系列文章目录
近红外光谱分析技术属于交叉领域,需要化学、计算机科学、生物科学等多领域的合作。为此,在(北京邮电大学杨辉华老师团队)指导下,近期准备开源传统的PLS,SVM,ANN,RF等经典算和SG,MSC,一阶导,二阶导等预处理以及GA等波长选择算法以及CNN、AE等最新深度学习算法,以帮助其他专业的更容易建立具有良好预测能力和鲁棒性的近红外光谱模型。
前言
NIRS是介于可见光和中红外光之间的电磁波,其波长范围为(1100∼2526 nm。 由于近红外光谱区与有机分子中含氢基团(OH、NH、CH、SH)振动的合频和 各级倍频的吸收区一致,通过扫描样品的近红外光谱,可以得到样品中有机分子含氢 基团的特征信息,常被作为获取样本信息的一种有效的载体。 基于NIRS的检测方法具有方便、高效、准确、成本低、可现场检测、不 破坏样品等优势,被广泛应用于各类检测领域。但 近红外光谱存在谱带宽、重叠较严重、吸收信号弱、信息解析复杂等问题,与常用的 化学分析方法不同,仅能作为一种间接测量方法,无法直接分析出被测样本的含量或 类别,它依赖于化学计量学方法,在样品待测属性值与近红外光谱数据之间建立一个 关联模型(或称校正模型,Calibration Model) ,再通过模型对未知样品的近红外光谱 进行预测来得到各性质成分的预测值。现有近红外建模方法主要为经典建模 (预处理+波长筛选进行特征降维和突出,再通过pls、svm算法进行建模)以及深度学习方法(端到端的建模,对预处理、波长选择等依赖性很低)应博友要求,本篇主要讲述SVM的的近红外光谱定性分析建模方法
一、数据来源
使用药品数据,共310个样本,每条样本404个变量,根据活性成分,分成4类
图片如下:
:
# figsize = 5, 3
figsize = 8, 5.5
figure, ax = plt.subplots(figsize=figsize)
# ax = plt.figure(figsize=(5,3))
x_col = x_col[::-1] # 数组逆序
y_col = np.transpose(data_x)
plt.plot(x_col, y_col )
plt.tick_params(labelsize=12)
labels = ax.get_xticklabels() + ax.get_yticklabels()
[label.set_fontname('Times New Roman') for label in labels]
font = {'weight': 'normal',
'size': 16,
}
plt.xlabel("Wavenumber/$\mathregular{cm^{-1}}$", font)
plt.ylabel("Absorbance", font)
# plt.title("The spectrum of the {} dataset".format(tp), fontweight="semibold", fontsize='x-large')
plt.show()
plt.tick_params(labelsize=23)
def TableDataLoad(tp, test_ratio, start, end, seed):
# global data_x
data_path = '..//Data//table.csv'
Rawdata = np.loadtxt(open(data_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
table_random_state = seed
if tp =='raw':
data_x = Rawdata[0:, start:end]
# x_col = np.linspace(0, 400, 400)
if tp =='SG':
SGdata_path = './/Code//TableSG.csv'
data = np.loadtxt(open(SGdata_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
data_x = data[0:, start:end]
if tp =='SNV':
SNVata_path = './/Code//TableSNV.csv'
data = np.loadtxt(open(SNVata_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
data_x = data[0:, start:end]
if tp == 'MSC':
MSCdata_path = './/Code//TableMSC.csv'
data = np.loadtxt(open(MSCdata_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
data_x = data[0:, start:end]
data_y = Rawdata[0:, -1]
x_col = np.linspace(7400, 10507, 404)
plotspc(x_col, data_x[:, :], tp=0)
x_data = np.array(data_x)
y_data = np.array(data_y)
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data, test_size=test_ratio,random_state=table_random_state)
return X_train, X_test, y_train, y_test
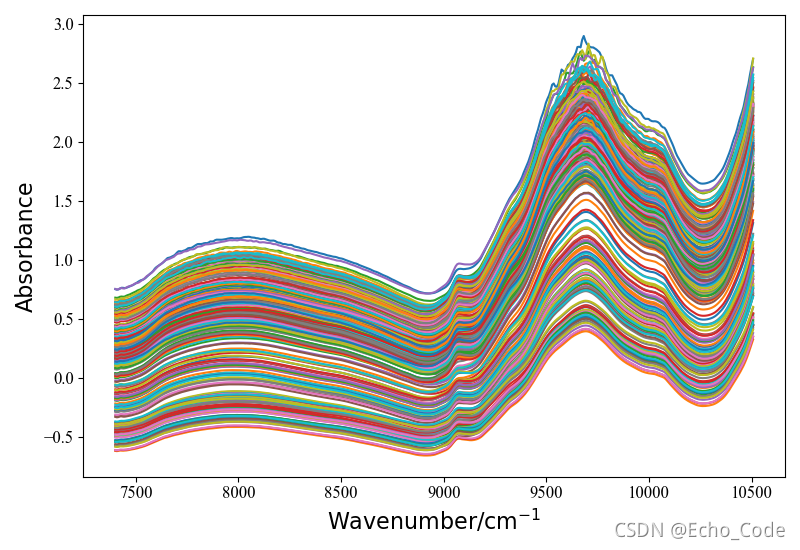
2.1 基于SVM的药品光谱分类
2.1.1 建立SVM参数寻找,找到最佳的SVM参数
def SVM_Classs_test(train_x ,train_y,test_x,test_y):
params = [
{'kernel': ['linear'], 'C': [ 0.1,0.5, 1, 1.5,2,3,5, 10, 15,50,100],'gamma': [1e-7,1e-6,1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1]},
{'kernel': ['poly'], 'C': [0.1, 1, 2, 10, 15], 'degree': [2, 3]}
# {'kernel': ['rbf'], 'C': [0.1, 1, 2, 10], 'gamma':[1e-3, 1e-2, 1e-1, 1, 2]}
]
model = ms.GridSearchCV(svm.SVC(probability=True),
params,
refit=True,
return_train_score=True, # 后续版本需要指定True才有score方法
cv=10)
model.fit(train_x, train_y)
model_best = model.best_estimator_
pred_test_y = model_best.predict(test_x)
acc_test = accuracy_score(test_y, pred_test_y)
print("best pamer is {}".format(model.best_estimator_))
print("acc is {}".format(acc_test))
print(sm.classification_report(test_y, pred_test_y))
结果如下: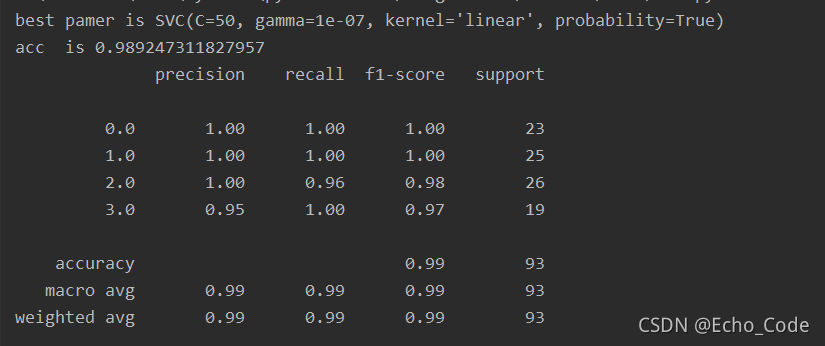
2 .1.2 进行svm的测试
def SVM(train_x ,train_y,test_x,test_y):
clf = svm.SVC(probability=True, C=10, gamma=1e-7,kernel='linear')
clf.fit(train_x, train_y)
pred = clf.predict(test_x)
acc_test = accuracy_score(test_y, pred)
return acc_test
if __name__ == '__main__':
test_ratio = 0.3
tp = 'raw'
X_train, X_test, y_train, y_test = TableDataLoad(tp=tp, test_ratio=test_ratio, start=0, end=404, seed=80)
SVM_Classs_test(train_x=X_train, train_y=y_train, test_x=X_test, test_y=y_test)
acc = SVM(train_x=X_train, train_y=y_train, test_x=X_test, test_y=y_test)
print(acc)
测试结果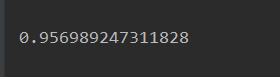
总结
完整代码可从获得GitHub仓库
代码仅供学术使用,如有问题,联系方式:QQ:1427950662,微信:Fu_siry
版权声明:本文为Echo_Code原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。