本文章经授权转载,原文链接:
https://blog.csdn.net/MiaoSO/article/details/104770720
目录
6. 任务节点类型和参数设置
6.1 Shell节点
6.2 子流程节点
6.3 存储过程节点
6.4 SQL节点
6.4.1 Mysql
6.4.2 Hive
6.4.3 Other
6.5 SPARK节点
6.6 Flink节点
6.7 MapReduce(MR)节点
6.7.1 Java 程序
6.7.2 Python 程序
6.8 Python节点
6.9 依赖(DEPENDENT)节点
6.10 HTTP节点
6. 任务节点类型和参数设置
6.1 Shell 节点
运行说明:shell 节点,在 worker 执行的时候,会生成一个临时 shell 脚本,使用租户同名的 linux 用户执行这个脚本。
参数说明:
节点名称:一个工作流定义中的节点名称是唯一的
运行标志:标识这个节点是否能正常调度,如果不需要执行,可以打开禁止执行开关
描述信息:描述该节点的功能
任务优先级:级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行
Worker分组:指定任务运行的机器列表
失败重试次数:任务失败重新提交的次数,支持下拉和手填
失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
超时告警:当任务执行时间超过超时时长可以告警并且超时失败
脚本:用户开发的 SHELL 程序
资源:是指脚本中需要调用的资源文件列表
自定义参数:是 SHELL 局部的用户自定义参数,会替换脚本中以${变量}的内容
例:
项目管理 -> 工作流 -> 工作流定义 -> 创建工作流
------------------------------------------------------
拖拽 "SHELL" 节点到画布,新增一个 Shell 任务。
节点名称:Test_shell_01
运行标志:正常
描述:
任务优先级:MEDIUM
Worker分组:Default
失败重试次数:0
失败重试间隔:1
超时告警:off
脚本:
#!/bin/sh
for i in {1..10};do echo $i;done
资源:
自定义参数:
-> 确认添加
------------------------------------------------------
保存 ->
设置 DAG 图名称:Test_shell
选择租户:Default
超时告警:off
设置全局:
------------------------------------------------------
添加 -> 上线 -> 运行
6.2 子流程节点
运行说明:子流程节点,就是把外部的某个工作流定义当做一个任务节点去执行。
参数说明:
节点名称:一个工作流定义中的节点名称是唯一的
运行标志:标识这个节点是否能正常调度
描述信息:描述该节点的功能
超时告警:勾选超时告警、超时失败,当任务超过"超时时长"后,会发送告警邮件并且任务执行失败
子节点:是选择子流程的工作流定义,右上角进入该子节点可以跳转到所选子流程的工作流定义
例:
项目管理 -> 工作流 -> 工作流定义 -> 创建工作流
------------------------------------------------------
Task 1:拖拽 SHELL 节点到画布,新增一个 Shell 任务
节点名称:Test_subprocess_01
... ...
脚本:
#!/bin/sh
for i in {1..10};do echo $i;done
-> 确认添加
Task 2:拖拽 SUB_PROCESS 节点到画布,新增一个 SUB_PROCESS 任务
节点名称:Test_subprocess_02
... ...
子节点:Test_shell
-> 确认添加
------------------------------------------------------
串联任务节点 Task1 和 Task2
------------------------------------------------------
保存 ->
设置 DAG 图名称:Test_subprocess
选择租户:Default
超时告警:off
设置全局:
------------------------------------------------------
添加 -> 上线 -> 运行
6.3 存储过程节点
运行说明:根据选择的数据源,执行存储过程。
参数说明:
数据源:存储过程的数据源类型支持 MySQL、POSTGRESQL、CLICKHOUSE、ORACLE、SQLSERVER 等,选择对应的数据源
方法:是存储过程的方法名称
自定义参数:存储过程的自定义参数类型支持 IN、OUT 两种,数据类型支持 VARCHAR、INTEGER、LONG、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP、BOOLEAN 九种数据类型
例:
Test_procedure(略)
6.4 SQL 节点
参数说明:
数据源:选择对应的数据源
sql 类型:支持查询和非查询两种,查询是 select 类型的查询,是有结果集返回的,可以指定邮件通知为 表格、附件 或 表格与附件 三种模板。非查询是没有结果集返回的,是针对 update、delete、insert 三种类型的操作
主题、收件人、抄送人:邮件相关配置
sql 参数:输入参数格式为 key1=value1;key2=value2…
sql 语句:SQL 语句
UDF 函数:对于 HIVE 类型的数据源,可以引用资源中心中创建的 UDF 函数,其他类型的数据源暂不支持 UDF 函数
自定义参数:SQL 任务类型自定义参数会替换 sql 语句中 ${变量}。而存储过程是通过自定义参数给方法参数设置值,自定义参数类型和数据类型同存储过程任务类型一样。
前置 sql:执行 “sql语句” 前的操作
后置 sql:执行 “sql语句” 后的操作
6.4.1 Mysql
例:
项目管理 -> 工作流 -> 工作流定义 -> 创建工作流
------------------------------------------------------
Task 1:拖拽 SQL 节点到画布,新增一个 SQL 任务
节点名称:Test_sql_mysql_01
... ...
数据源:MYSQL test01_mysql
sql类型:查询 表格:√ 附件:√
主题:Test MySQL
收件人:tourist@sohh.cn
sql语句:
select * from test_table where score=${i};
自定义参数:
i -> IN -> INTEGER -> 97
前置sql:
INSERT INTO test_table values(null, 'Dog',97)
后置sql:
-> 确认添加
Task 2:拖拽 SQL 节点到画布,新增一个 SQL 任务
节点名称:Test_sql_mysql_02
... ...
数据源:MYSQL test01_mysql
sql类型:非查询
sql语句:
create table test_table2 as select * from test_table;
自定义参数:
前置 sql:
后置 sql:
-> 确认添加
------------------------------------------------------
串联任务节点 Test_sql_mysql_01、Test_sql_mysql_02
------------------------------------------------------
保存 ->
设置 DAG 图名称:Test_sql_mysql
选择租户:Default
超时告警:off
设置全局:
------------------------------------------------------
添加 -> 上线 -> 运行
6.4.2 Hive
例:
项目管理 -> 工作流 -> 工作流定义 -> 创建工作流
------------------------------------------------------
Task 1:拖拽 SQL 节点到画布,新增一个 SQL 任务
节点名称:Test_sql_hive_01
... ...
数据源:Hive test_hiveserver2
sql类型:查询 表格:√ 附件:√
主题:Test Hive
收件人:tourist@sohh.cn
sql语句(结尾不要加分号):
select * from test_table where score=${i}
自定义参数:
i -> IN -> INTEGER -> 97
前置sql:
INSERT INTO test_table values(null, 'Dog',97)
后置sql:
-> 确认添加
Task 2:拖拽 SQL 节点到画布,新增一个 SQL 任务
节点名称:Test_sql_hive_02
... ...
数据源:Hive test_hiveserver2_ha
sql类型:非查询
sql语句(结尾不要加分号):
create table test_table2 as select * from test_table
自定义参数:
前置sql:
后置sql:
-> 确认添加
------------------------------------------------------
串联任务节点 Test_sql_hive_01、 Test_sql_hive_02
------------------------------------------------------
保存 ->
设置 DAG 图名称:Test_sql_hive
选择租户:Default
超时告警:off
设置全局:
------------------------------------------------------
添加 -> 上线 -> 运行
6.4.3 Other
POSTGRESQL、SPARK、CLICKHOUSE、ORACLE、SQLSERVER(略)
6.5 SPARK 节点
执行说明:通过 SPARK 节点,可以直接直接执行 SPARK 程序,对于 spark 节点,worker 会使用 spark-submit 方式提交任务 参数说明:
程序类型:支持 JAVA、Scala 和 Python 三种语言
主函数的 class:是 Spark 程序的入口 Main Class 的全路径
主 jar 包:是 Spark 的 jar 包
部署方式:支持 yarn-cluster、yarn-client、和 local 三种模式
Driver:设置 Driver 内核数 及 内存数
Executor:设置 Executor 数量、Executor 内存数、Executor 内核数
命令行参数:是设置 Spark 程序的输入参数,支持自定义参数变量的替换。
其他参数:支持 --jars、--files、--archives、--conf 格式
资源:如果其他参数中引用了资源文件,需要在资源中选择指定
自定义参数:是 MR 局部的用户自定义参数,会替换脚本中以${变量}的内容
注意:JAVA 和 Scala 只是用来标识,没有区别,如果是 Python 开发的 Spark 则没有主函数的 class ,其他都是一样
例:略
6.6 Flink 节点
参数说明:
程序类型:支持 JAVA、Scala和 Python 三种语言
主函数的 class:是 Flink 程序的入口 Main Class 的全路径
主 jar 包:是 Flink 的 jar 包
部署方式:支持 cluster、local 三种模式
slot 数量:可以设置slot数
taskManage 数量:可以设置 taskManage 数
jobManager 内存数:可以设置 jobManager 内存数
taskManager 内存数:可以设置 taskManager 内存数
命令行参数:是设置Spark程序的输入参数,支持自定义参数变量的替换。
其他参数:支持 --jars、--files、--archives、--conf 格式
资源:如果其他参数中引用了资源文件,需要在资源中选择指定
自定义参数:是 Flink 局部的用户自定义参数,会替换脚本中以${变量}的内容
注意:JAVA 和 Scala 只是用来标识,没有区别,如果是 Python 开发的 Flink 则没有主函数的class,其他都是一样
例:略
6.7 MapReduce(MR) 节点
执行说明:使用 MR 节点,可以直接执行 MR 程序。对于 MR 节点,worker 会使用 hadoop jar 方式提交任务
6.7.1 Java 程序
参数说明:
程序类型:JAVA
主函数的 class:是 MR 程序的入口 Main Class 的全路径
主jar包:是 MR 的 jar 包
命令行参数:是设置 MR 程序的输入参数,支持自定义参数变量的替换
其他参数:支持 –D、-files、-libjars、-archives格式
资源:如果其他参数中引用了资源文件,需要在资源中选择指定
自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
例:
# 将 MR 的示例 jar 包上传到 资源中心;并创建测试文本上传到 HDFS 目录
# CDH 版本 Jar 包位置:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar
项目管理 -> 工作流 -> 工作流定义 -> 创建工作流
------------------------------------------------------
拖拽 MR 节点到画布,新增一个 MR 任务
节点名称:Test_mr_java_01
... ...
程序类型:JAVA
主函数的class:wordcount
主jar包:hadoop-mapreduce-examples.jar
命令行参数:/tmp/test.txt /tmp/output
其他参数:
资源:
自定义参数:
-> 确认添加
------------------------------------------------------
保存 ->
设置DAG图名称:Test_mr_java
选择租户:Default
超时告警:off
设置全局:
------------------------------------------------------
添加 -> 上线 -> 运行(运行MR的权限问题此处不再描述)
------------------------------------------------------
查看结果:
sudo -u hdfs hadoop fs -cat /tmp/output/*
6.7.2 Python 程序
参数说明:
程序类型:Python
主jar包:运行 MR 的 Python jar包
其他参数:支持 –D、-mapper、-reducer、-input -output格式,这里可以设置用户自定义参数的输入,比如:-mapper "mapper.py 1" -file mapper.py -reducer reducer.py -file reducer.py –input /journey/words.txt -output /journey/out/mr/${currentTimeMillis} 其中 -mapper 后的 mapper.py 1是两个参数,第一个参数是mapper.py,第二个参数是1
资源:如果其他参数中引用了资源文件,需要在资源中选择指定
自定义参数:是 MR 局部的用户自定义参数,会替换脚本中以${变量}的内容
6.8 Python节点
运行说明:使用 python 节点,可以直接执行 python 脚本,对于 python 节点,worker会使用 python ** 方式提交任务。参数说明:脚本:用户开发的 Python 程序 资源:是指脚本中需要调用的资源文件列表 自定义参数:是 Python 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容
例:
项目管理 -> 工作流 -> 工作流定义 -> 创建工作流
------------------------------------------------------
拖拽 Python 节点到画布,新增一个 Python 任务
节点名称:Test_python_01
... ...
脚本:
#!/user/bin/python
# -*- coding: UTF-8 -*-
for num in range(0, 10): print 'Round %d ...' % num
资源:
自定义参数:
-> 确认添加
------------------------------------------------------
保存 ->
设置 DAG 图名称:Test_python
选择租户:Default
超时告警:off
设置全局:
------------------------------------------------------
添加 -> 上线 -> 运行
6.9 依赖(DEPENDENT)节点
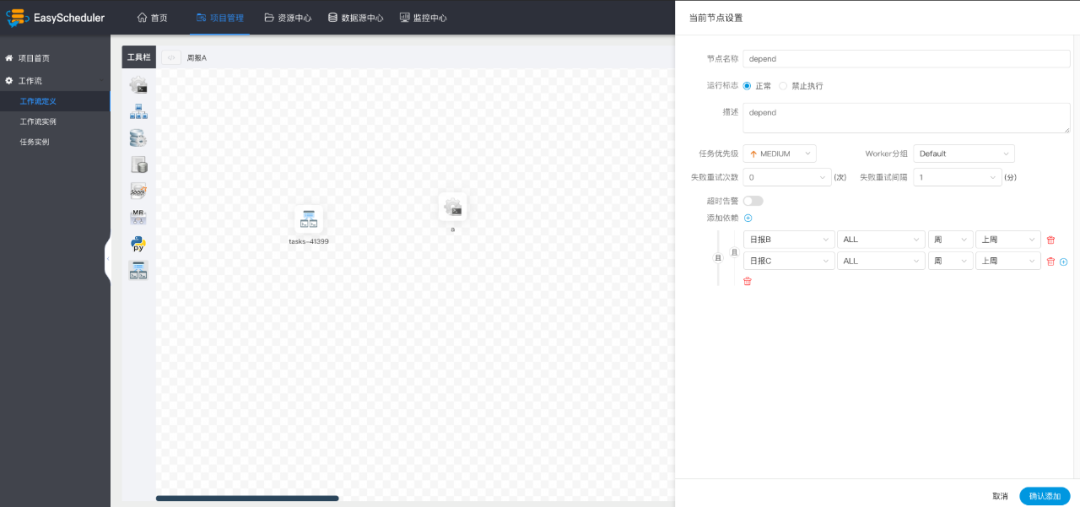
运行说明:依赖节点,就是依赖检查节点。比如 A 流程依赖昨天的 B 流程执行成功,依赖节点会去检查 B 流程在昨天是否有执行成功的实例。
例如,A 流程为周报任务,B、C 流程为天任务,A 任务需要 B、C 任务在上周的每一天都执行成功,如图示:

假如,周报 A 同时还需要自身在上周二执行成功:
6.10 HTTP节点
参数说明:
节点名称:一个工作流定义中的节点名称是唯一的。
运行标志:标识这个节点是否能正常调度,如果不需要执行,可以打开禁止执行开关。
描述信息:描述该节点的功能。
任务优先级:worker 线程数不足时,根据优先级从高到低依次执行,优先级一样时根据先进先出原则执行。
Worker分组:任务分配给worker组的机器机执行,选择Default,会随机选择一台worker机执行。
失败重试次数:任务失败重新提交的次数,支持下拉和手填。
失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填。
超时告警:勾选超时告警、超时失败,当任务超过"超时时长"后,会发送告警邮件并且任务执行失败.
请求地址:http 请求 URL。
请求类型:支持 GET、POSt、HEAD、PUT、DELETE。
请求参数:支持 Parameter、Body、Headers。
校验条件:支持默认响应码、自定义响应码、内容包含、内容不包含。
校验内容:当校验条件选择自定义响应码、内容包含、内容不包含时,需填写校验内容。
自定义参数:是 http 局部的用户自定义参数,会替换脚本中以${变量}的内容。
例:略
文章目录:
DS 1.2.0 使用文档(1/8):架构及名词解释
DS 1.2.0 使用文档(2-3/8):集群规划及环境准备
DS 1.2.0 使用文档(4/8):软件部署
DS 1.2.0 使用文档(5/8):使用与测试
DS 1.2.0 使用文档(6/8):任务节点类型与任务参数设置
DS 1.2.0 使用文档(7/8):系统参数及自定义参数
DS 1.2.0 使用文档(8/8):附录