1. 冒泡排序Bubble sort
冒泡排序的算法思路在于对无序表进行多趟比较交换
每趟包括了多次两两相邻比较,并将逆序的数据项互换位置,最终能将本趟的最大项就位
经过n-1趟比较交换,实现整表排序
每趟的过程类似于“气泡”在水中不断上浮到水面的经过
第1趟比较交换,共有n-1对相邻数据进行比较,一旦经过最大项,则最大项会一路交换到达最后一项
第2趟比较交换时,最大项已经就位,需要排序的数据减少为n-1,共有n-2对相邻数据进行比较
第3趟比较 n-3 对数据
第n-1趟比较1对数据
直到第n-1趟完成后,最小项一定在列表首位,就无需再处理了。
冒泡排序第一趟
def bubbleSort(thelist):
for i in range(len(thelist) - 1): # 一共有n - 1趟对比
for j in range(len(thelist) - 1 - i): # 一趟对比n - i次
if thelist[j] > thelist[j + 1]:
temp = thelist[j]
thelist[j] = thelist[j + 1]
thelist[j + 1] = temp
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
bubbleSort(alist)
print(alist)
1.2 算法分析
一共对比n - 1趟
对比次数从n - 1 到 1次
对比的总次数是 1 + 2 +。。。 + n - 1 = 0.5n^2 - 0.5n
时间复杂度是O(n)
❖ 最好的情况是列表在排序前已经有序,交换次数为0
❖ 最差的情况是每次比对都要进行交换,交换次数等于比对次数
❖ 平均情况则是最差情况的一半
冒泡排序通常作为时间效率较差的排序算法,来作为其它算法的对比基准。
其效率主要差在每个数据项在找到其最终位置之前,必须要经过多次比对和交换,其中大部分的操作是无效的
但有一点优势,就是无需任何额外的存储空间开销
1.3 改进的冒泡排序
加入变量检测排序过程是否出现交换,如果没有发生交换,说明已经排好序了,就不需要再进行下一趟的操作了。这也是其它多数排序算法无法做到的。
def advancedBubbleSort(thelist):
stop = False
epoch = 0
while not stop and epoch < len(thelist) - 1:
stop = True # 如果下面没有发生交换,这里就停止了,说明排序完成
for i in range(len(thelist) - 1 - epoch):
if thelist[i] > thelist[i + 1]:
temp = thelist[i]
thelist[i] = thelist[i + 1]
thelist[i + 1] = temp
stop = False
epoch = epoch + 1
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
advancedBubbleSort(alist)
print(alist)
1.4 总结
简而言之,冒泡排序就是从头到尾,依次对两个数据值进行对比,每次选出该轮最大的数值。总共对比n-1轮。时间复杂度是O ( n 2 ) O(n^2)O(n2)
2. 选择排序Selection sort
选择排序对冒泡排序进行了改进,保留了其基本的多趟比对思路,每趟都使当前最大项就位。
但选择排序对交换进行了削减,相比起冒泡排序进行多次交换,每趟仅进行1次交换,记录最大项的所在位置,最后再跟本趟最后一项交换,即只对比数据找出最大值,将最大值与最后一个位置的数值交换。
选择排序的时间复杂度比冒泡排序稍优
比对次数不变,还是O ( n 2 ) O(n^2)O(n2)
交换次数则减少为O ( n ) O(n)O(n)

def selectionSort(thelist):
for fillslot in range(len(thelist) - 1, 0, -1): # 共比较n - 1 轮, range函数(a, b, c) a是开始,b是结束,c是步长
maxpostion = 0
for i in range(1, fillslot + 1): # 每轮比较n - i 对数据
if thelist[i] > thelist[maxpostion]:
maxpostion = i # 找到这一轮的最大值的位置
temp = thelist[fillslot]
thelist[fillslot] = thelist[maxpostion]
thelist[maxpostion] = temp
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
selectionSort(alist)
print(alist)
3. 插入排序Insertion Sort
插入排序维持一个已排好序的子列表,其位置始终在列表的前部,然后逐步扩大这个子列表直到全表
3.1 算法流程
第1趟,子列表仅包含第1个数据项,将第2个数据项作为“新项”插入到子列表的合适位置中,这样已排序的子列表就包含了2个数据项
第2趟,再继续将第3个数据项跟前2个数据项比对,并移动比自身大的数据项,空出位置来,以便加入到子列表中
经过n-1趟比对和插入,子列表扩展到全表,排序完成


def insertionSort(thelist):
for i in range(len(thelist) - 1):
newdata = thelist[i + 1]
j = i
while j >= 0 and newdata < thelist[j]:
thelist[j + 1] = thelist[j]
thelist[j] = newdata
j = j - 1
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
insertionSort(alist)
print(alist)
3.2 算法分析
插入排序的比对主要用来寻找“新项”的插入位置
最差情况是每趟都与子列表中所有项进行比对,总比对次数与冒泡排序相同,数量级仍是O ( n 2 ) O(n^2)O(n2)
最好情况,列表已经排好序的时候,每趟仅需1次比对,总次数是O(n)
4. 希尔排序Shell Sort
插入排序的比对次数,在最好的情况下是O(n),这种情况发生在列表已是有序的情况
下,实际上,列表越接近有序,插入排序的比对次数就越少
从这个情况入手,谢尔排序以插入排序作为基础,对无序表进行“间隔”划分子列表,每个子列表都执行插入排序

随着子列表的数量越来越少,无序表的整体越来越接近有序,从而减少整体排序的比对次数
间隔为3的子列表,子列表分别插入排序后的整体状况更接近有序
最后一趟是标准的插入排序,但由于前面几趟已经将列表处理到接近有序,这一趟仅需少数几次移动即可完成

代码思路:
子列表的间隔一般从n/2开始,每趟倍增:n/4, n/8……直到1
这个图更好理解:
算法分析:
谢尔排序以插入排序为基础,可能并不会比插入排序好。但由于每趟都使得列表更加接近有序,这过程会减少很多原先需要的“无效”比对
对谢尔排序的详尽分析比较复杂,大致说是介于O(n)和O(n2)之间
如果将间隔保持在2k-1(1、3、5、7、15、31等等),谢尔排序的时间复杂度约为O ( n 3 / 2 ) O(n^{3/2})O(n3/2)
5. 归并排序
5.1 算法
归并排序是递归算法
将数据的分裂为两半,对每一半继续进行进行归并排序
递归结束条件:只剩下一个数据表中只剩一个元素
缩小规模:数据表分裂为两半,每次规模减小为原来一半
调用自身:分裂后的两半,调用自身排序,继续对两半进行归并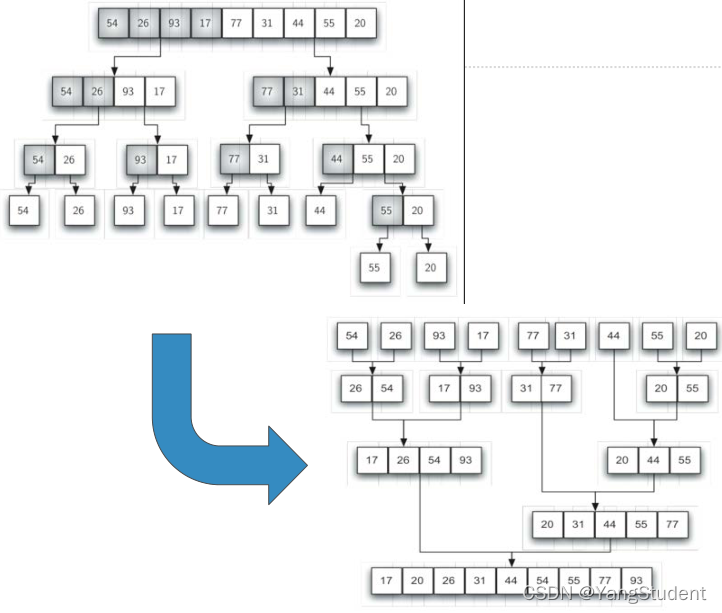
5.2 代码
def merge_sort(lst):
# 递归结束条件
if len(lst) <= 1:
return lst
# 分解问题,每次划分为原来的一半
mid = len(lst) // 2 # 中间点
left = merge_sort(lst[: mid]) # 左半边归并
right = merge_sort(lst[mid: ]) # 右半边归并
# 合并左右半部,完成排序
merged = []
while left and right:
if left[0] <= right[0]:
merged.append(left.pop[0])
else:
merged.append(right.pop(0))
merged.extend(right if right else left) # 把剩下的那半边一次性合并进去
return merged
5.3 算法分析
分裂的过程,类似二分查找法,是 O(logn)
合并的过程,每次进行一次比较和防止,是O(n)
总的复杂度是O(nlogn)
归并排序算法使用了额外1倍的存储空间用于归并
6. 堆排序
图解排序算法(三)之堆排序这篇文章讲的很好,直接看这个就行了
7. 快速排序
六大排序算法:插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序
这篇文章讲的不错。
Python 版本的代码
def quick_sort(nums: list, left: int, right: int) -> None:
if left < right:
i = left
j = right
# 取第一个元素为枢轴量
pivot = nums[left]
while i != j:
# 交替扫描和交换
# 从右往左找到第一个比枢轴量小的元素,交换位置
while j > i and nums[j] > pivot:
j -= 1
if j > i:
# 如果找到了,进行元素交换
nums[i] = nums[j]
i += 1
# 从左往右找到第一个比枢轴量大的元素,交换位置
while i < j and nums[i] < pivot:
i += 1
if i < j:
nums[j] = nums[i]
j -= 1
# 至此完成一趟快速排序,枢轴量的位置已经确定好了,就在i位置上(i和j)值相等
nums[i] = pivot
# 以i为枢轴进行子序列元素交换
quick_sort(nums, left, i-1)
quick_sort(nums, i+1, right)
如果分裂总能把数据表分为相等的两部分,那么就是O(log n)的复杂度;
而移动需要将每项都与中值进行比对,还是O(n)
综合起来就是O(nlog n)
而且快排不需要额外的存储开销
如果不那么幸运的话,中值所在的分裂点过于偏离中部,造成左右两部分数
量不平衡极端情况,有一部分始终没有数据,这样时间复杂度就退化到O ( n 2 ) O(n^2)O(n2)
7. 各种排序算法对比

参考文献
本文的知识来源于B站视频 【慕课+课堂实录】数据结构与算法Python版-北京大学-陈斌-字幕校对-【完结!】,是对陈斌老师课程的复习总结。