实现对B站异步加载的数据爬取
1.爬取目标的url
url=“https://www.bilibili.com/anime/index/#st=1&order=2&season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&sort=0&page=1”
2.是否是异步加载的,判断方式有很多,这里随便说1种。检查网页源码,查找想要的数据,看是否有,如果没有就是异步加载
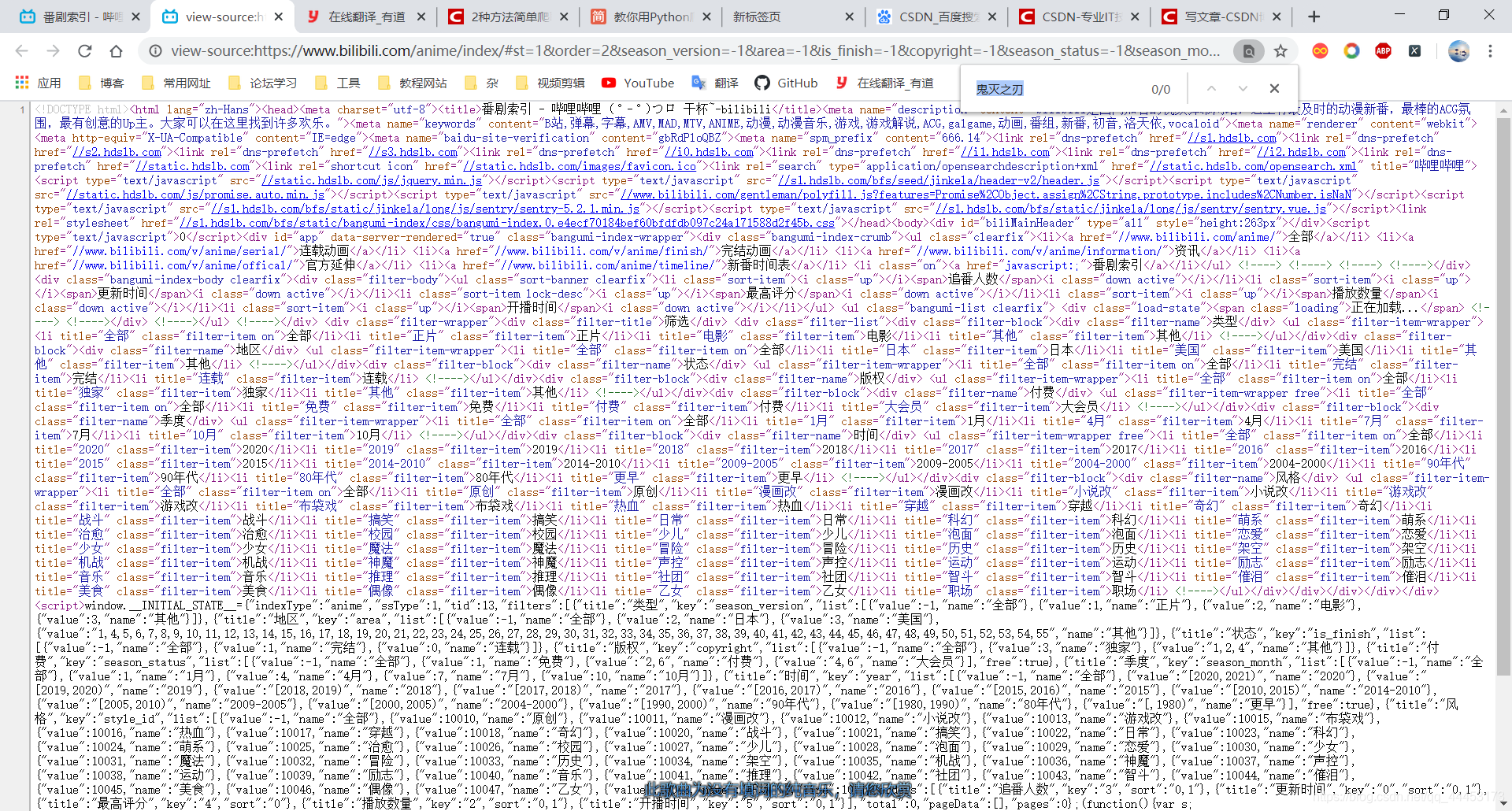
这里没找到,可以判定时异步加载
3.找到真正的请求网页,通过在Network的Search里面搜索想要的数据,得到真正的url
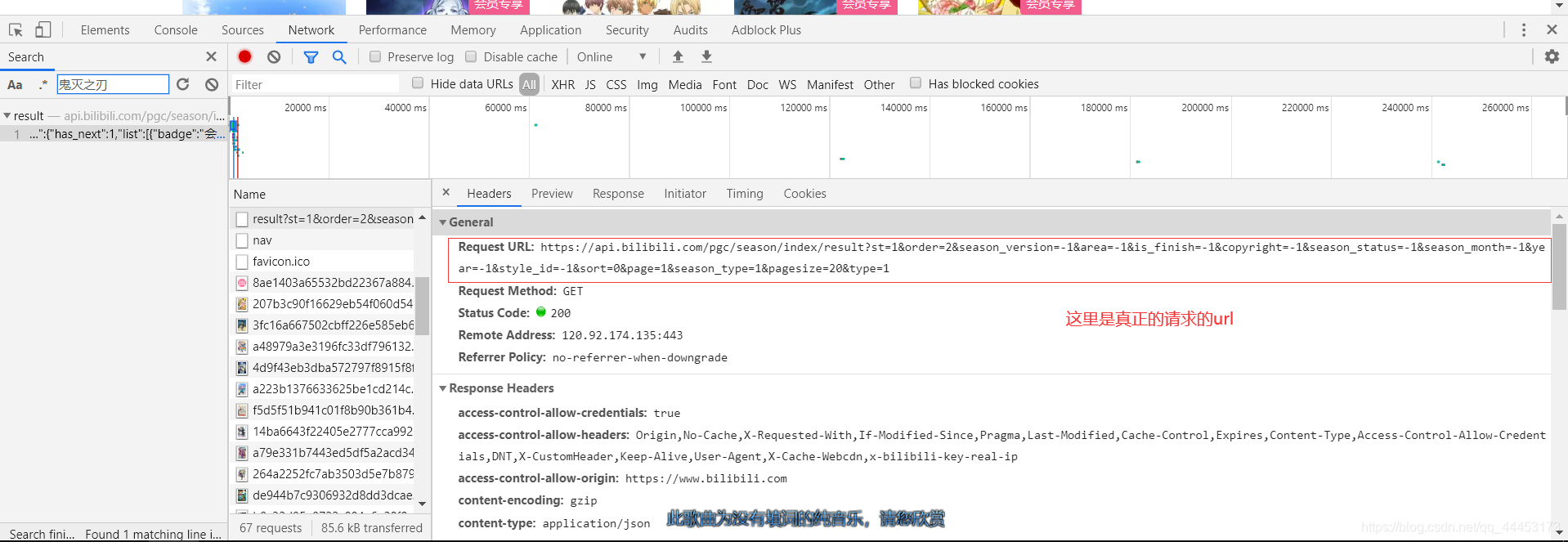
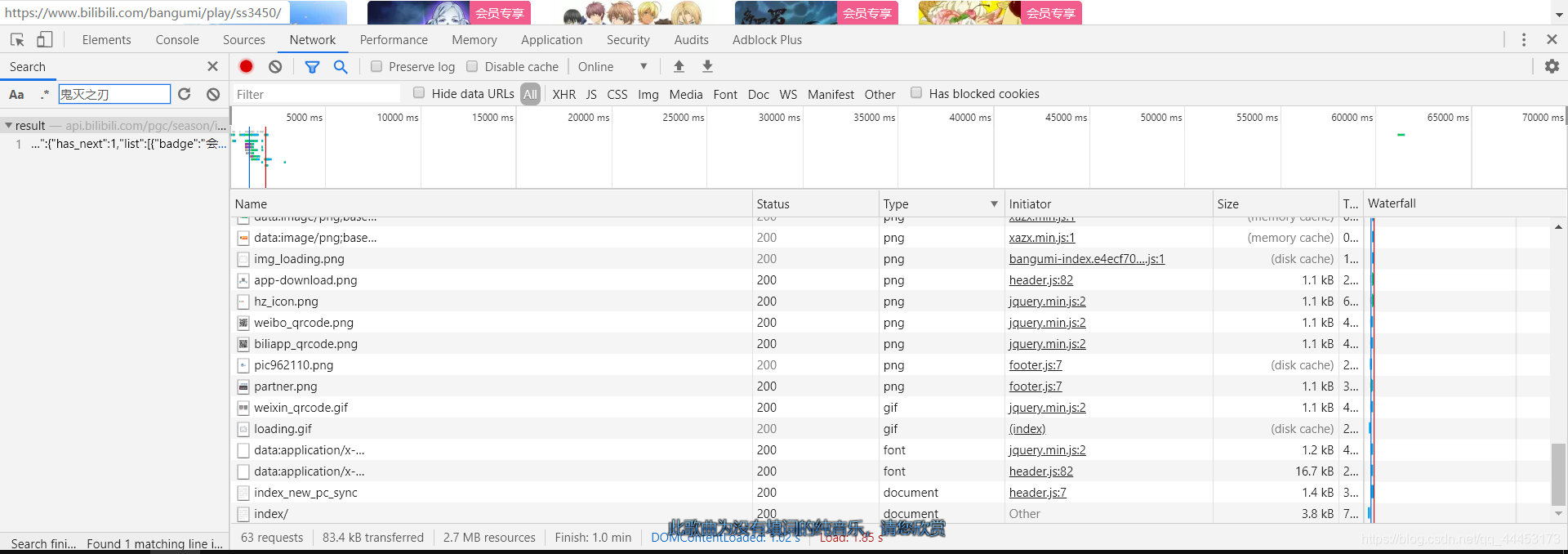
4.解析Preview(也就是json)的数据
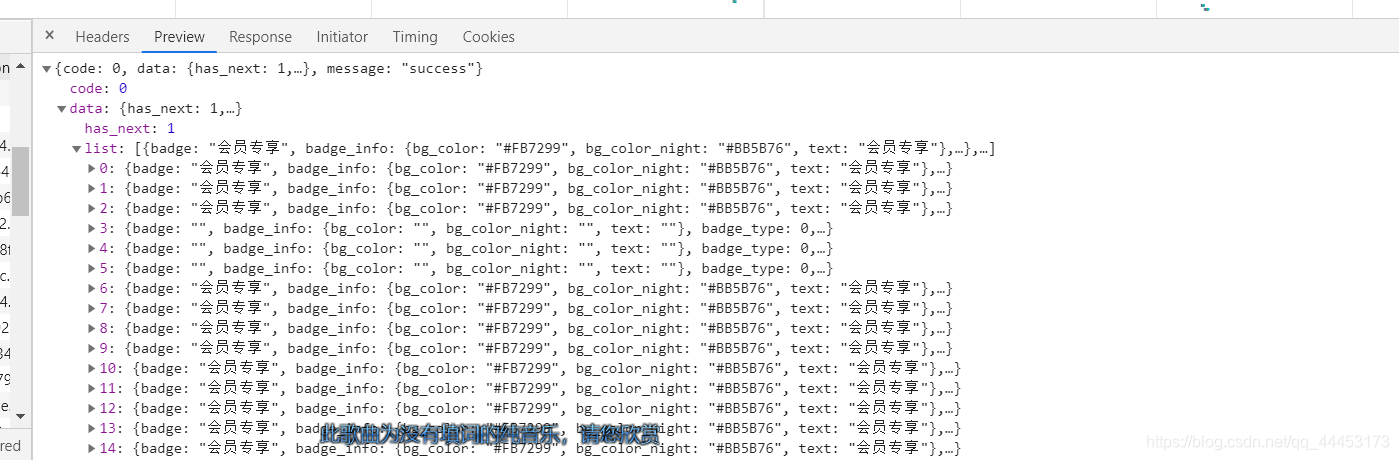
这里可以获取我们想要的数据
5.用xls表格保存数据
好,我们开始写代码
import xlwt
import requests
# 功能:实现B站番剧排名的爬取
def main():
datalist = askUrl()
saveData(datalist) # 保存数据
def askUrl():
url = "https://api.bilibili.com/pgc/season/index/result"
headers = {
"User - Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
}
datalist = []
for page in range(1,157):
params = {
'st': '1',
'order': '2',
'season_version': '-1',
'area': '-1',
'is_finish': '-1',
'copyright': '-1',
'season_status': '-1',
'season_month': '-1',
'year': '-1',
'style_id': '-1',
'sort': '0',
'page': str(page),
'season_type': '1',
'pagesize': '20',
'type': '1',
}
response = requests.get(url, params=params, headers=headers)
html = response.json()
data = html["data"]["list"] # 数据位置
for anime in data:
data = []
title = anime["title"] # 番剧名字
data.append(title)
episode = anime["index_show"] # 番剧集数
data.append(episode)
link = anime["link"] # 番剧链接
data.append(link)
playVolume = anime["order"] # 番剧播放量
data.append(playVolume)
ifVip = anime["badge"] # 是否会员专享
if ifVip == "":
data.append("不是会员专享")
else:
data.append(ifVip)
datalist.append(data) # y一部番剧的所有信息
print("第%d页已爬取完毕!"%page)
return datalist
def saveData(datalist):
savepath = "B站番剧排名.xls" #表格路径
workbook = xlwt.Workbook(encoding="utf-8") # 创建workbook对象
# 创建一个worksheet对象,第二个参数是指单元格是否允许重设置,默认为False
worksheet = workbook.add_sheet(savepath,cell_overwrite_ok=True) # 创建工作表
col = ("番剧名字","番剧集数","番剧链接","番剧播放量","番剧是否会员专享")
for i in range(0,5):
# 设置列宽,计算列宽度:256是单元格基数*用数据长度*2最终的结果单元格的宽度和数据正好填满
# worksheet.col(i).width = 256 * len(col[i]) * 2 # 自适应列宽
worksheet.write(0,i,col[i]) # 第一行的数据(列名)
for i in range(0,3119): # 第几行
data = datalist[i]
for j in range(0,5): # 第几列
worksheet.write(i+1,j,data[j])
workbook.save(savepath)
if __name__ == '__main__':
main()
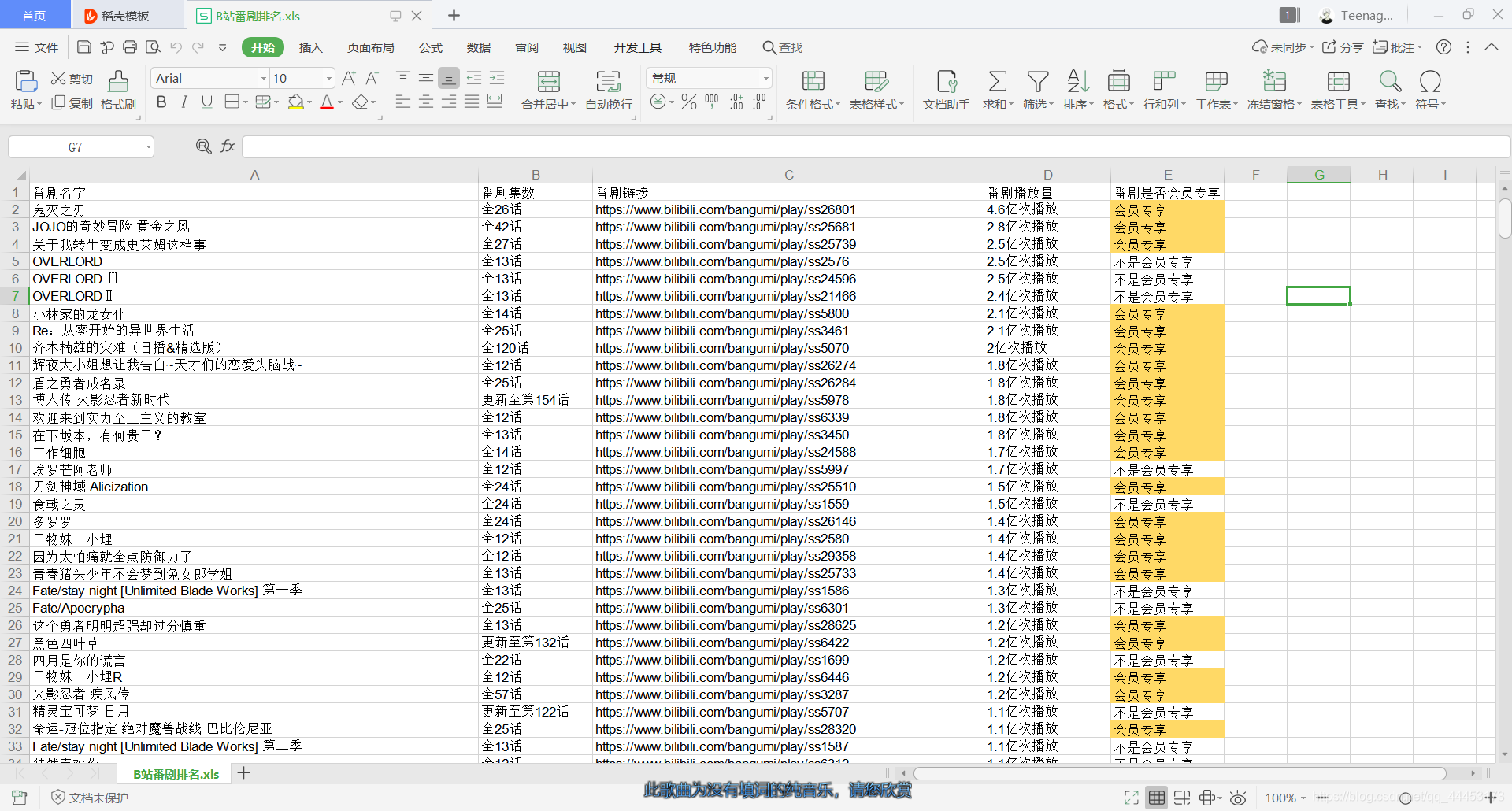
最后得到我们想要的数据
版权声明:本文为qq_44453173原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。