YOLO学习笔记
一、YOLO-V1
针对对FasterR-CNN改进,取消了区域建议,为一阶段目标检测。
1、YOLO-V1网络结构分析:
(1)Backbone:GoogLeNet
(2)Neck:None
(3)Head:YOLO (fc(1570)到77(5*2+20))
2、YOLO-V1输出分析:
全卷积网络输出深度为30(5+5+20,两个预测框,20种分类)。V1为直接对目标中心位置进行预测。
3、Loss函数: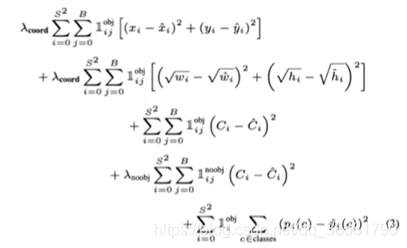
Loss由三部分组成:预测框几何loss+预测框置信度loss+目标分类loss。利用重合度(IOU)完成聚类,判断两个框里的是不是一个目标。
4、存在问题:
其优点是速度快,但与R-CNN系列的检测算法相比,V1的预测框不够准。
二、YOLO-V2:
1、YOLO-V2网络结构分析:
Backbone:darknet19
Neck:None
Head:passthrough (conv到13* 13* anchor* (5+20))
2、基于预测准确度的改进
基于V1版本,分析V1预测准确度不如R-CNN系列的原因:R-CNN为基于anchor预测偏移量。
对于同一数据集的实验:
上图通过实验在V1的基础上加以探索,从而确定V2的框架。V2开始,对于目标的预测皆对目标的偏移量进行预测。
3、基于预测全面性的改进
主要原因为V1仅用了单尺度检测器,改进方法1、将输入图片的尺寸加大;2、Passthrough技术:引入多尺度,用以改善对小目标的检测;3、对于多个尺度图片的训练;4、特征提取结束后的推理时,图片也加大,保证多尺度训练效果。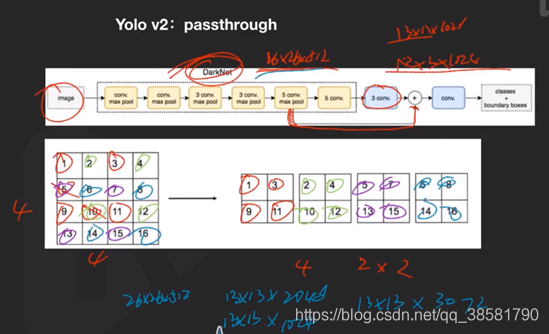
4、基于特征提取网络的改进
针对检测任务V2训练了Dark-Net19网络,用以取代Google-Net,该网络在每层操作后加bn(batch norm),在标准化后引入非线性操作。
Dark-Net19网络结构组成图: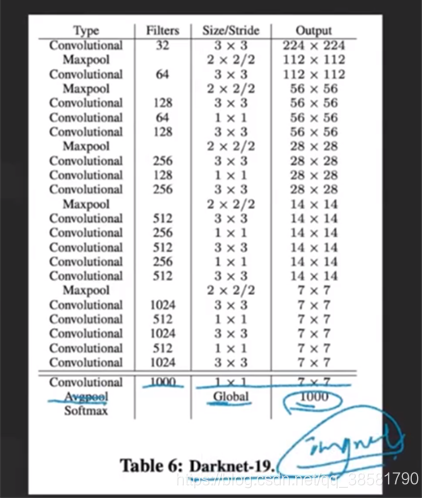
5、YOLO-V2输出分析
anchor*(5+20),对于每个框都框预测一个位置、一个分类。
存在问题:
对小目标的检测效果很差

三、YOLO-V3:
1、YOLO-V3网络结构分析:
Backbone:darknet53
Neck:None
Head:YOLOV3(conv1到1313anchor/3*(5+classes)
Conv2到2626anchor/3*(5+classes)
Conv3到5252anchor/3*(5+classes))
2、基于对于小目标检测问题的改进:
利用多检测头,总三类检测头,分别争对(大/中/小)目标。
3、基于特征提取网络的改进:
从YOLO-V2的darknet19升级到YOLO-V3的darknet53
4、YOLO-V3结构框图: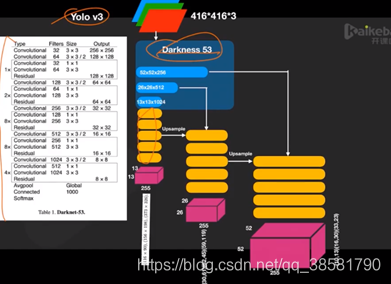
5、YOLO-V3输出分析:
3输出深度3(5+classes)。三种检测头,每种检测头3各3检测框,每个框预测一个位置、一个种类。
四、YOLO-V4:
1、YOLO-V4网络结构分析
Backbone:CSPDarknet53
Neck:SPP,PAN
Head:YOLO-V3
2、对于特征提取网络的改进:
将YOLO-V3的Darknet53改进成CSPDarknet53。其主要是对于网络中激活函数的替换,使用Mash激活函数:Mish=x * tanh(ln(1+e^x)),其曲线如下图
3、关于Neck层的改进
增添了SPP和PAN模块,其中SPP是为了增大网络的感受野,PAN可以争对不同级别的检测器从不同骨干层中挑选最佳的参数聚合
4、YOLO-V4网络结构图:
(学习 明明老师 YOLO公开课学习笔记,部分内容引自上课内容)