
关注公众号,获取更多一线大厂最新资讯!

摘要:今天分享的主要内容是ClickHouse在苏宁用户画像场景的实践
分享时间:2021年5月26日
内容分享:杨兆辉
摘要整理:皮卡丘
主要内容:
苏宁如何使用ClickHouse
ClickHouse集成Bitmap
用户画像场景

ClickHouse
ClickHouse是一个面向联机分析处理(OLAP)的开源的面向列式存储的DBMS,简称CK, 与Hadoop, Spark相比,ClickHouse很轻量级,由俄罗斯第一大搜索引擎Yandex于2016年6月发布, 开发语言为C++
一、如何使用ClickHouse
1.选择Clickhouse的原因
2.精准去重计数性能测试
3.Clickhouse在苏宁使用场景
1.1.1 选择Clickhouse的原因:
1. 速度快
2. 特性发布快(产品更新迭代频率高)
3. 软件质量高
4. 物化视图
5. 高基数查询
6. 精准去重计数(count distinct)
1.2.1 精准去重计数性能测试:
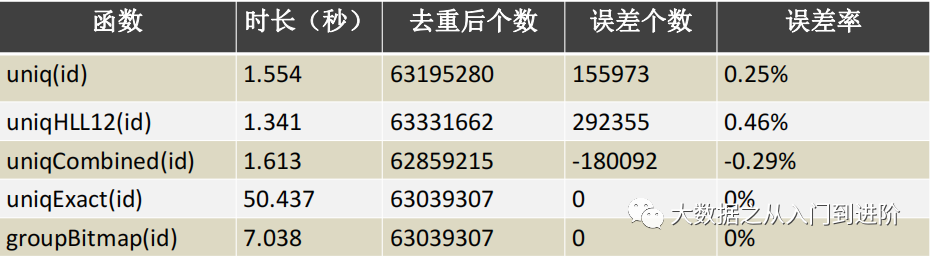
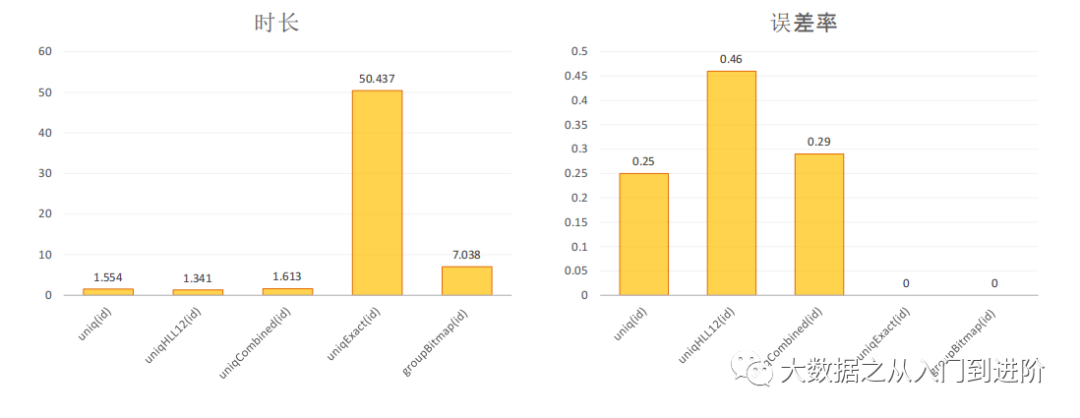
4亿多的数据集上,去重计算出6千万整形数值,
非精准去重函数:uniq、uniqHLL12、uniqCombined
精准去重函数:uniqExact、groupBitmap
结论:
整形值精确去重场景,groupBitmap 比 uniqExact至少快 2x+
groupBitmap仅支持整形值去重, uniqExact支持任意类型去重
非精确去重场景,uniq在精准度上有优势
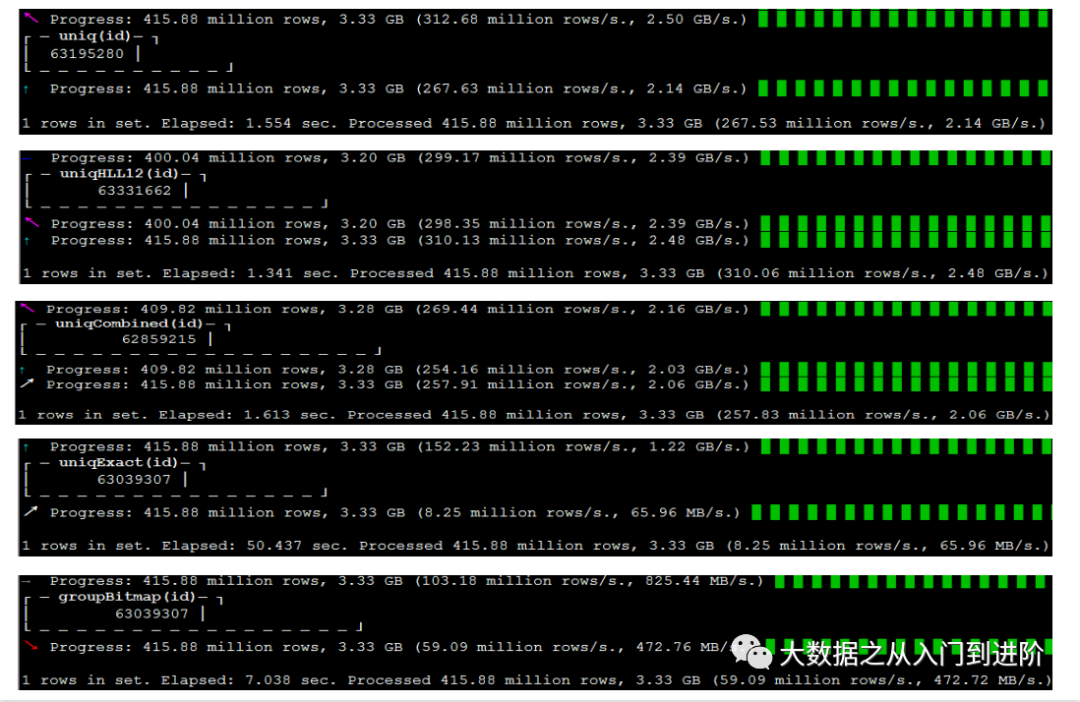
具体查询结果,如下图:
1.3.1 Clickhouse在苏宁使用场景:
OLAP平台存储引擎
存储时序数据、cube加速数据,应用于高基数查询、精确去重场景
运维监控
实时聚合分析监控数据,主要使用物化视图技术
用户画像场景
标签数据的存储、用户画像查询引擎
二、ClickHouse集成Bitmap
1、Bitmap位存储和位计算
2、RoaringBitmap原理介绍
3、ClickHouse集成RoaringBitmap
4、Bitmap应用示例
2.1.1 分布式MPP计算引擎:
每个bit位表示一个数字id,对亍40亿个的用户id,只需要40亿bit位,约477m大小 = (4 * 109 / 8 / 1024 / 1024)
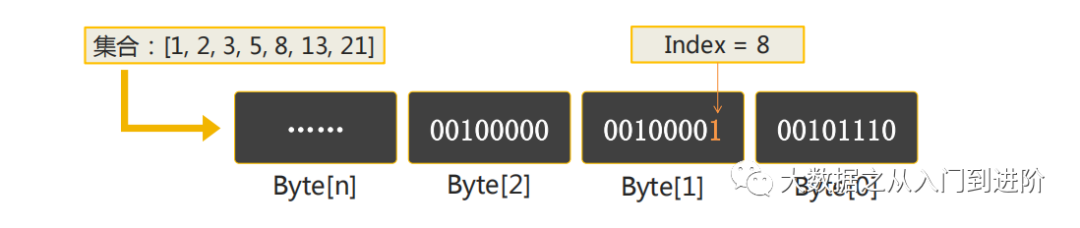
通过单个bitmap可以完成精确去重操作,通过多个bitmap的and、or、xor、andnot等位操作完成留存分析、漏斗分析、用户画像分析等场景的计算
但是如果使用上述的数据结构存储单独一个较大数值的数字id,会造成空间上的浪费,例如:仅存储40亿一个数值也需要477m的空间。也就是说稀疏的Bitmap和稠密的占用空间相同。通常会使用一种bitmap压缩算法迚行优化
RoaringBitmap是一种已被业界广泛使用的高效的bitmap压缩算法,使用者包括Spark、Hive、ElasticSearch、Kylin、Druid、InfluxDB等。详见:http://roaringbitmap.org/
2.2.1 RoaringBitmap原理介绍:
主要原理:将32bit的Integer划分为高16位和低16位(两个short int),两者之间是Key-Value的关系。高16位存到short[] keys,通过高16位(Key)找到所对应Container,然后把剩余的低16位(Value)放入该Container中,RoaringBitmap有三类Container:
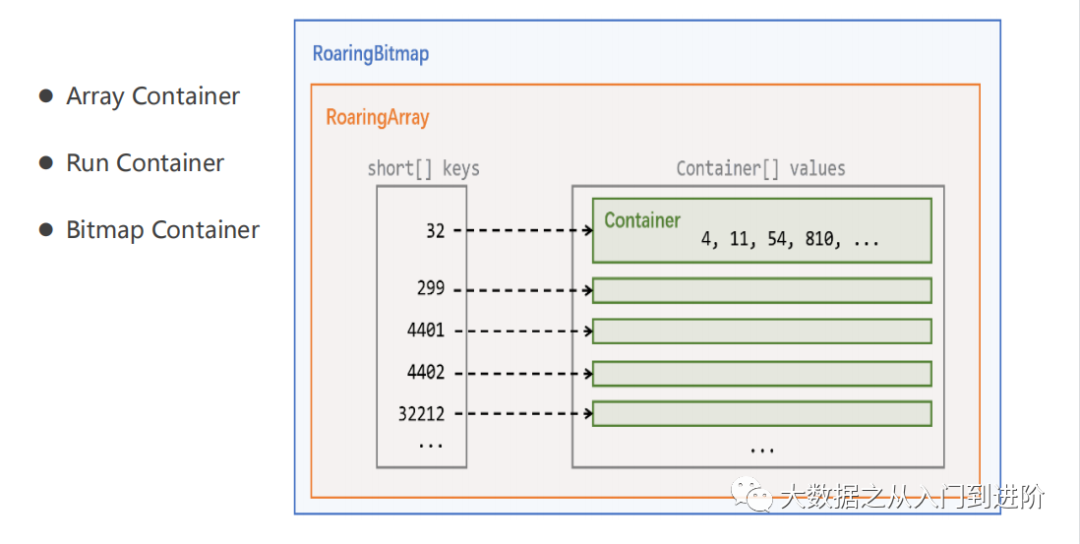

举个栗子:
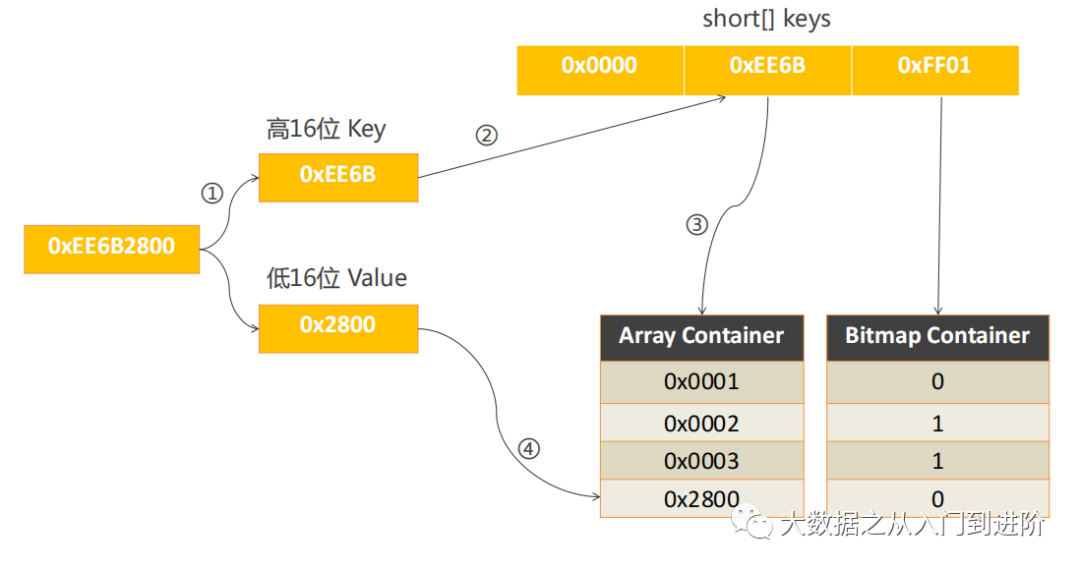
40亿(0xEE6B2800)这个值如何存入RoaringBitmap,以存入Array Container来说明:
2.3.1 ClickHouse集成RoaringBitmap:
Bitmap字段类型,该类型扩展自AggregateFunction类型,字段类型定义:
AggregateFunction( groupBitmap, UInt(8|16|32|64))
表示groupBitmap聚合函数的中间状态。可以通过groupBitmapState创建。
注:
lickHouse聚合函数有一些函数后缀可以使用:
State:获取聚合的中间计算结果
Merge:将中间计算结果进行合并计算,返回最终结果
MergeState:将中间计算结果进行合并计算,返回合并后的中间结果
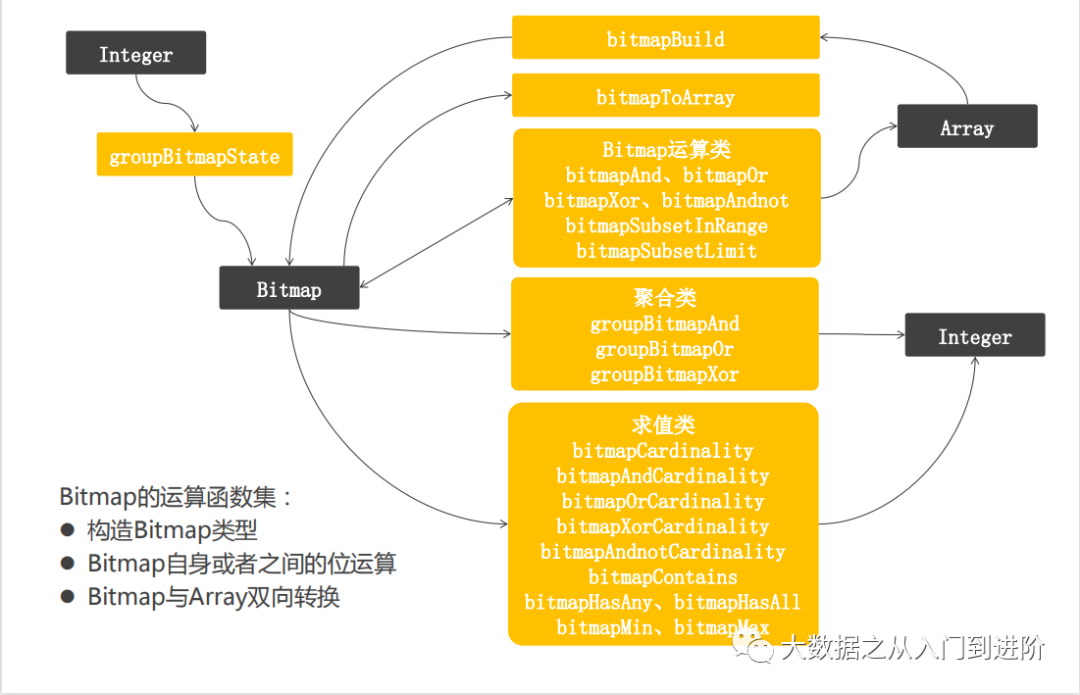
参考:
-
https:/
/clickhouse.yandex/docs
/en/data_types/nested_data_structures/aggregatefunction/
-
https:/
/clickhouse.yandex/docs
/en/query_language/agg_functions/reference/
#groupbitmap
2.4.1 Bitmap应用示例:
需求:一张简单的订单明细表 detail_order,如何计算用户的日留存?
| order_id | order_date | user_id | product_id |
| 1 | 2019-10-01 | 1 | p1 |
| 2 | 2019-10-01 | 1 | p2 |
| 3 | 2019-10-01 | 2 | p1 |
| 4 | 2019-10-01 | 3 | p1 |
| 5 | 2019-10-02 | 3 | p2 |
| 6 | 2019-10-02 | 4 | p1 |
| 7 | 2019-10-02 | 5 | p1 |
| 8 | 2019-10-02 | 5 | p2 |
标签SQL如下:
detail_order 聚合为天维度:
| order_date | uv_bitmap |
| 2019-10-01 | {1,2,3} |
| 2019-10-02 | {3,4,5} |
用户留存SQL,如下:
-
WITH
-
(
-
SELECT uv_bitmap
FROM uv_order
WHERE order_date
=
'2019-10-01'
-
)
AS day1,
-
(
-
SELECT uv_bitmap
FROM uv_order
WHERE order_date
=
'2019-10-01'
-
)
AS day2
-
SELECT bitmapAndCardinality(day1, day2)
AS retain_user;
注:千万级用户,秒级出结果
Bitmap函数:
留存用户:day1 AND day2 = [3]
全部用户:day1 OR day2 = [1,2,3,4,5]
新用户:day2 ANDNOT day1 = [4,5]
流失用户:day1 ANDNOT day2 = [1,2]
三、用户画像场景实践
1、用户画像原有的流程及痛点
2、ClickHouse替换ES存储标签数据
3、标签数据表定义
4、数据模型定义
5、用户画像系统常见应用场景
6、用户画像新架构的优势
3.1.1 用户画像原有的流程及痛点:
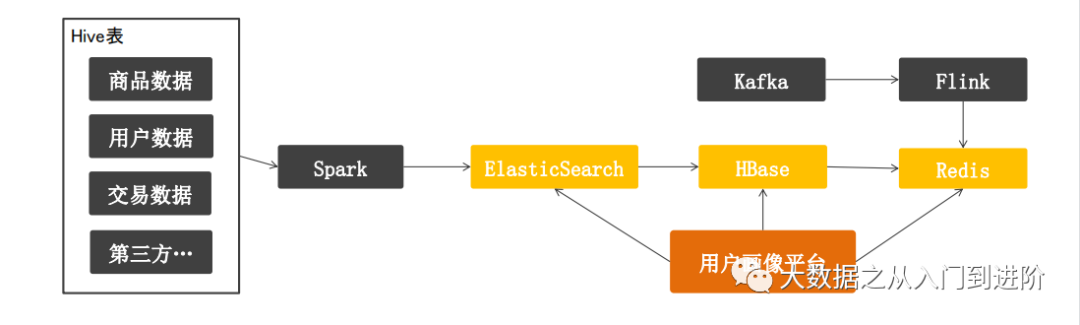
| 现有流程 | 痛点 |
1.ES中定义标签的大宽表 2.通过Spark关联各种业务数据,插入到ES大宽表 3.高频查询的画像数据通过后台任务保存到加速层:Hbase 或者 Redis 4.实时标签通过Flink计算,然后写入Redis 5.用户画像平台可以从ES、Hbase、Redis查询数据 | 1.标签导入到ES的时间过长,需要等待各种业务数据准备就绪,才能迚行关联查询 2.新增或者修改标签,不能实时运行,涉及到ES文档结构的变化 3.ES对资源消耗比较大,属于豪华型配置 4.ES的DSL语法对用户不太友好,用户学习成本较高 |
3.2.1 ClickHouse替换ES存储标签数据:
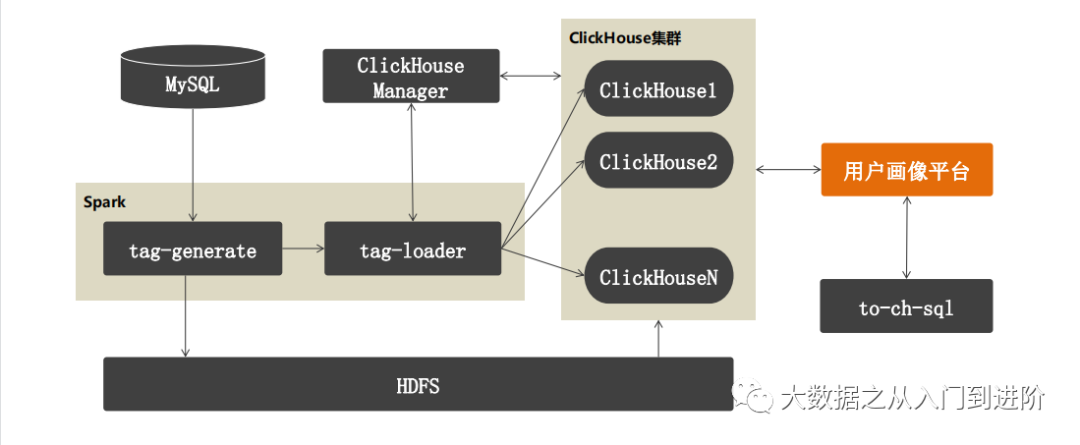
ClickHouse Manager负责ClickHouse集群管理、元数据管理以及节点负载协调
tag-generate负责标签数据构建,保存到HDFS(MySQL中存储标签配置信息)
tag-loader向ClickHouse发送从HDFS导入标签数据的sqlto-ch-sql模块,将用户画像查询条件转换为ClickHouse sql语句
用户画像平台通过Proxy从ClickHouse集群查询标签数据
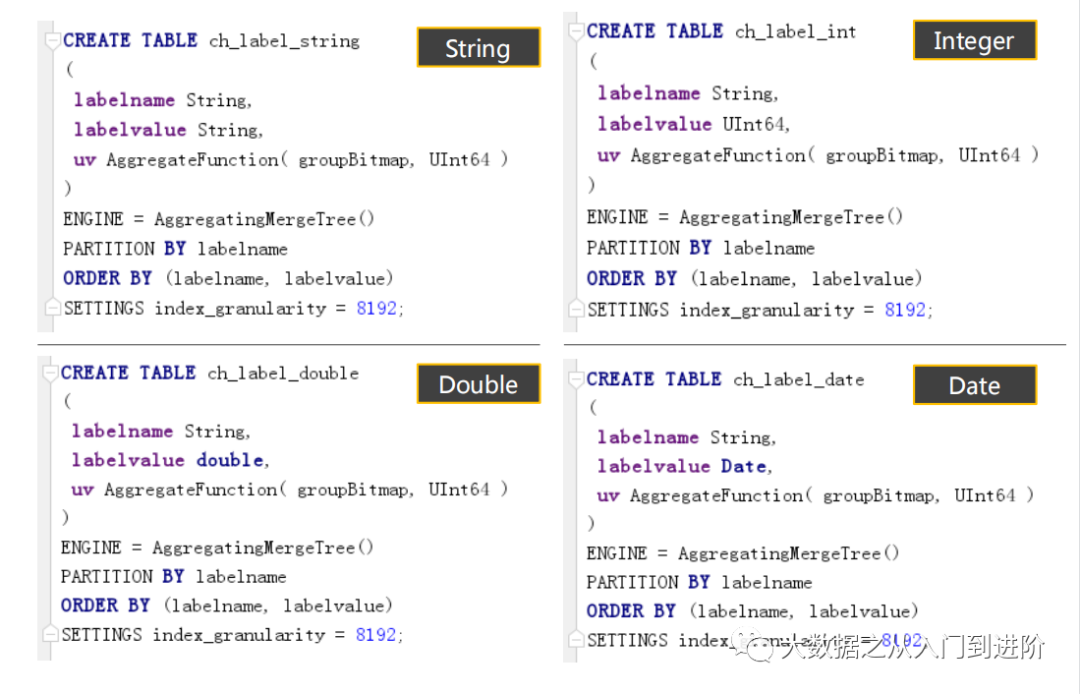
3.3.1 标签数据表定义:
3.4.1 数据模型定义:
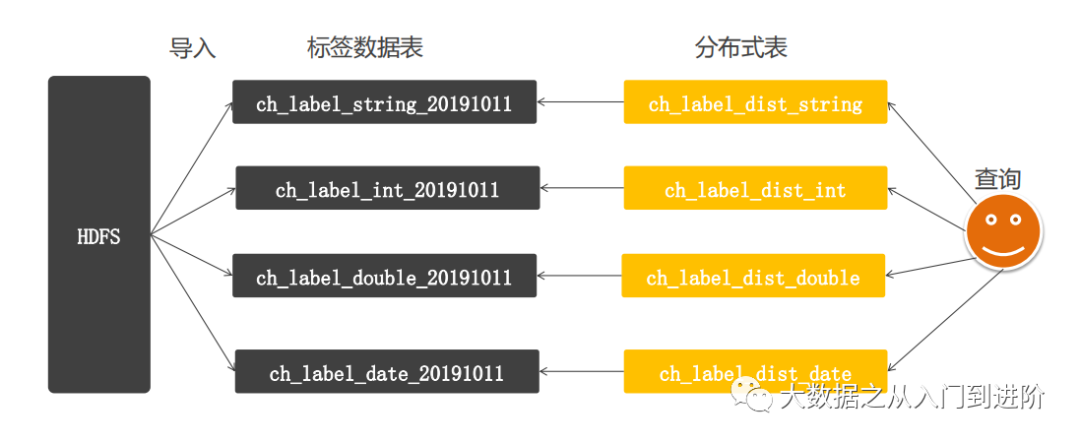
HDFS上采用snappy.parquet格式存储数据
采用AB表切换方式,避免查询和写入的冲突,标签数据表以日期结尾命名
通过重建分布式表迚行AB表切换,指向不同日期的标签数据表
通过增加标签数据表的副本数,提升开发性能
3.5.1 用户画像系统常见应用场景:
举个栗子:
"双11" 就要到了,需要发放10万张家电类优惠券迚行促销:

3.5.2 用户画像场景1—预估人数:
场景描述:
场景:限量发放10万张家电类优惠券,先预估出符合条件的
用户数
操作:用户指定标签及标签间的逻辑关系,统计出符合标签
逻辑的人数
输入条件:
标签表达式,包含标签、算术运算符、逻辑运算符、括号
返回结果:
整形值,表示符合标签表达式的用户人数
例如:
user_number
100000
示例:
画像条件:
gender = 'M' AND menber_level < 5 OR age IN (20, 25, 30)
查询SQL:
-
SELECT bitmap0rCardinality(bitmapAnd(users0, users1), users2)
AS user_number
-
FROM
-
(
-
SELECT
1
AS join_id, groupBitmapergeState(uv)
AS users0
-
FROM ch_label_dist_string
-
WHERE(labelname
=
'gender')
AND (labelvalue
= ’K’)
-
)
-
INNER
JOIN
-
(
-
SELECT
1
AS join_id, groupBitmapllergeState(uv)
AS usersl
-
FROM ch_label_dist_int
-
WHERE(labelname
=
'member_level')
AND (labelvalue
<
5)
-
)
ON join_id
= join_id
-
INNER
JOIN
-
(
-
SELECT
1
AS join_id, groupBitmaplergeState(uv)
AS users2
-
FROM ch_label_dist_int
-
WHERE(labelname
=
'age')
AND(labelvalue
IN (
20,
25,
30))
-
)
ON join_id
= join_id
3.5.3 用户画像场景2—人群圈选画像:
场景描述:
场景:对选出符合发优惠券条件的用户迚行画像分析,
人群特征分析
操作:用户指定标签及标签间的逻辑关系,查询出符合
标签逻辑的用户ID数据集,然后对数据集运行用
户画像分析。一条SQL完成人群圈选、用户画像
两个动作
输入条件:
标签逻辑表达式:标签、算术运算符、逻辑运算符、括号
返回结果:
查询出符合标签表达式的用户ID Bitmap对象,然后
将Bitmap对象不画像表迚行不(AND)操作,返回用
户画像信息
例如:
| label_name | label_value | user_number |
| gender | M | 12 |
| gender | F | 15 |
| age | 25 | 11 |
| age | 30 | 16 |
示例:
画像条件:
gender = 'M' AND menber_level < 5 OR age IN (20, 25, 30)
查询SQL:
-
SELECT labelname.labelvalues, bitmapAndCardinality(users, checkout_users)
AS user_number
-
FROM(
-
SELECT
1
AS join_id, labelname, labelvalue, groupBitmapMergeState(uv)
AS users
-
FROM ch_profiledist
-
GROUP
BY labelname, labelvalue
-
)
-
INNER
JOIN(
-
SELECT join_id, bitmap0r(bitmapAnd(users0users1),users2)
AS checkout_users
-
FROM(
-
SELECT
1
AS join_id groupBitmaplergeState(uv)
AS users0
-
FROM ch_label_single_dist_string
-
WHERE(labelname
=
'gender')
AND (labelvalue
=
'M')
-
INNER
JOIN(
-
SELECT
1
AS join_id, groupBitmapMergeState(uv)
AS usersl
-
FROM ch_label_single_dist_int
-
WHERE(labelname
=
'member_level')
AND (labelvalue
<
5)
-
)
ON join_id
= join_id
-
INNER
JOIN(
-
SELECT
1
AS join_id, groupBitmapergeState(uv)
AS users2
-
FROM ch_label_single_dist_int
-
WHERE(labelname
=
'age')
AND (labelvalueIN(
20,
25,
30))
-
)
ON joinid
=
join id)
-
)
ON join_id
= join_id ;
3.5.4 用户画像场景3—用户ID清单:
场景描述:
场景:在筛选出符合条件的用户数后,导出用户ID明细
,这样好给他们发优惠券
操作:用户指定标签及标签间的逻辑关系,查询出符合
标签逻辑的用户ID数据集
输入条件:
标签逻辑表达式:标签、算术运算符、逻辑运算符、括号
返回结果:
用户ID字段,表示符合标签表达式的用户ID集合。
例如:
user_list
8
10
11
12
示例:
画像条件:
gender = 'M' AND menber_level < 5 OR age IN (20, 25, 30)
查询SQL:
-
SELECT arrayJoin(bitmapToArray(bitmap0r(bitmapAnd(users0 users1) users2)))
AS user_list
-
FROM (
-
SELECT
1
AS
join id groupBitmaplergeState(uv)
AS users0
-
FROM ch_label_dist_string
-
WHERE(labelname
=
'gender')
AND(labelvalue
=
'M')
-
INNER
JOIN
-
(
-
SELECT
1
AS join_id, groupBitmapllergeState(uv)
AS usersl
-
FROM ch_label_dist_int
-
WHERE(labelnae
=
'member_level')
AND (labelvalue
<
5)
-
)
ON join_id
= join_id
-
INNER
JOIN
-
(
-
SELECT
1
AS join_id, groupBitmapllergeState(uv)
AS users2
-
FROM ch_label_dist_int
-
WHERE(labelname
=
'age')
AND (labelvalue
IN(
20,
25,
30))
-
)
ON join_id
=join_id
3.6.1 用户画像新架构的优势:

总结:
每个标签的数据可以幵行构建,加快标签数据生产速度
查询请求平均响应时长在2秒以下,复杂查询在10秒内
支持标签数据实时更新,增加标签、删除标签、修改标签
标签表达式和查询SQL对用户来说比较友好
相对于ElasticSearch的配置,可以节约一半硬件资源