplicatedMergeTree('zk_path', 'replica_name')
zk_path; /clickhouse/tables/{shard}/table_name
·/clickhouse/tables/是约定俗成的路径固定前缀,表示存放数据表的根路径。
·{shard}表示分片编号,通常用数值替代,例如01、02、03。一张数据表可以有多个分片,而每个分片都拥有自己的副本。
·table_name表示数据表的名称,为了方便维护,通常与物理表的名字相同(虽然ClickHouse并不强制要求路径中的表名称和物理表名
相同)
replica_name的作用是定义在ZooKeeper中创建的副本名称,该名称是区分不同副本实例的唯一标识。一种约定成俗的命名方式是使用所在服务器的域名称。
对于zk_path而言,同一张数据表的同一个分片的不同副本,应该定义相同的路径;而对于replica_name而言,同一张数据表的同一个分片的不同副本,应该定义不同的名称。

一级索引
MergeTree的主键使用PRIMARY KEY定义,待主键定义之后,
MergeTree会依据index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照PRIMARY KEY排序。
稀疏索引

在稠密索引中每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中,每一行索引标记对应的是一段数据,而不是一行。
稀疏索引仅需使用少量的索引标记就能够记录大量数据的区间位置信息,且数据量越大优势越为明显。由于稀疏索引占用空间小,所以primary.idx
内的索引数据常驻内存,取用速度自然极快。
索引粒度
index_granularity不单只作用于一级索引(.idx),同时也会影响数据标记(.mrk)和数据文件(.bin)
仅有一级索引自身是无法完成查询工作的,它需要借助数据标记才能定位数据,所以一级索引和数据标记的间隔粒度相同(同为index_granularity行),彼此对齐。而数据文件也会依照index_granularity的间隔粒度生成压缩数据块。
索引数据的生成规则
索引的查询过程
1.生成查询条件区间
2.递归交集判断
3.合并MarkRange区间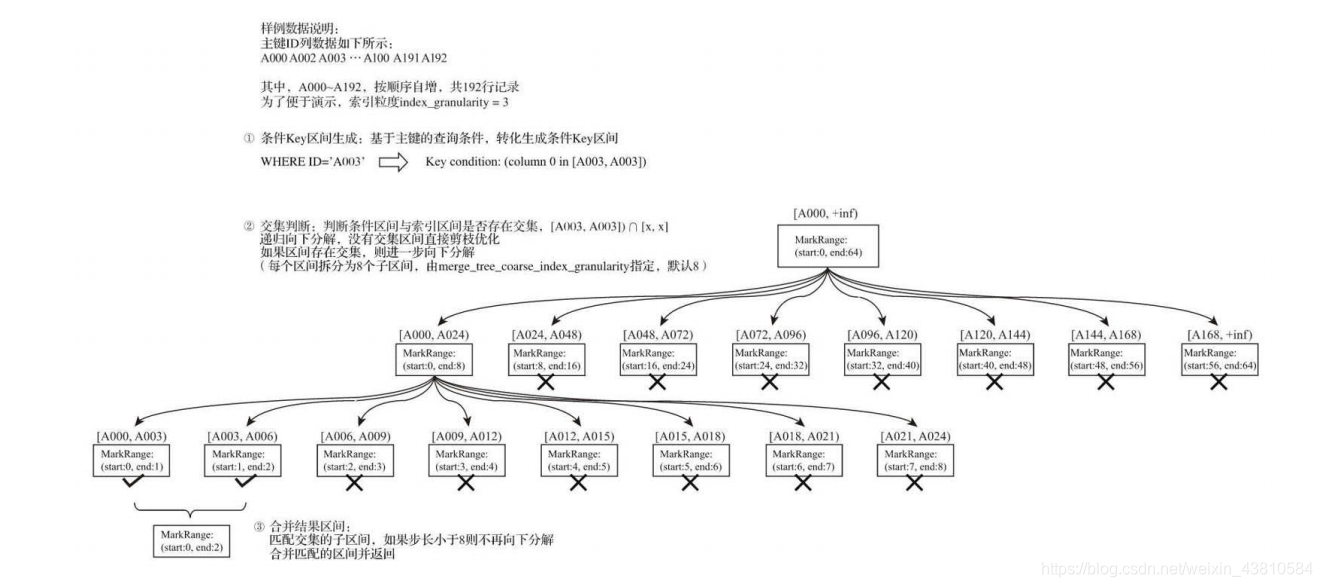
二级索引
二级索引又称跳数索引,由数据的聚合信息构建而成。根据索引类型的不同,其聚合信息的内容也不同。跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
跳数索引需要在CREATE语句内定义,定义语法如下所示:
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity
与一级索引一样,如果在建表语句中声明了跳数索引,则会额外
生成相应的索引与标记文件(skp_idx_[Column].idx与skp_idx_[Column].mrk)。
granularity与index_granularity的关系
granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
minmax索引为例,它的聚合信息是在一个index_granularity区间
内数据的最小和最大极值。
以minmax索引为例,它的聚合信息是在一个index_granularity区间内数据的最小和最大极值。假设index_granularity=8192且granularity=3,则数据会按照index_granularity划分为n等份,MergeTree从第0段分区开始,依次获取聚合信息。当获取到第3个分区时(granularity=3),则汇总并会生成第一行minmax索引(前3段minmax极值汇总后取值为[1,9])。
跳数索引(二级索引)的类型
一张数据表支持同时声明多个跳数索引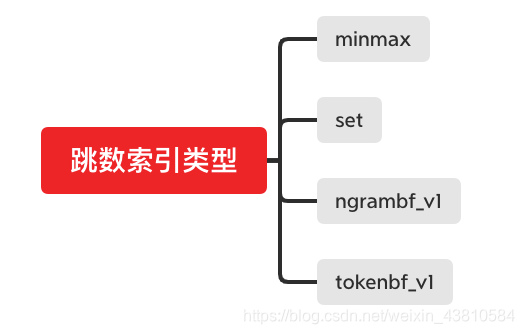
minmax
minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录的minmax索引,能够快速跳过无用的数据区间
# minmax索引会记录这段数据区间内ID字段的极值。
# 极值的计算涉及每5个index_granularity区间中的数据。
INDEX a ID TYPE minmax GRANULARITY 5
set
set索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。如果max_rows=0,则表示无限制,例如:
记录数据中ID的长度*8后的取值。其中,每个index_granularity内最多记录100条
INDEX b(length(ID) * 8) TYPE set(100) GRANULARITY 5
INDEX idx2 (id, uid, txid, symbol, category, business) TYPE set(0) GRANULARITY 4)
ngrambf_v1
ngrambf_v1索引记录的是数据短语的布隆表过滤器,只支持String和FixedString数据类型。
ngrambf_v1只能够提升in、 notIn、like、equals和notEquals查询的性能,其完整形式为
ngrambf_v1(n,size_of_bloom_filter_in_bytes,number_of_hash_functions,ran
dom_seed)。这些参数是一个布隆过滤器的标准输入,如果你接触过布隆过滤器,应该会对此十分熟悉。它们具体的含义如下:
·n:token长度,依据n的长度将数据切割为token短语。
·size_of_bloom_filter_in_bytes:布隆过滤器的大小。
·number_of_hash_functions:布隆过滤器中使用Hash函数的个数。
·random_seed:Hash函数的随机种子。
例如在下面的例子中,ngrambf_v1索引会依照3的粒度将数据切割成短语token,token会经过2个Hash函数映射后再被写入,布隆过滤器大小为256字节。
INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5 (4)
tokenbf_v1
tokenbf_v1索引是ngrambf_v1的变种,同样也是一种布隆过滤器索引。tokenbf_v1除了短语token的处理方法外,其他与ngrambf_v1是完全一样的。tokenbf_v1会自动按照非字符的、数字的字符串分割token,具体用法如下所示:
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
Click house的底层引擎
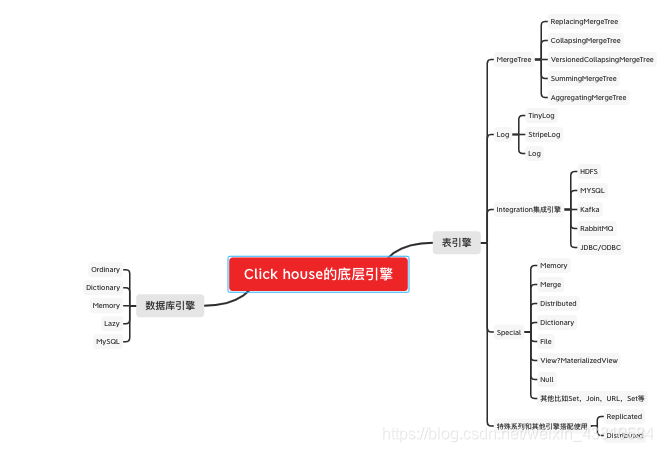
数据库引擎
Ordinary
Dictionary
Memory
Lazy
MySQL
表引擎
MergeTree
Log
Integration集成引擎
Special

特殊系列和其他引擎搭配使用
Replicated
Distributed