为什么需要神经网络
在回答这个问题之前,先回顾下:
为什么需要logistic regression,linear regression可以完全取代logistic regression吗?
logistic regression本质就是一个线性分类器,(第三讲logistic regression中 ng有提到lr的decision boundary, 其表达形式就是个linear regression)只不过是对输出结果做了sigmoid变换, so linear regression完全可以取代logistic regression?
按照ng的解释, 之所以需要神经网络,是因为简单的线性分类器linear regression和lr在面临以下两个挑战时存在问题
- 分界面为非线性分界面
- 特征数量非常多
这两个挑战在实际应用中往往是并存的,比如图像处理任务,一张图片的像素矩阵表达可能存在成千上万个特征,其分界面通常也不是简单的线性关系。如果用logistic regression来解决图像分类的问题,为了拟合非线性分解面,通常需要将特征做交叉或者多项式组合等处理,即使是简单的两两组合,其特征组合也有Cn2个, 当n较大时特征组合爆炸,通常会导致两个问题: 1.过拟合 2.计算过于耗时。所以需要用神经网络来处理。
神经网络的intuition
在这节中,n.g举了一个非常生动的例子说明为神经网络的intution:
考虑一个简单的分类任务: x1 xnor x2(即not xor), 其取值与值域的映射为:
- 0 0 -> 1
- 0 1 -> 0
- 1 0 -> 0
- 1 1 -> 1
将xnor画在坐标轴上法容易发现其不是线性可分的,因此无法用简单的linear regression或者logstic regression对其进行学习。但是在神经网络中,通过引入一层隐藏层就可以解决其线性不可分的问题。具体做法是:
将两个基础的线性可分的分类器x1 and x2 和 (not x1) and (not x2)作为隐藏层,记两个分类器分别为1,2。 1,2的映射关系分别为:
分类器1 x1 and x2 :
- 0 0 -> 0
- 0 1 -> 0
- 1 0 -> 0
- 1 1 -> 1
分类器2 (not x1) and (not x2) :
- 0 0 -> 1
- 0 1 -> 0
- 1 0 -> 0
- 1 1 -> 0
然后再将分类器3: x1 or x2 作为输出层, 分类器1和2作为3的输入:
- 0 0 -> 0
- 0 1 -> 1
- 1 0 -> 1
- 1 1 -> 1
不难看出最终得到的分类结果就是我们所预期的XNOR的效果。
所以,简单概括,神经网络的intuition就是用一堆简单线性分类器(比如logstic regression)的组合,超越单个简单线性分类器,从而解决非线性可分的分类问题。
神经网络的推导过程
疑问一: ng的课件里,最后一层的误差直接等于 输出值-预测值, 但是根据定义应该等于 (输出值-预测值)*激活函数的偏导数。
神经网络的求偏导数 本质上是个 链式法则+动态规划的过程。
所谓链式法则,就是为了求解某些直接求偏导比较麻烦的自变量的偏导数,可以借助中间变量,具体可以参考多元复合函数的求导法则。链式法则决定了可以用动态规划算法求解,中间变量(即误差)可以理解为动态规划的中间解。
有一篇比较好的神经网络链式求导法则的描述:
链式求导法则的形象描述
具体推导
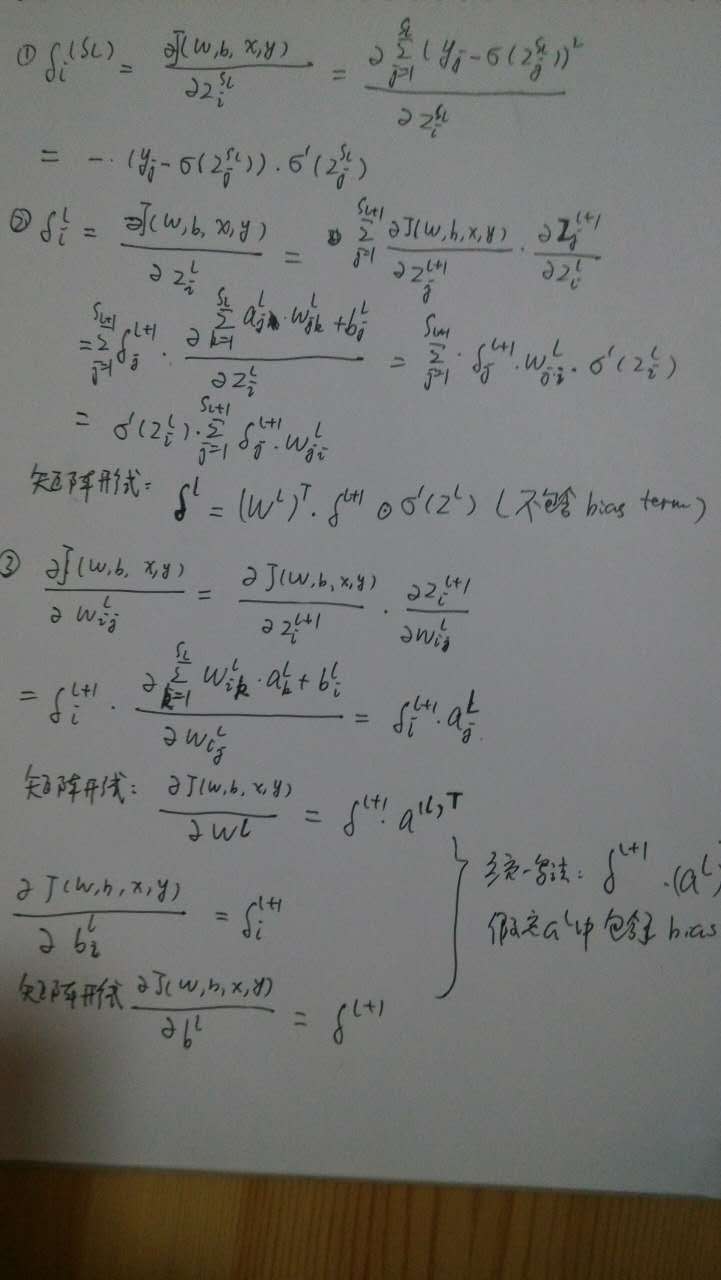
神经网络的优化技巧
梯度检查
因为神经网络的求解梯度算法复杂,为了确保求解正确,可使用梯度检查方法,在大规模train之前使用。 具体做法为使用J(theta+epsilon) - J(theta - epsilon)/ (2 * epsilon) 和J在theta处的梯度进行比较,若相近说明求导正确
随机初始化
logistic regression的cost function是个凸函数,因此从任意初值出发都可以找到最优解。但是神经网络的cost function是非凸的,不难证明,如果从随机初值出发,将导致在每一轮梯度下降之后,神经网络的每一层隐藏层节点的激活值都相等,相当于每一层只有一个feature。(此处需要好好理解)
正确的做法是,对每一层的初始值,在[-epsilon, +epsilon]范围内随机