近期,PaddleOCR开源了媲美商业效果的3.5M超轻量中英文OCR模型。直接先看看效果。

上述效果如何做到的,主要采用了PP-OCR方案,repo也提供了其详细技术方案。
GitHub地址: https://github.com/PaddlePaddle/PaddleOCR
PP-OCR技术文章地址:https://arxiv.org/abs/2009.09941
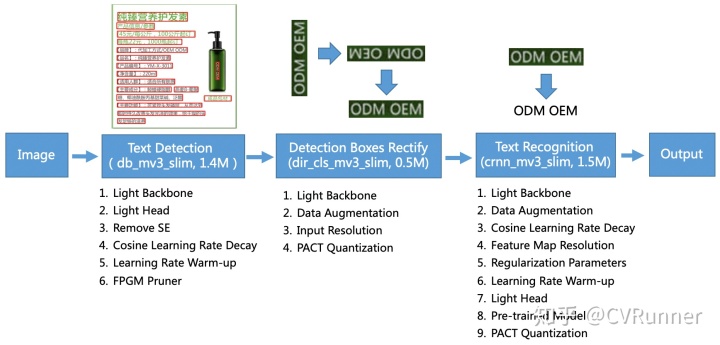
PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身,最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。PP-OCR的框架图如下,论文中有大量的在中文真实数据上消融实验。
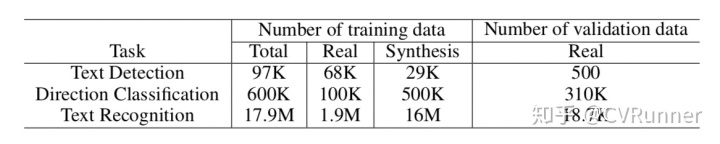
训练3.5M的模型,文字检测使用了将近10w的数据,方向分类器使用了60w的数据,文字识别使用了将近2千万的数据,大数据加持,所以效果喜人。使用的数据详细情况如下:
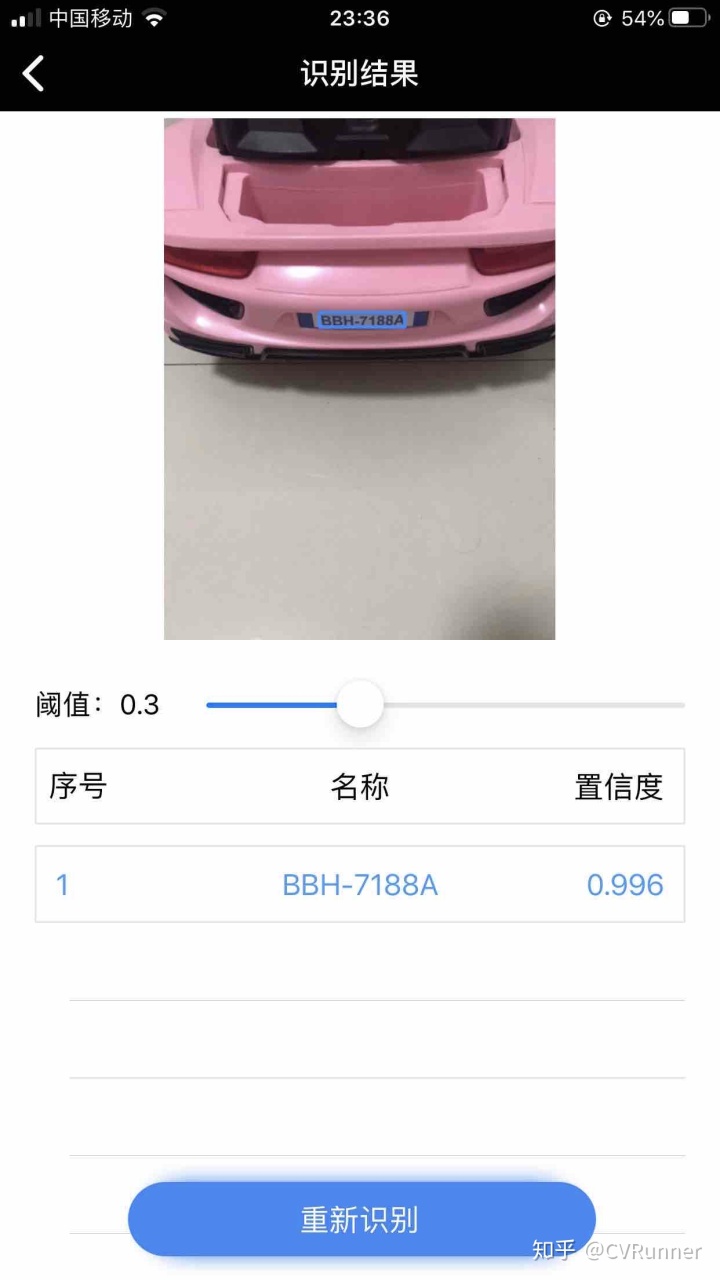
此外,PaddleOCR中还提供了iOS和Android系统上的DEMO,可以直接用手机安装体验效果。下图是小编用手机demo测试的一些case,秒出结果:

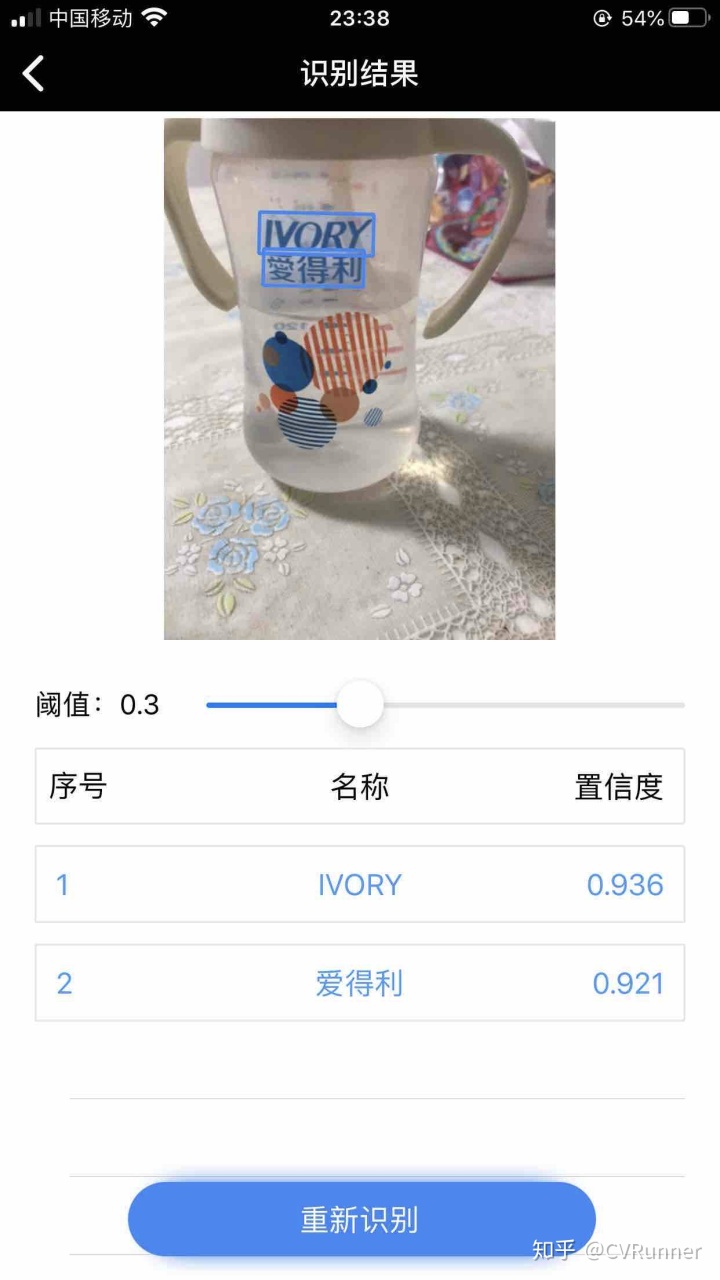
本文转自:CVRunner:3.5M 超轻量中英文OCR模型开源,效果非常赞,如有侵权请联系删除
版权声明:本文为weixin_35626356原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。