踏坑采蘑菇的我又来了!我相信很多人在刚刚接触Hadoop的时候,安装就是一大难题,各种报错让人眼花缭乱,实属不易。我今天来说一下Oracle VM VirtualBox下的Ubuntu版本安装hadoop2.7.1的伪分布式。
问题描述:搭建hadoop伪分布式
首先,我简单说一下,目前hadoop环境的搭建大致可划分为四种,单机模式、伪分布式、完全分布式、高可用。如果是刚入门进行hadoop学习的,伪分布模式就足够了。
不管是百度网盘下载的,还是从哪个旮沓弄出来的,hadoop2.7.1安装包要看清楚,版本号不对头,后面全报错。(一定要记住啊!!!每个安装包的版本号之间要查一下是不是兼容)此方法对hadoop2.1版本以上的适用,对2.1版本以下的不适用。话不多说上教程~
解决办法:
1. 先把软件源更改成阿里巴巴的软件源,别问我为什么要改,马云爸爸的软件源,这大腿抱着不香吗?(手动滑稽)跟着我走,不会错的,放心
老规矩同时按下Windows+A打开软件界面

找到软件和更新这个东西,点开它,别点到它旁边的同胞兄弟了,看清楚点
2. 点击中国的服务器

3. 然后点击其他站点
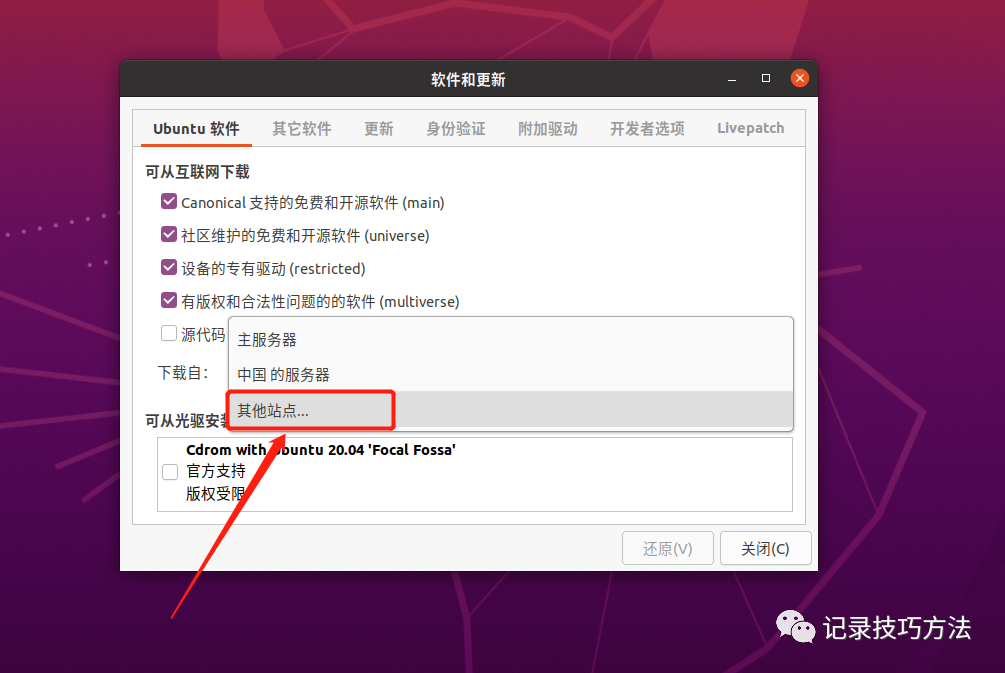
4. 会跳出一些软件源站点给我们选择,都是中国的站点,别点到别的国家去了

5. 拿出你的火眼金睛找到阿里巴巴的软件源服务器,aliyun就是了,选择它!

点击重新载入

要输入自己的登录密码,才能修改,别跟我说自己的登录密码都不晓得哈,我怕我忍不住......笑你,输入完密码之后,就是等它更新软件缓存好就行了

6. 更新完之后,打开命令终端,输入命令sudo apt-get update

密码就是你的登录密码
在这里我多讲一句,Linux里面常用的编辑命令一般是vi、vim和gedit,我喜欢用vim,所以接下来的命令基本上都是vim命令,vi和gedit命令,你们可以看看用法,但具体命令是不会变的
在终端输入sudo apt-get install vim
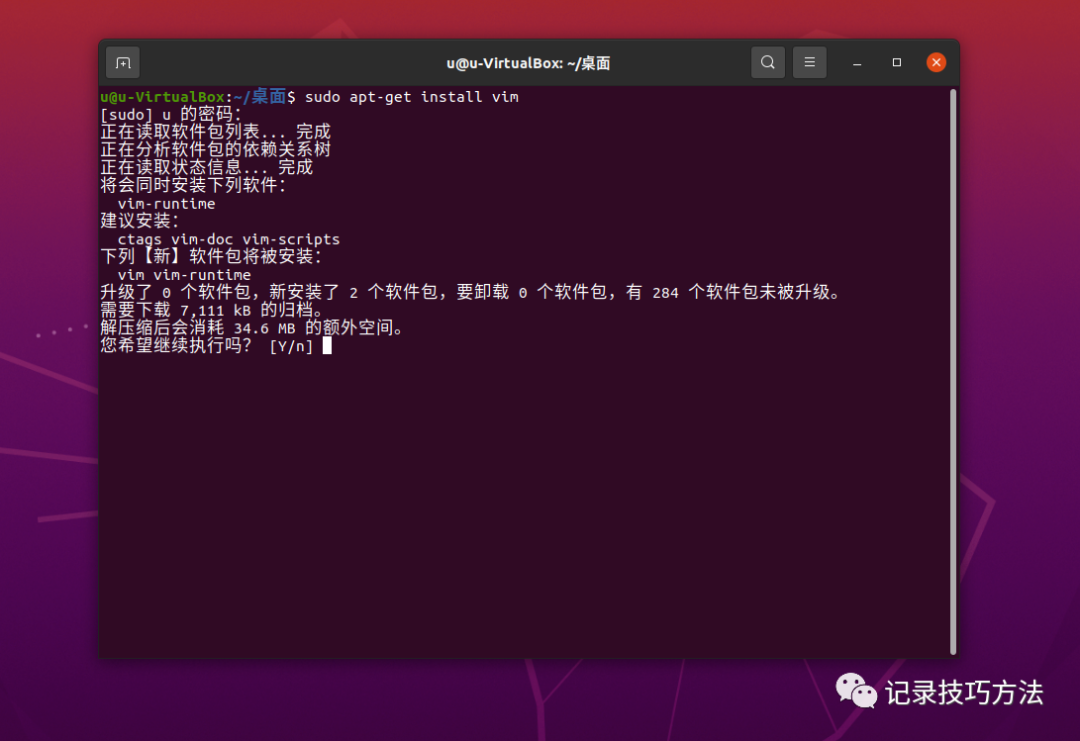
有需要输入Y/N的,无脑输入Y就行
7. 配置SSH免密,不配置免密,每次启动都要输入密码,能把你烦死。在终端输入sudo apt-get install openssh-server
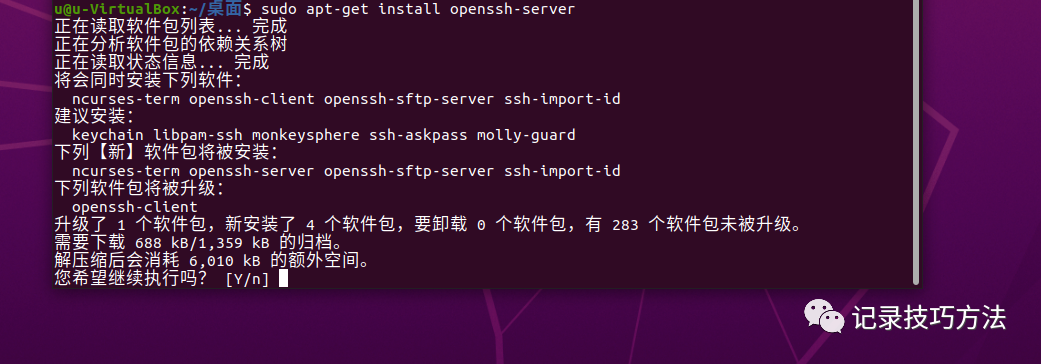
还记得我说的吗,无脑输入Y就行
8. 然后在终端输入ssh localhost,登录主机,要输入yes

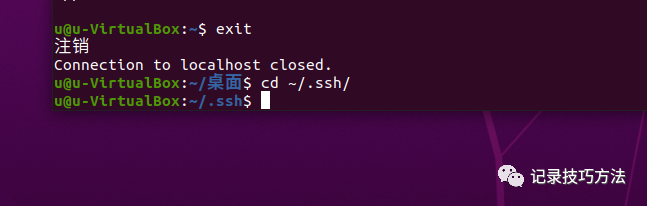
9. 在终端输入exit退出主机

10. 在终端输入cd ~/.ssh/,进入到ssh里面
11. 然后在终端输入ssh-keygen -t rsa,然后无脑按下四次回车,别问,问就是按回车就完事了
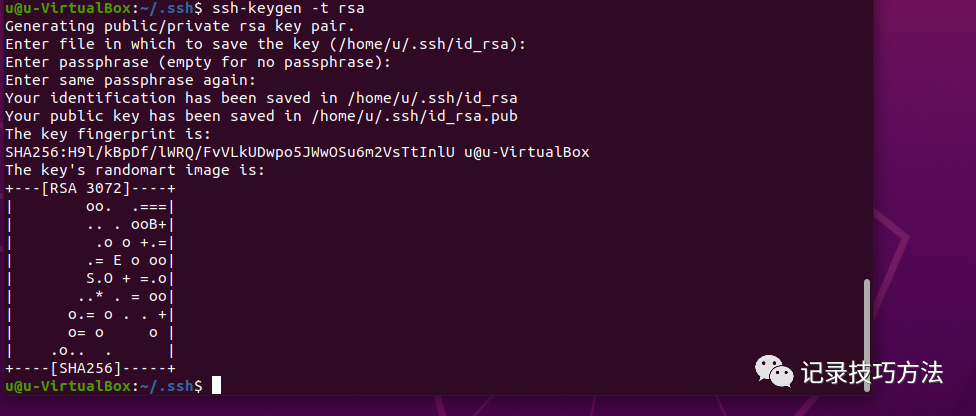
12. 终端输入cat ./id_rsa.pub >> ./authorized_keys,这是加入授权免密
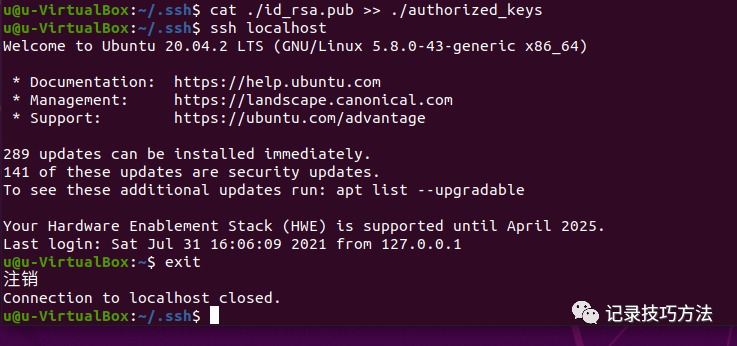
加入授权免密之后,再次输入ssh localhost登录主机,就不要手动输入密码了,记得测试结束之后,exit退出
13. 由于hadoop是基于java来运行的,所以我们要安装jdk,说明一下,不建议用命令直接下载,不然很难找到jdk的具体路径。
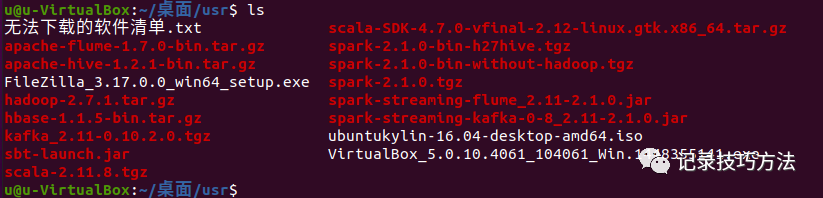
进入你放安装包的那个路径里面,我的存放路径就是~/桌面/usr,直接cd进去
14. 在终端输入sudo tar -zxvf (后面是你jdk安装包的名字)
等待解压
15. 在终端输入ls查看是否解压成功
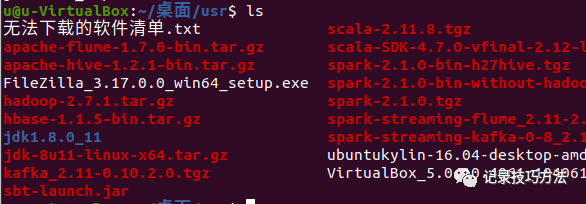
16. 为了方便后续搭建,改成jdk,终端输入sudo mv (解压后的名字)jdk

17. 在终端输入sudo mv jdk /usr/local/src,这是一个移动文件的命令
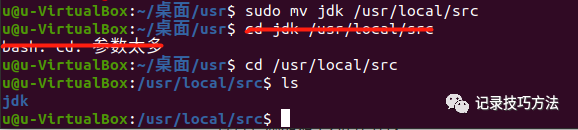
sudo是赋予管理员权限的意思,mv是改文件名或者移动文件,后面的/usr/local/src是路径,要注意绝对路径跟相对路径的区分,自己百度查这两个的区别哈,我就不细说这个了。cd后面跟着路径,就可以进入到路径里面,然后ls查询一下,就可以看到,jdk已经存放到这个路径里面了。
18. 设置jdk的环境变量,先cd回到home,然后输入vim ~/.bashrc

会出现以下的界面
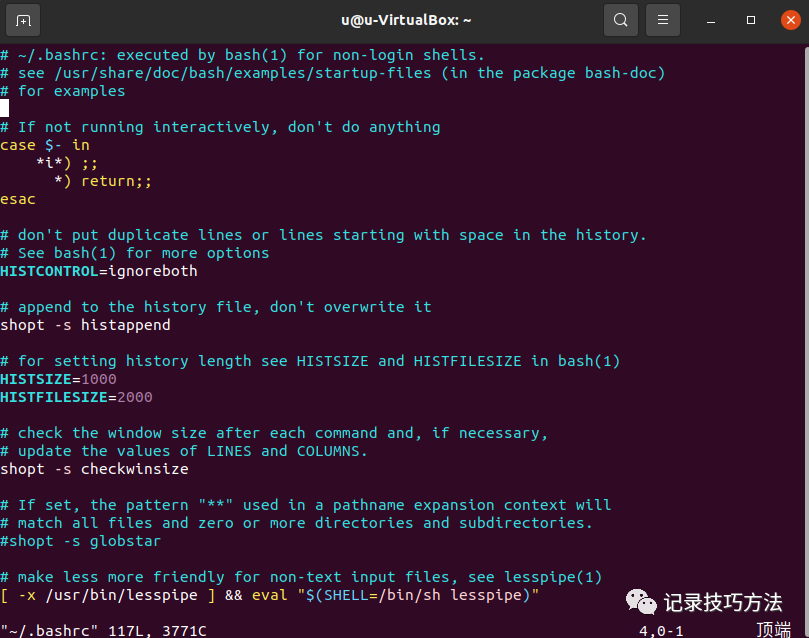
看到这么多代码,是不是有点心慌,别慌稳住,都是唬人的,直接用键盘上的↓键一路下滑到底,记得是最底下
19. 然后键盘上按一下i,解锁插入功能,不然是没有办法,写进代码的
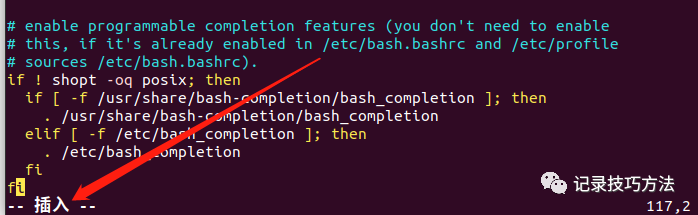
20. 回车换行,最好换三行,区分开来开始输入环境代码
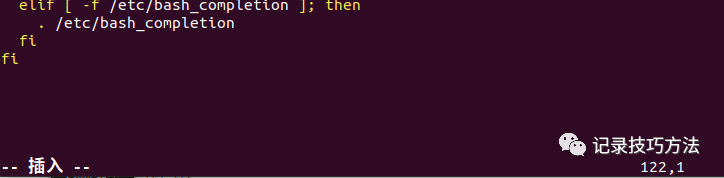
然后输入代码
export JAVA_HOME=/usr/local/src/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
![]()
第一行代码的路径千万千万不要错,你是什么路径就什么路径,然后我建议所有的文件都放到同一个路径里面,方便管理也直接明了
21. 把所有代码输入后,感觉已经没有错误了,就先按一下键盘左上角的Esc键,然后第二步,按下shift再按下:(冒号)

出现这个冒号之后,输入wq,意思是保存退出,还有一个是q!强制退出,不保存

然后敲下回车就ok
22. 终端输入source ~/.bashrc,作用是让刚刚的环境代码生效

23. 终端输入java -version,查看是否安装成功

出现上图中显示的那样,有版本号出现就是配置好了jdk环境,是不是很轻松很棒,别看我现在码字配图很轻松,都是血与泪磨炼出来的,加油!
24. 然后现在是hadoop的配置,cd进入到你存放hadoop安装包的路径里面,终端输入解压命令,tar -zxvf (hadoop安装包的名字)

25. 输入ls查看版本,然后修改成hadoop,步骤跟jdk一样
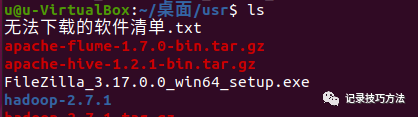

26. 终端输入sudo mv hadoop /usr/local/src 然后输入cd /usr/local/src ,再然后ls查看
![]()
细心的同学应该会发现,jdk去哪了,怎么只有一个hadoop,那是我操作失误,恢复备份了,所以jdk没有了,我待会会重新配置jdk,不影响的,你们的界面应该都是有hadoop和jdk在里面的,如果没有就是,没移动过来,再回头去检查一下路径,有没有马虎大意打错路径的,我经常打错的路径就是local打成了loacl。
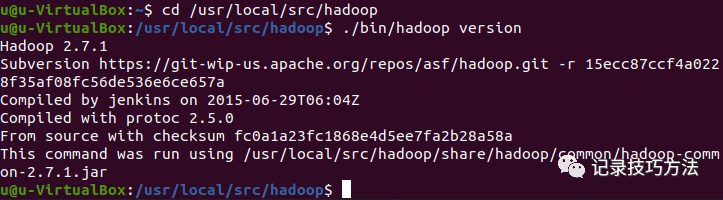
27. 输入cd hadoop 进入hadoop里面,然后再输入./bin/hadoop version即可查看版本号,有版本号出现就是安装好的,当然这只是单机的安装好了,咱们要给它配上环境,才能搭建伪分布式

叮
28. 配置伪分布式环境,在/usr/local/src/hadoop这个路径里面,输入gedit ./etc/hadoop/core-site.xml命令直接修改文件
在下图框选出来的地方输入代码

叮
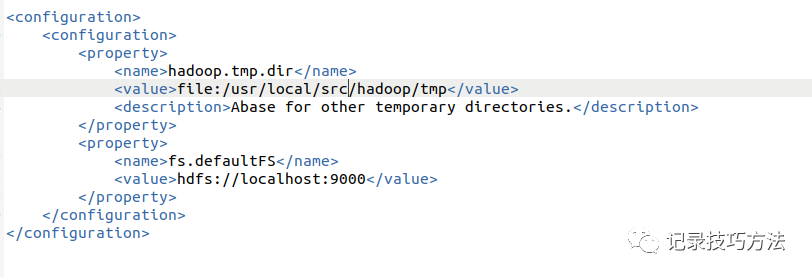
代码如下
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
29. 保存退出
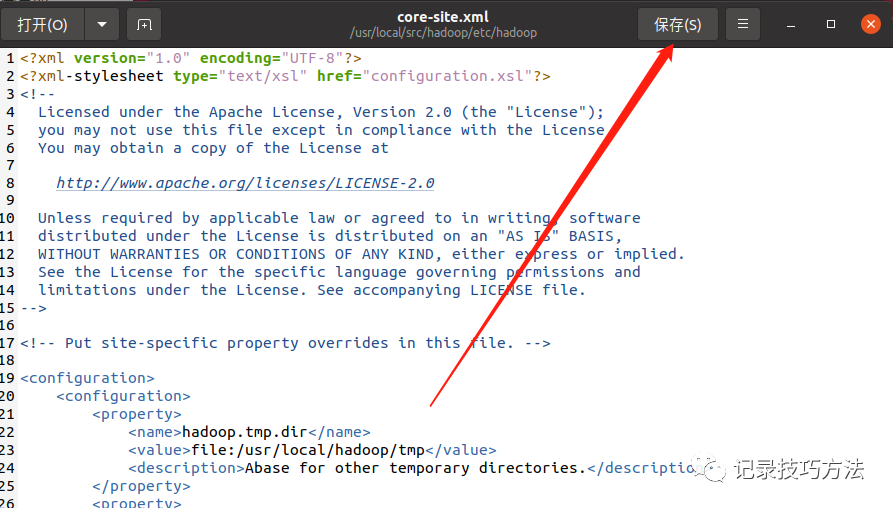
30. 同样再次输入gedit ./etc/hadoop/hdfs-site.xml命令直接修改文件

叮
老规矩,在框选出来的中间输入代码
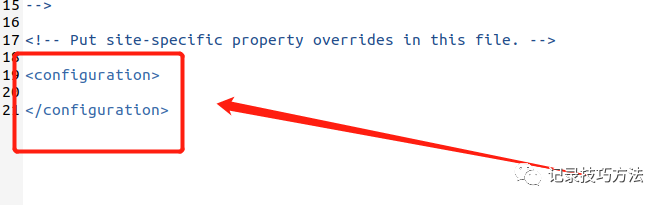
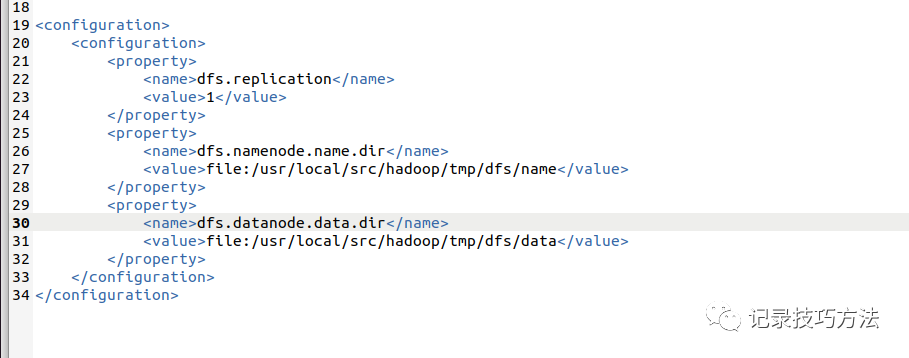
代码如下
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/tmp/dfs/data</value>
</property>
</configuration>
保存退出千万不要忘记,还有格式也不要出错,多一个空格都有可能运行错误
31. 终端输入格式化命令./bin/hdfs namenode -format

格式化完成,出现下面框选出来的情况,就是配置成功了
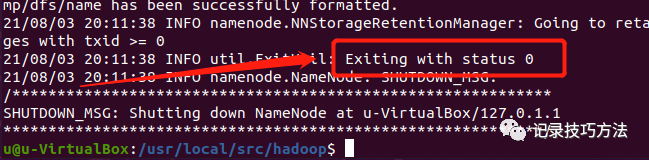
如果数字不是0,是其他数字,恭喜你成功配置错误,你就乖乖把整个hadoop全部删除,重新解压缩,再来一遍流程,hhhh,万事小心点呐!
32. 格式化成功之后,就是启动了,输入./sbin/start-dfs.sh

启动完成之后,用jps查询有没有如下进程
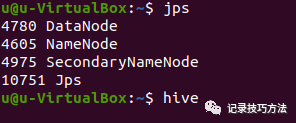
有的话就百分之九十没问题,然后剩下的百分之十要用浏览器去验证有没有成功,点击左上角的浏览器
输入网址:http://localhost:50070/,出现以下界面
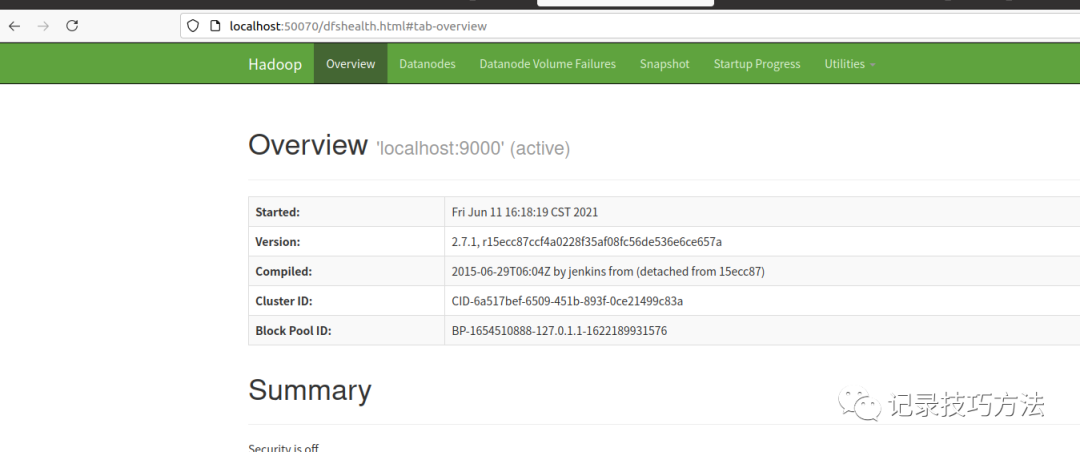
现在就已经完完全全配置好hadoop伪分布式了,good!
记得记得,每做一个步骤一定要备份拍快照,不然有你后悔的时候
因为励志写最全面的小白安装流程,所以篇幅有些大,请耐心看完,每个步骤,我都是一步步做好验证过,然后实时截图的,为的就是后来者不踩坑!