文章目录
之前我们基于已经Reactor模型实现了一个简单的websocket服务器,在此基础上再实现一个简单的HTTP服务器小框架。实际上,最终我们会实现一个支持websocket的HTTP服务器。具体功能包括:首先要实现GET html页面、图片、pdf文档等;其次是实现POST方法并完成一个简单的表单提交功能。
实现GET方法
关于HTTP报文的消息结构都包含哪些元素可以参考这里。
一个GET请求报文的示例如下:
GET /index.html HTTP/1.1
Host: 192.168.0.103
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
GET方法没有消息体,因此不需要解析其请求数据,只需解析其开头的请求行和请求头部。
对应的响应报文实例如下:
HTTP/1.1 200 OK
Date: Sat, 13 Nov 2021 02:13:47 GMT
Content-Type: text/html;charset=utf-8
Content-Length: 253
<!DOCTYPE html>
<html>
<head>
<title>Title</title>
</head>
<body>
<h1>This is an awesome HTML</h1>
</body>
</html>
也很简单,按格式构造状态行和必要的消息头后,再间隔一个空行并发送页面数据就可以了。这里的数据可能是由代码构造的html文本,也可能是一个文件,比如jpg格式的图片或pdf文档。因此,必须通过Content-Type指定消息体的格式客户端才能识别,同时指定Content-Length后客户端才能知道需要接收多少数据。
约定GET时URI的格式
GET方法一般是用于请求某一个具体的页面或文件资源,当然也可以用于获取XML或JSON格式的数据。为了简单起见,我们目前在做URI资源名称的解析时,仅支持GET方法请求服务器上已存在的文件资源,暂时包括.html、jpg、.pdf、ico四种。这些资源都单独放在程序工作目录下的一个public/目录下,但我们规定GET报文的URI中不需要体现public目录,比如请求index.html页面,那么开头的请求行只需这么写即可:GET /index.html HTTP/1.1,由程序自动转换为去获取public/index.html文件。
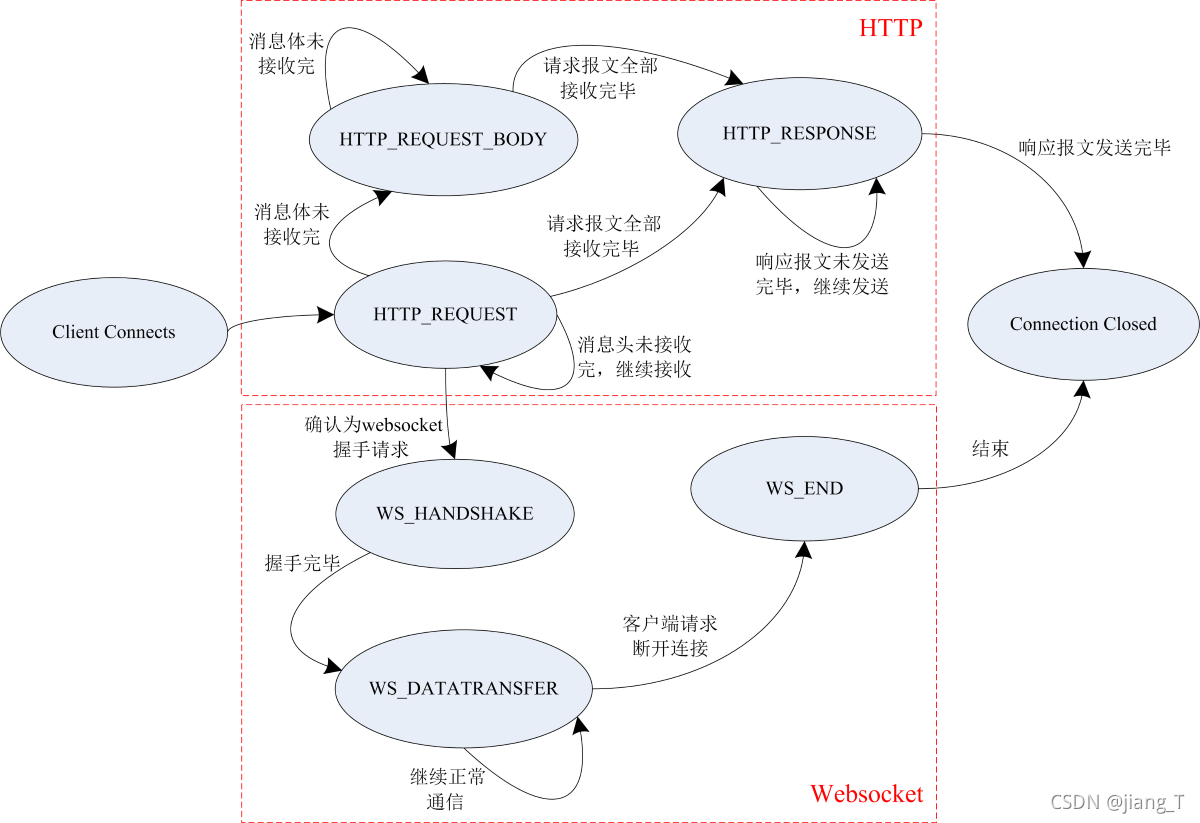
状态机与websocket协议兼容
为了兼容之前的websocket协议,我们需要先增加虚拟机中的状态以实现HTTP的请求和接收。
显然websocket协议的握手过程也属于HTTP请求与响应的一部分,二者都是使用GET方法进行请求,我们只需根据请求报文的头部来判断这是不是一个websocket握手请求,如果是则执行websocket握手过程的响应代码,如果不是则执行普通HTTP协议的响应代码。这里先简单地以头部中是否含有``字段来识别是否为websocket的握手请求,大致代码思路如下:
/* 根据方法进行处理并设置下一个状态 */
switch(http->req.method)
{
case HTTP_METHOD_GET:
if(strlen(http->ws.ws_key) > 0) // 获取到了websocket的key,进行 websocket 握手
{
ret = ws_handshake(http);
http->status = WS_DATATRANSFER; // 握手后则进入通信状态
}
else // 否则按普通 http 请求处理
{
ret = http_request_get(http);
http->status = HTTP_RESPONSE; //
}
break;
.......
状态机实现的大致思路如下图所示:
实现几个辅助函数
开始HTTP请求与响应的主体代码编写前,需要先实现一些辅助函数。此处仅列出几个比较关键的辅助函数,主要位于HTTP协议相关的模块代码。
1)解析消息头,获取方法、URI以及需要的头部字段。由于HTTP协议中消息头的结束标志位是一个空行,因此我们用\r\n\r\n作为消息头的结束字符串。在读取到\r\n\r\n前,我们不知道头部到底有多长。对此我在代码中作简单处理,为消息头部专门使用一个缓冲区,指定一个最大头部长度,如果头部接收过程中缓冲区已满却还没有收到结束符\r\n\r\n,则返回错误。
/* 解析消息头,获取方法、URI以及需要的头部字段 */
static int http_resolveReqHeader(http_service_interface *http)
{
if(http == NULL) return -1;
char linebuf[256];
char* value;
int level = 0;
int ret;
/* 1 - 从第1行提取出http方法*/
memset(linebuf, 0, 256);
level = readline(http->req.header, level, linebuf);
if(strstr(linebuf, "GET"))
http->req.method = HTTP_METHOD_GET;
else if(strstr(linebuf, "POST"))
http->req.method = HTTP_METHOD_POST;
else if(strstr(linebuf, "PUT"))
http->req.method = HTTP_METHOD_PUT;
else
http->req.method = HTTP_METHOD_NOTALLOWED; // 从第一行提取不到方法或不支持的方法
/* 2 - 尝试提取请求的资源路径 */
if(value = strchr(linebuf, '/'))
{
memset(http->req.resource, 0, HTTP_MAX_RESOURCE_NAME);
ret = http_getResourceName(http->req.resource, HTTP_MAX_RESOURCE_NAME, value + 1);
if(ret >= 0) printf("# resource requested[%d]: %s\n", ret, http->req.resource);
}
/******* 3 - 提取可能有用的头部字段 *******/ // this piece of code is awful, but I will improve it
/* 都需要提取哪些头部字段目前通过手动加到这里 */
// 3.1 尝试提取 ws 的key字段,后面依次判断是否进行 ws 握手
ret = http_getHeaderValueString(http->req.header, "Sec-WebSocket-Key", http->ws.ws_key);
if(ret >= 0) printf("# WS key[%d]: %s\n\n", ret, http->ws.ws_key);
// 3.2 尝试提取 Content-Length 字段
if(http->req.method != HTTP_METHOD_GET)
{
ret = http_getHeaderValueInt(http->req.header, "Content-Length", &http->req.contentlength);
if(ret >= 0 && http->req.contentlength > 0)
{ // 根据消息体长度申请一块堆内存来单独存放消息体,此处暂不管申请是否成功
http->req.body = (char*)malloc(http->req.contentlength + 1); // 加1若需要的话作为结束符
if(http->req.body)
memset(http->req.body, 0, http->req.contentlength + 1);
printf("# Content Length[%d]: %d\n\n", ret, http->req.contentlength);
}
}
/****************************************/
return 0;
}
/* 获取 string 型头部字段 */
static int http_getHeaderValueString(const char* buffer, const char* name, char* value)
{
char* tmp;
char linebuf[256];
int level = 0;
do
{
memset(linebuf, 0, 256);
level = readline(buffer, level, linebuf);
if(strlen(linebuf) == 0) // 读到空行则http头部全部解析完毕
break;
if(tmp = strstr(linebuf, name))
{
if(tmp = strchr(tmp, ':'))
{
tmp++; // 跳过':'
tmp = trim(tmp); // 消除首尾空格
strcpy(value, tmp);
return strlen(value); // 找到返回值的长度
}
}
} while (level != -1);
return -1; // 没找到则返回-1
}
/* 获取 int 型头部字段 */
static int http_getHeaderValueInt(const char* buffer, const char* name, int* value)
{
if(value == NULL) return -1;
char valueString[128] = {0};
int ret = http_getHeaderValueString(buffer, name, valueString);
if(ret < 0) return -1;
*value = atoi(valueString);
return 0;
}
/* 提取从'/'开始之后资源名,以空格作为结束 */
static int http_getResourceName(char* buffer, int buflen, char* input)
{
if(buffer == NULL || input == NULL)
return -1;
char* p = input;
int bufIdx = 0;
while(*p && *p != ' ' && bufIdx < buflen)
{
buffer[bufIdx] = *p;
p++;
bufIdx++;
}
if(*p == '\0' || bufIdx == buflen)
{
buffer[0] = '\0';
return -1;
}
buffer[bufIdx] = '\0';
return bufIdx;
}
2)不同的文件类型需要指定不同的Content-Type,这里我们根据客户端请求之资源的文件名后缀来自动匹配对应的Content-Type。如果需要增加其他文件类型,则在数组filetypes[]中增加元素即可。
#define HTTP_CHAR_SET "utf-8"
struct filetype_pair
{
char *file_suffix;
char *content_type;
};
enum HTTP_CONTENT_TYPE
{
HTTP_CONTENT_TYPE_HTML = 0,
HTTP_CONTENT_TYPE_JPG,
HTTP_CONTENT_TYPE_PDF,
HTTP_CONTENT_TYPE_ICO,
};
static struct filetype_pair filetypes[] =
{
{HTTP_CONTENT_TYPE_HTML, ".html", "text/html;charset="HTTP_CHAR_SET},
{HTTP_CONTENT_TYPE_JPG, ".jpg", "image/jpeg"},
{HTTP_CONTENT_TYPE_PDF, ".pdf", "application/pdf"},
{HTTP_CONTENT_TYPE_ICO, ".ico", "image/x-icon"}
};
#define HTTP_FILE_TYPE_NUM (sizeof(filetypes) / sizeof(struct filetype_pair))
/* 从请求文件名末尾提取其后缀,再根据后缀去匹配相应的 Content-Type */
static char* http_getContentTypeByResourceName(const char* _resource)
{
char* resource = strrchr(_resource, '.'); // 从后往前的第一个 . 字符开始就是后缀
if(!resource)
return NULL;
return http_getContentTypeBySuffix(resource);
}
/* 根据后缀匹配content-type */
static char* http_getContentTypeBySuffix(const char* suffix)
{
int i;
for(i = 0; i < HTTP_FILE_TYPE_NUM; i++)
{
if(strcmp(suffix, filetypes[i].file_suffix) == 0)
return filetypes[i].content_type;
}
return NULL; // 没有匹配的类型则返回NULL
}
3)发送完整的文件。发送一个较大的文件时,调用一次sendfile()可不能保证所有数据都发出去了,因此需要进行处理,确保文件内容全部发送。
int sendWholeFile(int outfd, int infd, int size)
{
int left = size;
int ret = 0;
while(left > 0)
{
ret = sendfile(outfd, infd, NULL, left);
if(ret < 0)
{
if(errno == EWOULDBLOCK || errno == EAGAIN || errno == EINTR)
{
usleep(200);
continue;
}
return ret; // error
}
left -= ret;
}
return size;
}
4)获取当前GMT格式的时间字符串用以填到响应报文的头部的Data字段。
int getGmtTime(char* szGmtTime, int len)
{
if (szGmtTime == NULL)
return -1;
time_t rawTime;
struct tm* timeInfo;
time(&rawTime);
timeInfo = gmtime(&rawTime);
strftime(szGmtTime, len, "%a, %d %b %Y %H:%M:%S GMT", timeInfo);
return strlen(szGmtTime);
}
GET请求一个html页面、一张图片或一个PDF文件
处理GET请求的函数如下:
static HTTP_CODE http_response_get(http_service_interface *http)
{
int ret = 0;
int fd = -1;
if(strlen(http->req.resource) == 0) // 资源为空表示请求根目录,则返回 index.html
strcpy(http->req.resource, HTTP_INDEX_PAGE);
char filepath[HTTP_MAX_RESOURCE_NAME] = {0};
http_getFilePath(filepath, HTTP_MAX_RESOURCE_NAME - 1, http->req.resource); // 将资源名加上目录构成本地的文件路径
fd = open(filepath, O_RDONLY);
if(fd < 0)
{ // 没有这个文件或目录,注意open以只读方式可以打开目录的
return HTTP_CODE_NOTFOUND;
}
struct stat filestat;
fstat(fd, &filestat);
if(S_ISREG(filestat.st_mode)) // 如果是普通文件,则返回 200 并发送文件
{
char* contentType = http_getContentTypeByResourceName(http->req.resource); // 获取文件类型
ret = http_packOKRespHead(http->buffers.sendBuffer, contentType, filestat.st_size);
ret = send(http->sockfd, http->buffers.sendBuffer, ret, 0); // 先发头部
ret = sendWholeFile(http->sockfd, fd, filestat.st_size); // 再发文件内容
}
else
{ // 其他类型的资源不允许访问,返回 404
return HTTP_CODE_NOTFOUND;
}
if(fd > 0)
close(fd);
return HTTP_CODE_OK;
}
我们在程序的运行目录下新建一个目录public,将可以通过GET请求的文件资源都放在下面: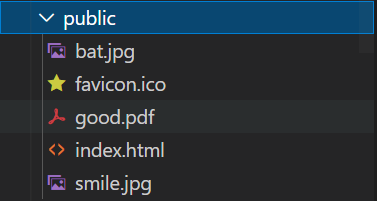
其中favicon.ico是页面的图标。index.html将是我们的默认主页。
程序运行后如果不指定端口则默认使用80端口。确认程序正确运行后,我们在浏览器输入服务器的IP地址,即可弹出如下的页面。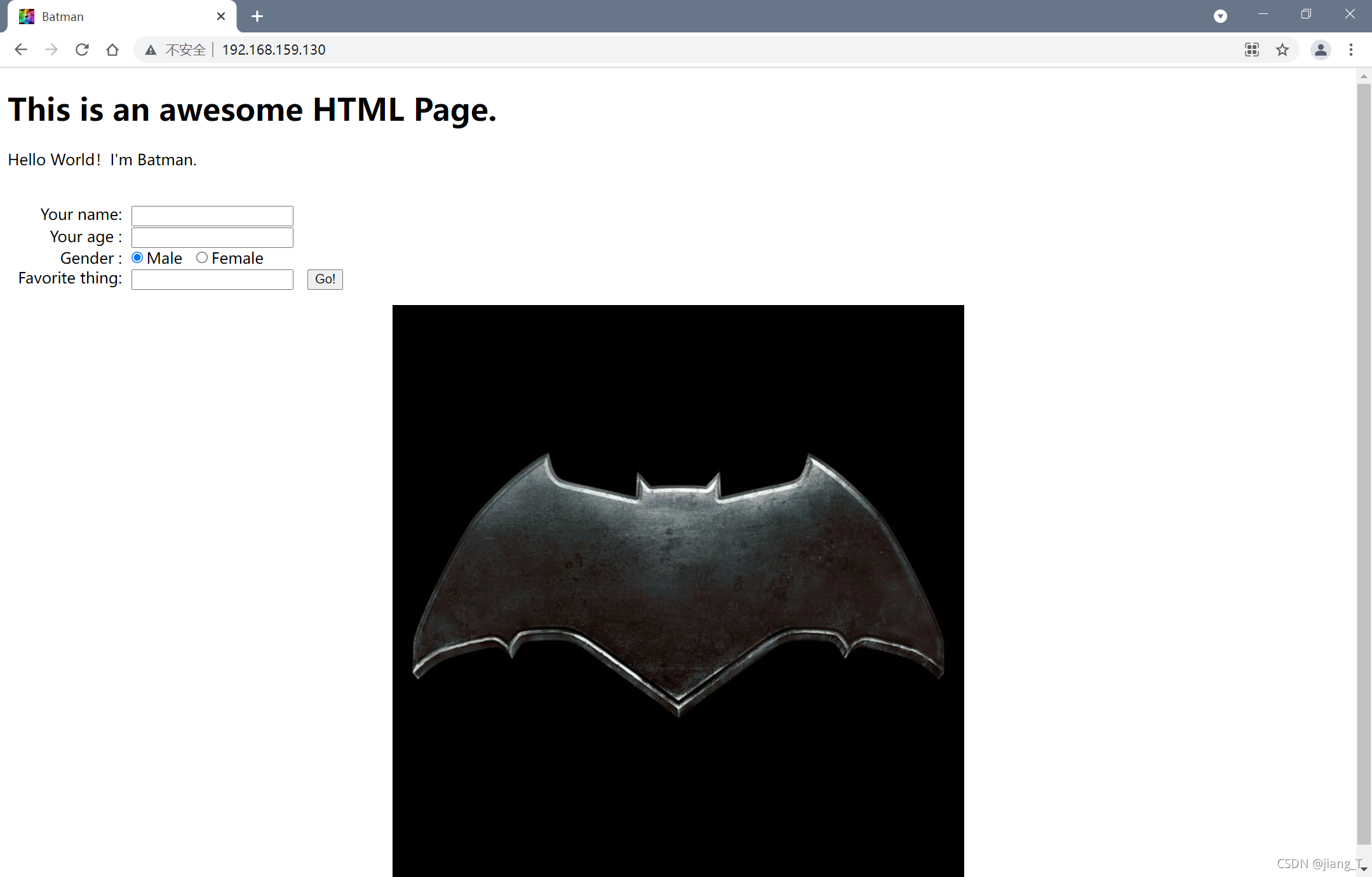
通过调试打印可以看到,此时这个页面除了请求主页html之外,同时还请求了一个ico图标以及一个.jpg图片。如果我们请求http://192.168.159.130/good.pdf这个URI则会打开一个PDF文件。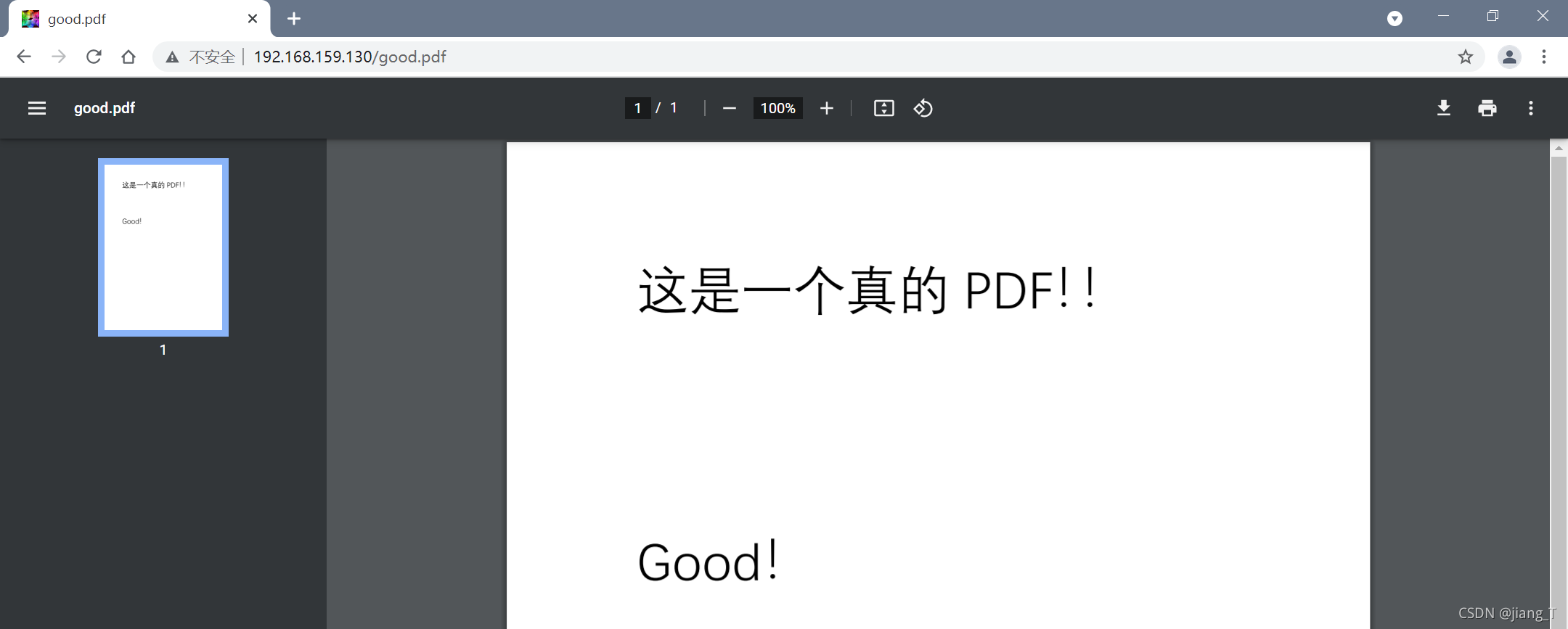
实际上我们在消息体中直接发送了整个PDF文件,而浏览器通过响应报文头部中Content-Type字段知道了这是一个PDF文件,因此就能将其正确地解析出来。如果响应时不指定Content-Type,你将会看到浏览器显示出一大段乱码。
实现POST方法
一个POST方法请求报文的示例如下,除了与GET方法差不多的部分外,由于POST带有消息体,因此我们比较关注的是Content-Length和Content-Type。
POST /service/putInfo HTTP/1.1
Host: 192.168.0.103
Connection: keep-alive
Content-Length: 36
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://192.168.0.103
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://192.168.0.103/
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9,zh;q=0.8,zh-TW;q=0.7,zh-CN;q=0.6
name=JJ&age=23&sex=male&favorite=hat
为了测试POST的实现,我们完成这样一个小功能:使用一个表单提交几条信息,然后服务器跳转到另一个页面并将相关信息显示出来。
实现一个简单的服务框架
在我的理解中,POST请求的资源往往对应着某种服务,URI指定了服务的名称,并且在请求体中带上了调用服务所需提交的数据,数据的格式可能是HTTP的标准参数格式如xxx=n&yyy=m&zzz=l(POST提交表单数据默认就是这样),也可能是XML或JSON格式的报文,具体由Content-Type字段来判断;服务器根据URI调用对应的服务函数,处理客户端提交的数据并且将响应报文返回。一样的,客户端将根据响应报文头部的Content-Type来对内容进行解析。
为了便于往我们的框架中添加新的服务,我们定义一个标准服务函数的原型如下:
typedef HTTP_CODE (*SERVICE_FUNC)(const struct http_req* req, struct http_resp* resp);
同时定义一个http_service类,其成员是请求服务时的URI字符串service_path与对应的服务函数指针serve。当我们需要增加一个服务的实例时,只需将服务函数与对应的URI成对地添加到 services[]数组中,然后实现服务函数即可。
struct http_service
{
const char* service_path;
const SERVICE_FUNC serve;
};
/* 将服务函数与对应的服务 URI 成对地添加到 services[] 数组中,然后实现服务函数即可 */
static const struct http_service services[] =
{
{"service/putInfo", service_putInfo}, // 示例,请求URI为 service/putInfo, 调用的服务函数名为 service_putInfo
};
最后实现一个函数来匹配请求的URI和服务类实例。在HTTP请求处理的代码中,如果判断到请求的是服务而不是文件,则调用该函数获取到服务类的实例,并回调服务函数。
const struct http_service* http_service_findServiceEntry(const char* resource)
{
if(resource == NULL) return NULL;
int i;
for(i = 0; i < HTTP_SERVICE_NUM; i++)
{
if(strcmp(services[i].service_path, resource) == 0)
return &services[i];
}
return NULL;
}
POST请求报文处理的代码块
实现POST请求处理的代码主要任务是确保把消息体中的所有数据都读取到缓冲区中,由于我们获取到Content-Length后才知道消息体到底有多大,因此我们需要为消息体单独指定一个堆缓冲区,其大小根据Content-Length来申请。
此外,消息体的数据有可能需要多次接收才能全部收完(头部也是一样的)。因此我们定义这个结构体以辅助完成多次读的过程:
struct http_helper
{
char* startOfBody; // 当前缓冲区中,从哪个地址开始都是消息体的数据,用于作为头部和消息体的分界线
int recvHeaderLen; // 已接收到的消息头长度
int recvBodyLen; // 已接收到的消息体长度
};
于是实现POST请求报文处理的代码块如下:
static int http_request_post_put(http_service_interface *http)
{
if(http->req.contentlength >= HTTP_MAX_BODY_LEN)
{
http->resp.code = HTTP_CODE_NOT_ACCEPTABLE;
return -1;
}
else if(http->req.contentlength > 0) // POST 有消息体
{
if(http->req.body != NULL && http->helper.startOfBody != NULL)
{
int resBodyLen = http->buffers.recvBuffer + http->buffers.recvLength - http->helper.startOfBody; // 剩下可读的消息体长度
memcpy(http->req.body + http->helper.recvBodyLen, http->helper.startOfBody, resBodyLen); // 拷贝消息体数据
http->helper.recvBodyLen += resBodyLen;
if(http->helper.recvBodyLen < http->req.contentlength)
{ // 接收到的消息体长度尚小于Content-Length,需要继续接收
http->helper.startOfBody = http->buffers.recvBuffer;
return 1;
}
http->req.body[http->req.contentlength] = '\0';
http->helper.startOfBody = NULL;
}
else
{ // 有消息体长度但之前却没有成功申请到足够的内存,返回内部错误
http->resp.code = HTTP_CODE_INTERNAL_SERVER_ERROR;
}
}
// 若没有消息体则不需要处理
return 0;
}
由于PUT方法也带有消息体,因此实际上二者的请求报文处理流程是一样的。
POST响应报文处理的代码块
基于我们设计的服务框架,POST响应报文的处理就很简单了,因为主要任务都放到了服务函数中,由服务的提供者去实现。
static HTTP_CODE http_response_post(http_service_interface *http)
{
HTTP_CODE code;
int ret = 0;
const struct http_service* service = http_service_findServiceEntry(http->req.resource); // 匹配服务类实例
if(service)
code = service->serve(&http->req, &http->resp); // 调用服务函数
else
return HTTP_CODE_NOTFOUND; // 错误报文在外面统一处理
ret = http_packOKRespHead(http->buffers.sendBuffer, http_getContentTypeByEnum(http->resp.contentType), http->resp.contentlength);
send(http->sockfd, http->buffers.sendBuffer, ret, 0);
if(http->resp.body && http->resp.contentlength > 0)
{
ret = send(http->sockfd, http->resp.body, http->resp.contentlength, 0);
printf("# resp body[%d]: %s\n", ret, http->resp.body);
}
return code;
}
POST提交一个表单
此处我们实现一个简单的POST表单提交操作,在/index.html页面我们填入如下数据:
点击提交按钮后,POST请求的消息体将带有如下参数:
name=Wayne&age=21&sex=male&favorite=Batcar
该服务的URI是service/putInfo,对应的服务函数是service_putInfo:
HTTP_CODE service_putInfo(const struct http_req* req, struct http_resp* resp)
{
int ret;
resp->body = (char*)malloc(1024);
memset(resp->body, 0, 1024);
char name[32] = {0};
int age;
char numsfx[3] = {0};
char sex[8] = {0};
char favorite[128] = {0};
char buf[128] = {0};
printf("# service - post body: %s\n", req->body);
http_getValueFromReqBody(name, 32, "name", req->body);
http_getValueFromReqBody(buf, 128, "age", req->body);
age = atoi(buf);
strcpy(numsfx, "th");
if(age / 10 != 1)
{
if(age % 10 == 1)
strcpy(numsfx, "st");
else if(age % 10 == 2)
strcpy(numsfx, "nd");
else if(age % 10 == 3)
strcpy(numsfx, "rd");
}
http_getValueFromReqBody(buf, 128, "sex", req->body);
if(strcmp(buf, "male") == 0)
strcpy(sex, "Mr.");
else strcpy(sex, "Ms.");
http_getValueFromReqBody(favorite, 128, "favorite", req->body);
ret = sprintf(resp->body,
"<html><head><title>Info</title></head>"
"<body><p style=\"text-align: center;text-align: center;font-size:100px\">Hi! %s%s, you will get a %s on your %d%s birthday.</p>"
"<p style=\"text-align: center;\"><img src=\"/smile.jpg\"></p></body></html>\r\n\r\n",
sex, name, favorite, age, numsfx);
resp->contentLength = ret;
resp->contentType = HTTP_CONTENT_TYPE_HTML;
return HTTP_CODE_OK;
}
服务函数主要是解析请求体并构造响应报文,报文体填入resp->body缓冲区,并正确设置resp->contentlength和resp->contentType。客户端浏览器接收到响应报文后解析为页面如下:
完整源代码
完整源码已上传到github地址:VerySimpleHttpServer。“完整”源代码目前并不完整,后续继续完善。
后记:一个缓冲区溢出问题的排查
调试过程中遇到了一个奇怪的问题:当开启服务器并进行websocket连接测试时,接收到握手报文并要发送响应报文前出现了如下打印,整个程序挂掉了:
httpserver: malloc.c:2401: sysmalloc: Assertion `(old_top == initial_top (av) && old_size == 0) || ((unsigned long) (old_size) >= MINSIZE && prev_inuse (old_top) && ((unsigned long) old_end & (pagesize - 1)) == 0)' failed.
Aborted
malloc的断言处失败导致程序被终止了。这还是第一次遇到,初步定位到是base64_encode()函数中申请堆内存时失败。于是将base64_encode()函数的调用处注释掉,此时由于返回的Sec-WebSocket-Accept字段不正确,显然客户端会断开连接。但服务端关闭连接并释放资源时却出现double free:
# [0]client disconnected...
double free or corruption (out)
Aborted
检查了一下程序,逻辑上不可能出现对同一块堆内存重复调用free()的情况。于是查了一下资料,发现出现这种现象一般是两个情况引起的:1)确实重复释放堆内存了;2)存在堆内存溢出。心中暗喜,ASAN终于可以派上用场了。
于是在编译时增加ASAN相关编译选项-fsanitize=address -fsanitize-recover=address:
export ASAN_OPTIONS=halt_on_error=0:use_sigaltstack=0:detect_leaks=1:malloc_context_size=15
gcc epollTest_http.c -lcrypto -o httpserver -fsanitize=address -fsanitize-recover=address -g
再次运行程序复现问题后输出如下: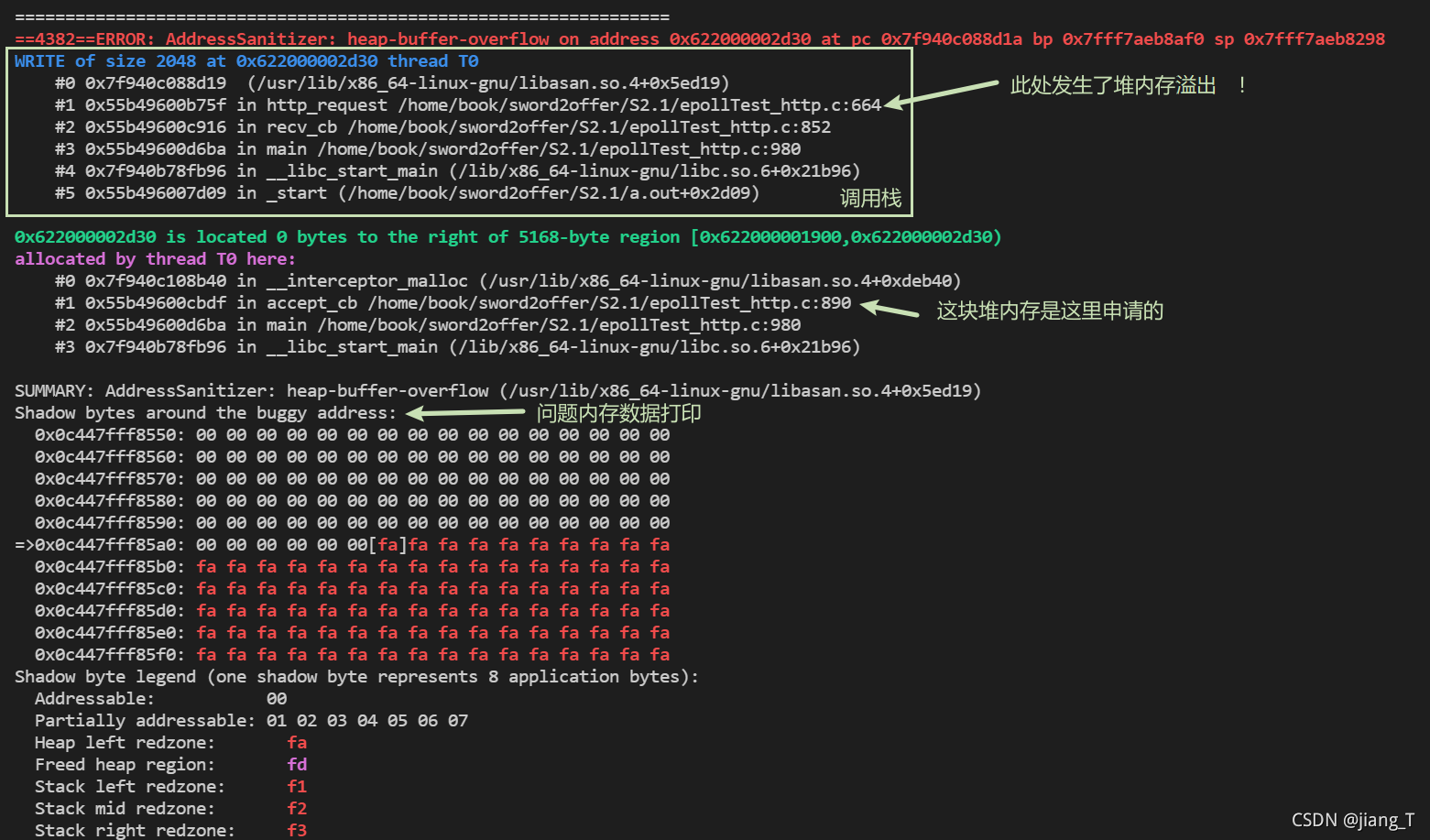
从输出中很快就能定位到问题代码所在,确实是一处错误代码导致了堆内存溢出,因为我在调用memset对堆内存数据进行清0时,使用了错误的宏定义来指定内存的长度,导致memset作用范围超出了正确的地址。?