word和excel是办公过程必不可少的两个文档类型,word多用于文字处理,比如备忘录、论文、书籍、报告、商业信函等,excel可以制作精美的图表,还可以计算、分析、记录数据。二者在功能达成上有重叠,工作过程中经常需要转换,如果内容少,还可以手动解决,但是一旦数据量庞大,靠手动,耗时费力不说,还很容易出现差错,今天以两个实例,教大家如何用Python实现word和excel之间的转换。
从Word到Excel
比如有这样一份Word文档

一共有近2600条类似格式的表格细栏,每个栏目包括的信息有:
- 日期
- 发文单位
- 文号
- 标题
- 签收栏
需要提取其中加粗的这三项内容到Excel表格中存储,表格样式如下:
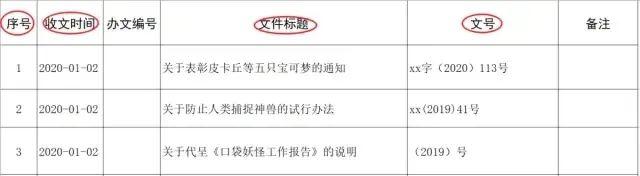
也就是需要将**收文时间、文件标题、文号填到指定位置,**同时需要将时间修改为标准格式,如果是完全手动复制和修改时间,依照一个条目10s的时间计算,一分钟可以完成6条,那么最快也需要:
2600/6=433.3(min)

而这类格式规整的文件整理非常适合用Python来执行,好的那么接下来请Python出场,必要的信息我在代码中以注释信息呈现。

首先使用Python将Word文件导入
导入需要的库docx
from docx import Document
指定文件存放的路径
path = r’C:\Users\word.docx’
读取文件
document = Document(path)
读取word中的所有表格
tables = document.tables

再把问题逐个划分
首先尝试获取第一张表第一个文件条目的三个所需信息
获取第一张表
table0 = tables[0]
仔细观察可以发现一个文件条目占据了3行,所以对表格全部行循环迭代时可以设步长为3

注意观察表格,按照row和cell把所需内容解析清楚
在全局放一个变量用来计数填序号
n = 0
for i in range(0, len(table0.rows) + 1, 3):
日期
date = table0.cell(i, 1).text
标题
title = table0.cell(i + 1, 1).text.strip()
文号
dfn = tables[j].cell(i, 3).text.strip()
print(n, date, tite, dfn)
接下来需要解决的是,时间我们获取的是 2/1 这种 日/月的形式。我们需要转化成 YYYY-MM-DD格式,而这利用到datetime包的strptime和strftime函数:
strptime: 解析字符串中蕴含的时间
strftime: 转化成所需的时间格式
import datetime
n = 0
for i in range(0, len(table0.rows) + 1, 3):
日期
date = table0.cell(i, 1).text
有的条目时间是空的,这里不做过多判别
if ‘/’ in date:
date= datetime.datetime.strptime(date, ‘%d/%m’).strftime(‘2020-%m-%d’)
else:
date = ‘-’
标题
title=table0.cell(i + 1, 1).text.strip()
文号
dfn = tables[j].cell(i, 3).text.strip()
print(n, date, tite, dfn)
这样一张表的内容解析就完成了,注意这里用的是table[0]即第一张表,**遍历所有的表加一个嵌套循环就可以,**另外也可以捕获异常增加程序灵活性
n = 0
for j in range(len(tables)):
for i in range(0, len(tables[j].rows)+1, 3):
try:
日期
date = tables[j].cell(i, 1).text
if ‘/’ in date:
date = datetime.datetime.strptime(date, ‘%d/%m’).strftime(‘2020-%m-%d’)
else:
date = ‘-’
标题
title = tables[j].cell(i + 1, 1).text.strip()
文号
dfn = tables[j].cell(i, 3).text.strip()
n += 1
print(n, date, title, dfn)
except Exception as error:
捕获异常,也可以用log写到日志里方便查看和管理
print(error)
continue
信息解析和获取完成就可以导出了,用到的包是openpyxl
from openpyxl import Workbook
实例化
wb = Workbook()
获取当前sheet
sheet = wb.active
设立表头
header = [‘序号’, ‘收文时间’, ‘办文编号’, ‘文件标题’, ‘文号’, ‘备注’]
sheet.append(header)
在最内层解析循环的末尾加上如下代码即可
row = [n, date, ’ ', title, dfn, ’ ']sheet.append(row)
线程的最后记得保存
wb.save(r’C:\Users\20200420.xlsx’)
运行时间在10分钟左右,大概离开了一会程序就执行结束了
代码很简单,理清思路最重要
从Excel到Word
我们再以一个案例来讲解如何**使用Python从Excel中计算、整理数据并写入Word中,**其实并不难,主要就是以下两步:
- openpyxl读取Excel获取内容
- docx读写Word文件

需求确认
首先来看下我们需要处理的Excel部分数据
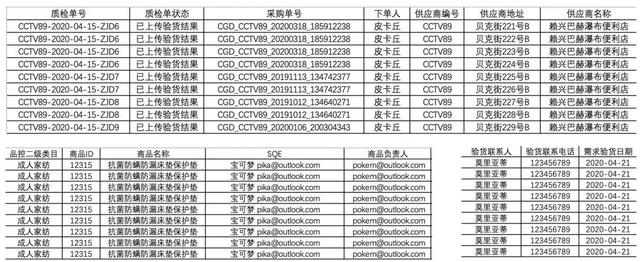
可以看到数据非常多,并且还存在重复数据。而我们要做的就是对每一列的数据**按照一定的规则进行计算、整理并使用Python自动填入到Word中,**大致的要求如下
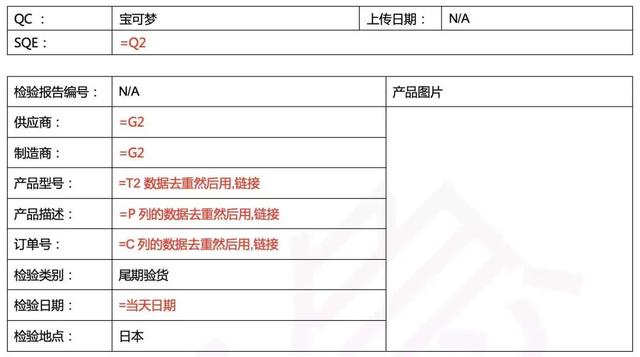
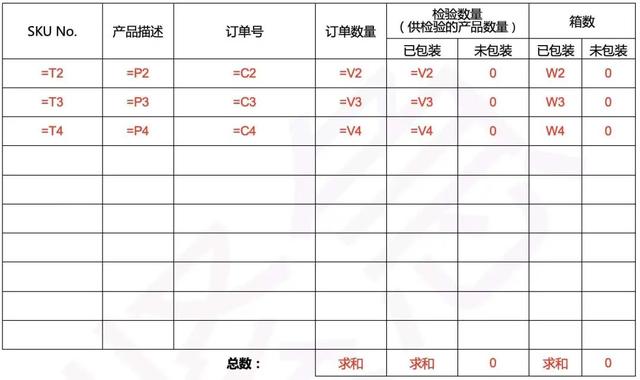
上面仅是部分要求,真实需要填入word中的数据要更多!
除了对按照格式进行处理并存入Word中指定位置之外,还有一个需求:最终输出的word文件名还需要按照一定规则生成:

OK,需求分析完毕,接下来看Python如何解决!

Python实现
首先我们使用Python对该Excel进行解析
from openpyxl import load_workbook
import os
获取桌面的路径
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), ‘Desktop’)
path = GetDesktopPath() + ‘/资料/’ # 形成文件夹的路径便后续重复使用
workbook = load_workbook(filename=path + ‘数据.xlsx’)
sheet = workbook.active # 获取当前页
可以用代码获取数据范围,如果要批处理循环迭代也方便
获取有数据范围
print(sheet.dimensions)
A1:W10
利用openpyxl读取单元格有以下几种用法
cells = sheet[‘A1:A4’] # 返回A1-A4的4个单元格
cells = sheet[‘A’] # 获取A列
cells = sheet[‘A:C’] # 获取A-C列
cells = sheet[5] # 获取第5行
注意如果是上述用cells获取返回的是嵌套元祖
for cell in cells:
print(cell[0].value) # 遍历cells依然需要取出元祖中元素才可以获取值
获取一个范围的所有cell
也可以用iter_col返回列
for row in sheet.iter_rows(min_row=1, max_row=3,min_col=2, max_col=4):
for cell in row:
print(cell.value)
明白了原理我们就可以解析获取Excel中的数据了
SQE
SQE = sheet[‘Q2’].value
供应商&制造商
supplier = sheet[‘G2’].value
采购单号
C2_10 = sheet[‘C2:C10’] # 返回cell.tuple对象
利用列表推导式后面同理
vC2_10 = [str(cell[0].value) for cell in C2_10]
用set简易去重后用,连接,填word表用
order_num = ‘,’.join(set(vC2_10))
用set简易去重后用&连接,word文件名命名使用
order_num_title = ‘&’.join(set(vC2_10))
产品型号
T2_10 = sheet[‘T2:T10’]
vT2_10 = [str(cell[0].value) for cell in T2_10]
ptype = ‘,’.join(set(vT2_10))
产品描述
P2_10 = sheet[‘P2:P10’]
vP2_10 = [str(cell[0].value) for cell in P2_10]
info = ‘,’.join(set(vP2_10))
info_title = ‘&’.join(set(vP2_10))
日期
用datetime库获取今日时间以及相应格式化
import datetime
today = datetime.datetime.today()
time = today.strftime(’%Y年%m月%d日’)
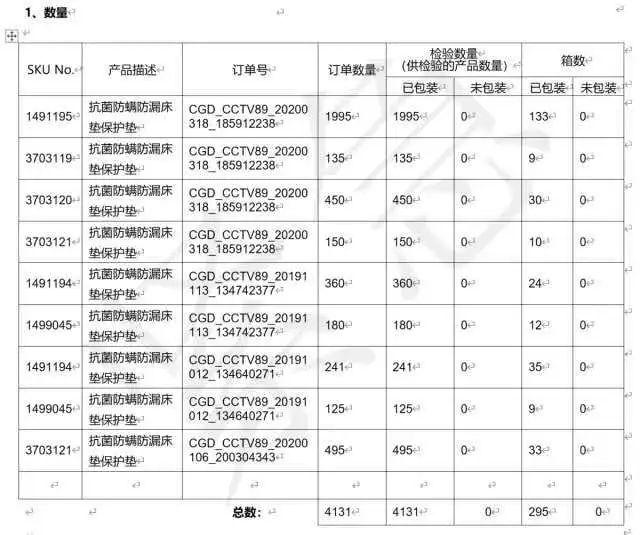
验货数量
V2_10 = sheet[‘V2:V10’]
vV2_10 = [int(cell[0].value) for cell in V2_10]
total_num = sum(vV2_10) # 计算总数量
验货箱数
W2_10 = sheet[‘W2:W10’]
vW2_10 = [int(cell[0].value) for cell in W2_10]
box_num = sum(vW2_10)
生成最终需要的word文件名
title = f’{order_num_title}-{supplier}-{total_num}-{info_title}-{time}-验货报告’
print(title)
通过上面的代码,我们就成功的从Excel中提取出来数据,这样Excel部分就结束了,接下来进行word的填表啦,由于这里我们默认读取的word是.docx格式的,实际上读者的需求是.doc格式文件,所以windows用户可以用如下代码批量转化doc,前提是安装好win32com
pip install pypiwin32
from win32com import client
docx_path = path + ‘模板.docx’
doc转docx的函数
def doc2docx(doc_path,docx_path):
word = client.Dispatch(“Word.Application”)
doc = word.Documents.Open(doc_path)
doc.SaveAs(docx_path, 16)
doc.Close()
word.Quit()
print(’\n doc文件已转换为docx \n’)
if not os.path.exists(docx_path):
doc2docx(docx_path[:-1], docx_path)
不过在Mac下暂时没有好的解决策略,如果有思路欢迎交流,好了有docx格式文件后我们继续操作Word部分
docx_path = path + ‘模板.docx’
from docx import Document
实例化
document = Document(docx_path)
读取word中的所有表格
tables = document.tables
print(len(tables))
15
确定好每个表格数后即可进行相应的填报操作,table的用法和openpyxl中非常类似,注意索引和原生python一样都是从0开始
tables[0].cell(1, 1).text = SQE
tables[1].cell(1, 1).text = supplier
tables[1].cell(2, 1).text = supplier
tables[1].cell(3, 1).text = ptype
tables[1].cell(4, 1).text = info
tables[1].cell(5, 1).text = order_num
tables[1].cell(7, 1).text = time
上面代码完成Word中这一部分表格

我们继续用Python填写下一个表格
for i in range(2, 11):
tables[6].cell(i, 0).text = str(sheet[f’T{i}’].value)
tables[6].cell(i, 1).text = str(sheet[f’P{i}’].value)
tables[6].cell(i, 2).text = str(sheet[f’C{i}’].value)
tables[6].cell(i, 4).text = str(sheet[f’V{i}’].value)
tables[6].cell(i, 5).text = str(sheet[f’V{i}’].value)
tables[6].cell(i, 6).text = ‘0’
tables[6].cell(i, 7).text = str(sheet[f’W{i}’].value)
tables[6].cell(i, 8).text = ‘0’
tables[6].cell(12, 4).text = str(total_num)
tables[6].cell(12, 5).text = str(total_num)
tables[6].cell(12, 7).text = str(box_num)
这里需要注意两个细节:
- word写入的数据需是字符串,所以从Excel获取的数据需要用str格式化
- 表格可能存在合并等其他情况,因此你看到的行数和列数可能不是真实的,需要用代码不断测试。
按照上面的办法,将之前从Excel中取出来的数据一一填充到Word中对应位置就大功告成!最后保存一下即可。
document.save(path + f’{title}.docx’)
print(’\n文件已生成’)
回顾上面的过程,其实从需求和文件格式上看,这次文件的读写解析任务较复杂,码代码和思考时间会较久,所以当我们在考虑使用Python进行办公自动化之前需要想清楚这个问题:**这次需要完成的任务是否工作量很多,或者以后长期需要进行,用Python是否可以解放双手?**如果不是,实际上手动就可以完成,那么就失去了自动化办公的意义!
如果你符合下面的情况中的任意一条,那我十分建议你加入跟着一起学习
1.准备从事编程工作,但是不知道选择什么语言好
2.只掌握了Python基础,缺乏系统性的学习以及企业级项目实战,达不到求职的能力
3.有一定Python基础,但是求职屡屡碰壁,各种问题频繁暴露,甚至怀疑自己不适合做开发
4.准备转行从事开发的同学
5.年满18即可
6.想利用Python副业月入3000-80000

****扫码二维码领取Python学习试学课程+课程咨询!
领取福利加小姐姐微信:python7762
免费领取学习+课程规划
